标签:小议 Layer 架构 Batch Kappa View 数据 Lambda
首先我们来看看什么是Lambda架构,Lambda演算在编程语言之中是一个编程范式,它遵循如下几个特点:
数据的不可变性,任何对于数据的操作是没有副作用。
数据的无依赖性,即对函数提供同样的输入,那么函数总是返回同样的结果。
函数是First Class,函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
来自Twitter的Nathan Marz,Marz认为进行计算处理的大数据框架的本质逻辑与函数式编程的思路是不谋而合,所以Marz根据自己多年进行分布式数据系统开发的经验总结提出了Lambda架构。(Marz大神是AFS顶级项目Storm的作者,Storm作为一个优秀的分布式流处理系统)所以接下来我们来看看Marz所提出的Lambda架构是怎么样:
Lambda架构说起来也很简单,就是通过分布式系统的组件搭建,设计出一个具有鲁棒性,可扩展,低延时的分布式计算系统。之所以称之为Lambda架构,就是它最为核心的点就是理由了数据处理过程之中的不可变性与无依赖性。下图展现了一个典型的Lambda架构的分层逻辑: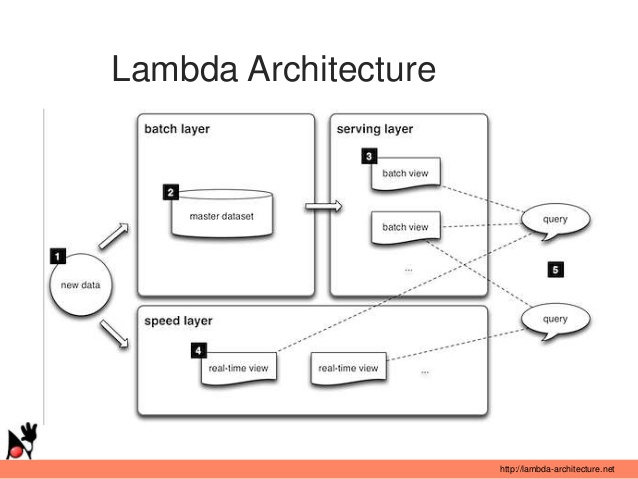
由上图可以看到,一个典型的Lambda架构的核心分为三个层次:Batch Layer,Speed Layer和Serving Layer。
Batch Layer
Speed Layer
Serving Layer
我们来梳理一下他们是如何分工协助的:首先new data作为整个数据系统的数据源头,Batch Layer作为数据的批处理层次对原始数据进行加工与处理,并且将处理的数据结果的Batch View输入到Serving Layer。(这里对应的是全量数据)
Speed Layer对于实时增加的数据进行处理,生成对增量数据计算结果的Realtime Views。(这里对应的是增量数据)
最终用户查询是通过Batch View与Realtime View相结合的形式将最终结果呈现出来。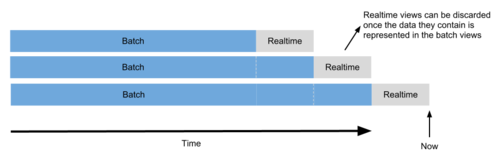
并且随着时间的推移,Batch View的计算结果会逐渐替代Realtime View,而业务层可以低延迟的访问由Serving Layer提供的Batch View,也可以通过Realtime View实时反馈业务结果。
我们可以看到在Lambda架构之中,所有的数据都需要满足满足不可变性与无依赖性,出现任何数据问题时,(如出错,丢失等)只需要重新跑一遍算法就可以恢复所需的数据了。
下面笔者利用一个业务场景简单阐述一下Lambda模式,如下的业务场景只是基于笔者对电商推荐的理解所表述的,对应电商未必实际之中就是采取笔者所阐述的模式:
1:下图是笔者访问x宝网首页所展示的广告页面:
对于这个推荐数据,可以理解为通过Batch Layer对我个人历史数据进行处理之后得出的Batch View推荐。(例如跑Spark Mllib或是Hadoop Mahout对历史数据进行分析推荐的结果,跑这类算法通常费时费力,可以通过提前计算的方式存入MySQL等,后续用户访问时可以直接调用)
2:接下来笔者在x宝网搜索了MacBook pro和ThinkPad x207,对于实时搜索的数据,可以作为流数据实时的通过Speed Layer进行处理。(例如Storm这样的流处理器)
