标签:Cloudera 环境 Hadoop hadoop master Apache 数据 搭建
Hadoop的发展史
爬取全球的网站,然后计算页面的PageRank
要解决网站的问题:
a:这些网站怎么存放
b:这些网站应该怎么计算
发布了三篇论文
a:GFS(Google File System)
b:MapReduce(数据计算方法)
c:BigTable:HBase
Hadoop三大开源发行版本:Apache、Cloudera、Hortonworks。Apache版本最原始(最基础)的版本,对于入门学习最好。Cloudera在大型互联网企业中用的较多。Hortonworks文档较好。
Apache Hadoop
官网地址:https://hadoop.apache.org/
下载地址:https://hadoop.apache.org/release.html
Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh.html
下载地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。
5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
Hortonworks Hadoop
官网地址:https://www.clouderacn.cn/products/hdp.html
下载地址:https://www.cloudera.com/downloads/hdp.html
1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
2018年10月,均为开源平台的Cloudera与Hortonworks公司宣布他们以52亿美元的价格合并。
官方网站:https://www.cloudera.com/
Cloudera 官方文档: https://www.cloudera.com/documentation/enterprise/latest.html
两家公司称合并后公司将拥有2500客户、7.2亿美元收入和5亿美元现金,且没有债务,宣布了它们所谓了相对平等的合并。
两大开源大数据平台Cloudera与Hortonworks宣布合并,合并后的企业定位为企业数据云提供商,推出了ClouderaDataPlatform(CDP),可以跨AWS、Azure、Google等主要公有云架构进行数据管理。2020年6月,Cloudera发布CDP私有云,将本地部署环境无缝连接至公有云。
CDP的版本号延续了之前CDH的版本号,从7.0开始,目前最新的版本号为7.0.3.0。
那么CDP对比之前的Cloudera Enterprise Data Hub(CDH企业版)与HDPEnterprise Plus(HDP企业版)到底在组件上发生了哪些变化呢?
由于HDP在国内市场上的市场占有量很小,大部分公司都是采用CDH,所以对于HDP带来的一些东西,使用CDH的用户和开发人员会比较陌生,下面带大家详细的了解一下CDP中的组件一些变化,也方便大家为在2022年以及之后的学习做好准备。
CDP、CDH、HDP中都包含的部分
Apache Hadoop(HDFS/YARN/MR)
Apache HBase
Apache Hive
Apache Oozie
Apache Spark
Apache Sqoop
Apache Zookeeper
Apache Parquet
Apache Phoenix(*CDH中需要额外安装)最关键的一点:CDP的组件代码在github上找不到,是不再开源了,CDP7以后就没有社区版了。
Hadoop 1.x ---> 3.x
注意:课程中的hadoop版本以CDH版本为准,稳定且主流,目前国内主流的是2.x,如果面试的时候说你用的是3.x可能会被。。。。并且2.x的变化都不大
Hadoop Common:基础型功能
Hadoop Distributed File System (HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。负责存放数据
Hadoop YARN:作业调度和集群资源管理的框架。负责资源的调配
Hadoop MapReduce:基于 YARN 的系统,用于并行处理大型数据集。大数据的计算框架
Hadoop框架透明地为应⽤提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应⽤程序被分割成许多⼩部分,⽽每个部分都能在集群中的任意节点上执⾏或重新执⾏。此外,Hadoop还提供了分布式⽂件系统,⽤以存储所有计算节点的数据,这为整个集群带来了⾮常⾼的带宽。MapReduce和分布式⽂件系统的设计,使得整个框架能够⾃动处理节点故障。它使应⽤程序与成千上万的独⽴计算的电脑和PB级的数据。
一句话简述:Hadoop是一个适合海量数据的分布式存储和分布式计算的平台。(面试必问!!!!)
