标签:Flume 文件 Filebeat pipeline 组件 数据 Logstash
from:https://www.cnblogs.com/GO-NO-1/p/13307688.html
日志采集工具对比
1、Flume简介
Flume的设计宗旨是向Hadoop集群批量导入基于事件的海量数据。系统中最核心的角色是agent,Flume采集系统就是由一个个agent所连接起来形成。每一个agent相当于一个数据传递员,内部有三个组件:
-
source: 采集源,用于跟数据源对接,以获取数据
-
sink:传送数据的目的地,用于往下一级agent或者最终存储系统传递数据
-
channel:agent内部的数据传输通道,用于从source传输数据到sink
2、LogStash简介
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到存储库中。数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值
Logstash是基于pipeline方式进行数据处理的,pipeline可以理解为数据处理流程的抽象。在一条pipeline数据经过上游数据源汇总到消息队列中,然后由多个工作线程进行数据的转换处理,最后输出到下游组件。一个logstash中可以包含多个pipeline。
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器:
-
Input:数据输入组件,用于对接各种数据源,接入数据,支持解码器,允许对数据进行编码解码操作;必选组件;
-
output:数据输出组件,用于对接下游组件,发送处理后的数据,支持解码器,允许对数据进行编码解码操作;必选组件;
-
filter:数据过滤组件,负责对输入数据进行加工处理;可选组件;Logstash安装部署
-
pipeline:一条数据处理流程的逻辑抽象,类似于一条管道,数据从一端流入,经过处理后,从另一端流出;一个pipeline包括输入、过滤、输出3个部分,其中输入和输出部分是必选组件,过滤是可选组件;instance:一个Logstash实例,可以包含多条数据处理流程,即多个pipeline;
-
event:pipeline中的数据都是基于事件的,一个event可以看作是数据流中的一条数据或者一条消息;
3、FileBeat简介
Filebeat是一个日志文件托运工具,在服务器上安装客户端后,Filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到ElasticSearch或者Logstarsh中存放。
当你开启Filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
Filebeat由两个主要组成部分组成:prospector和 harvesters。这些组件一起工作来读取文件并将事件数据发送到指定的output。
-
Harvesters:负责读取单个文件的内容。harvesters逐行读取每个文件,并将内容发送到output中。每个文件都将启动一个harvesters。harvesters负责文件的打开和关闭,这意味着harvesters运行时,文件会保持打开状态。如果在收集过程中,即使删除了这个文件或者是对文件进行重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。默认情况下,Filebeat会一直保持文件的开启状态,直到超过配置的close_inactive参数,Filebeat才会把Harvester关闭。
-
Prospector:负责管理Harvsters,并且找到所有需要进行读取的数据源。如果input type配置的是log类型,Prospector将会去配置路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。每个Prospector都运行在自己的Go routine里。
Filebeat目前支持两种Prospector类型:log和stdin。每个Prospector类型可以在配置文件定义多个。log Prospector将会检查每一个文件是否需要启动Harvster,启动的Harvster是否还在运行,或者是该文件是否被忽略(可以通过配置 ignore_order,进行文件忽略)。如果是在Filebeat运行过程中新创建的文件,只要在Harvster关闭后,文件大小发生了变化,新文件才会被Prospector选择到。
4、综合对比
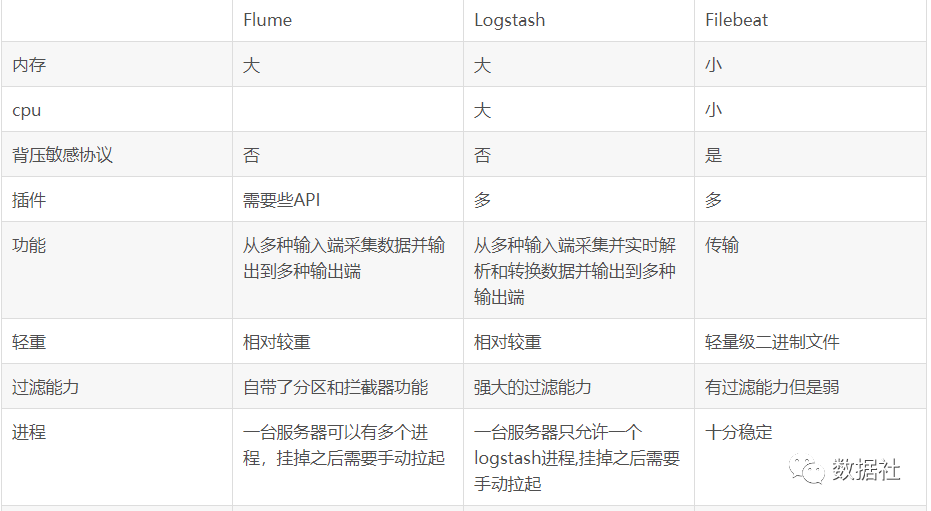


flume:
设计目的写HDFS,定制化开发和数据分发路由需求,注重数据传输(GB级别)
logstash:
使用简单较好上手,插件丰富,扩展功能更强,注重数据预处理(GB级别)
filebeat
设计目的写Logstash和ES,轻量型日志采集工具,与logstash协作,更稳健少宕机(数十MB级别)
标签:Flume,文件,Filebeat,pipeline,组件,数据,Logstash 来源: https://www.cnblogs.com/anenyang/p/16458639.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。