3: 笔者切换回到x宝网的首页,发现多了一个推荐广告项目:Dell 8代CPU专业级显卡,晒单还送爱奇艺半年卡。显然实时流的Realtime View与Batch View共同组成的x宝网的推荐首页内容,很好的反馈了用户的实时需求:
在这里我还是要推荐下我自己建的大数据学习交流qq裙:522189307 , 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴。上述资料加群可以领取
Lambda架构结合了实时处理与批处理的结果,很好的反馈了查询需求,并且在速度和可靠性之间求取了平衡,具有足够的扩展性。在Lambda架构之中,所有的查询都可以定位成一个函数:
而Lambda架构将数据和计算系统进行细分:
但是这种架构同样存在一些问题:需要运维两套不同的计算系统,并且合并查询结果,这一定程序上带来了复杂性的增加
Lambda架构诞生之后,来自Linkedln的技术主管Jay Kreps提出了一些质疑,并在Lambda架构之上提出自己的改进版本,将其命名为Kappa架构。
Lambda架构最麻烦的问题就在于:新的逻辑需要两次编码,并且在两个系统中运行和调试代码,需要多运维一个额外的系统。所以Kreps认为Lambda架构试图在两个不同编程范式的顶部建立一个抽象层是非常难的。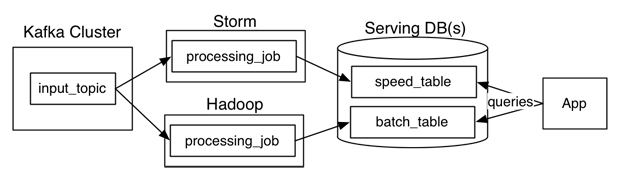
而Kappa架构尝试通过一个流处理系统来处理上述两种逻辑,我们来看看Kappa架构是怎么样去设计的: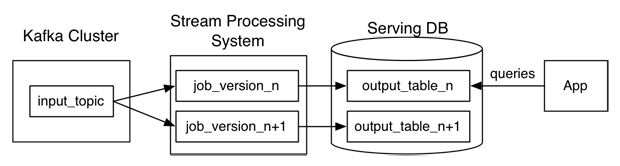
Kappa架构通过流处理系统的并行机制,来提高并行以实现重复处理。但是很多人会觉得流式处理对于历史数据的高吞吐量会力不从心,这里Kreps给出的解决方案是:仅仅重复处理的完整日志数据。加入需要重复处理30天数据,就利用Kafka保留到30天。
所以这里是开辟另个流式处理来处理新的数据,输出数据是直接输出到一个新的输出表。当这第二个流式处理完成之后,切换到新的表中进行读取,然后停止旧的流式处理,再删除旧的输出表。
同样的,笔者上文举的例子,同样也能通过Kappa架构来实现购物的广告展示。Kappa架构最为核心的是通过一个范式解决需要共同解决的问题。同时不需要引入额外计算系统进行运维。
到此为止,笔者也大致聊完两种不同分布式计算系统的架构。笔者认为Lambda架构是一个优秀的解决分布式计算的架构,但需要处理运维不同的大数据系统,并且额外编码逻辑,对于开发者与运维人员都是一个较大的考验。而Kappa架构简化了这个模型,但是对于数据处理总归很难拿出重型的批处理做一个完整数据计算,所以计算结果的准确性是有所限缩的。(也就是对于业务场景是挑剔的,我想也没有一种架构是解决问题的银弹,之间的取舍需要我们开发人员进行完整的评估~~)
而Spark能够通过一个计算框架同时解决批处理计算与流计算的问题,是很值得开发与运维人员所关注的.......
标签:小议,Layer,架构,Batch,Kappa,View,数据,Lambda 来源: https://blog.csdn.net/arry001/article/details/89765172
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。