国内现在大数据的行情
1)大数据的薪资属于同行业最高的
2)相对来讲这个技术比较稳定,Hadoop只是大数据的一员或者说是基石,大数据开发环境已经稳定。
(说到这的时候,带同学画一下目前主流的框架图,熟悉主题学习框架和功能,画图总结上面的概念)
分布式文件系统架构
一、名词科普
Apache基金会 是专门为支持开源软件项目而办的一个非盈利性组织 服务器(节点): 企业里任务和程序基本都是运行在服务器上。服务器内存和cpu以及硬盘等资源和性能远高于pc机 可以理解为我们的一台笔记本/台式机 在这里可以认为是我们的一台虚拟机 后面学习中,我们会把一台服务器称为一个节点
机架: 一个公司里,会有很多服务器。尤其是hadoop集群大到上千台服务器搭建成集群 负责存放服务器的架子 可以理解为鞋架(^_^)


二、分布式文件系统(从这开始,下面都是属于Hadoop中的原理)
1、FS File System
文件系统时极域硬盘之上的文件管理的工具
我们用户操作文件系统可以和硬盘进行解耦
2、DFS Distributed File System
分布式文件系统
将我们的数据存放在多台电脑上存储
分布式文件系统有很多,HDFS(Hadoop Distributed FileSyetem)是Hadoop自带的分布式文件系统
HDFS是mapreduce计算的基础
三、文件切分的思想(引出分而治之的思想 第一个核心思想)
a. 文件存放在一个磁盘上效率肯定是最低的
读取效率低
如果文件特别大会超出单机的存储范围
b. 字节数组
文件在磁盘真实存储文件的抽象概念
数组可以进行拆分和组装,源文件不会收到影响
c. 切分数据
对字节数组进行切分
d. 拼接数据
按照数组的偏移量将数据连接到一起,将字节数组连接到一起
e. 偏移量
当前数据在数组中的相对位置,可以理解为下标
数组都有对应的索引,可以快速定位数据
f. 数据存储的原理:
不管文件的大小,所有的文件都是由字节数组构成
如果我们要切分文件,就是将一个字节数组分成多份
我们将切分后的数据拼接到一起,数据还可以继续使用
我们需要根据数据的偏移量将他们重新拼接到一起
四、Block拆分标准
数据块Block
a. 是磁盘进行数据 读/写的最小单位,数据被切分后的一个整体被称之为块 b. 在Hadoop 1默认大小为64M,在Hadoop 2及其之后默认大小为128M块,这么大是为了最小化寻址开销 c. 同一个文件中,每个数据块的大小要一致除了最后一个节点外 不同文件中,块的大小可以不一致 文件大小不同可以设置不同的块的数量 HDFS中小于一个块的大小的文件不会占据整个块的空间 d. 真实情况下,会根据文件大小和集群节点的数量综合考虑块的大小 e. 数据块的个数=Ceil(文件大小/每个块的大小)
拆分的数据块需要等大
a. 数据计算的时候简化问题的复杂度(否则进行分布式算法设计的时候会因为数据量不一很难设计) b. 数据拉取的时候时间相对一致 c. 通过偏移量就知道这个块的位置 d. 相同文件分成的数据块大小应该相等
注意事项
a. 只要有任意一个块丢失,整个数据文件被损坏 b. HDFS中一旦文件被存储,数据不允许被修改 修改会影响偏移量 修改会导致数据倾斜(单节点数据量过多) 修改数据会导致蝴蝶效应 c. 但是可以被追加(一般不推荐) 追加设置需要手动打开 d. 一般HDFS存储的都是历史数据.所以将来Map Reduce都用来进行离线数据的处理 f. 块的大小一旦文件上传之后就不允许被修改 128M-512M
五、Block数据安全
a. 只要有任意一个块丢失,整个数据文件被损坏 b. 肯定要对存储数据做备份 c. HDFS是直接对原始数据进行备份的,这样能保证回复效率和读取效率 d. 备份的数据肯定不能存放在一个节点上,使用数据的时候可以就近获取数据 f. 备份的数量要小于等于节点的数量 g. 每个数据块默认会有三个副本,相同副本是不会存放在同一个节点上 h. 副本的数量可以变更 可能近期数据被分析的可能性很大,副本数可以多设置几个 后期数据很少被分析,可以减少副本数
六、Block的管理效率
需要专门给节点进行分工
-
存储 DataNode
-
记录 NameNode
-
日志 Secondary NameNode

Hadoop集群搭建(完全分布式版本)
一、准备工作
-
三台虚拟机:master、node1、node2
-
时间同步
ntpdate ntp.aliyun.com
-
调整时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
-
jdk1.8
java -version
-
修改主机名
三台分别执行 vim /etc/hostname 并将内容指定为对应的主机名
-
关闭防火墙:systemctl stop firewalld
-
查看防火墙状态:systemctl status firewalld
-
取消防火墙自启:systemctl disable firewalld
-
-
静态IP配置
-
直接使用图形化界面配置(不推荐)
-
手动编辑配置文件进行配置
1、编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
HWADDR=00:0C:29:E2:B8:F2
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.190.100
GATEWAY=192.168.190.2
NETMASK=255.255.255.0
DNS1=192.168.190.2
DNS2=223.6.6.6
需要修改:HWADDR(mac地址,centos7不需要手动指定mac地址)
IPADDR(根据自己的网段,自定义IP地址)
GATEWAY(根据自己的网段填写对应的网关地址)
2、关闭NetworkManager,并取消开机自启
systemctl stop NetworkManager
systemctl disable NetworkManager
3、重启网络服务
systemctl restart network
-
-
免密登录
# 1、生成密钥
ssh-keygen -t rsa
# 2、配置免密登录
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
# 3、测试免密登录
ssh node1 -
配置好映射文件:/etc/hosts
192.168.190.100 master
192.168.190.101 node1
192.168.190.102 node2
二、搭建Hadoop集群
1、上传安装包并解压
# 使用xftp上传压缩包至master的/usr/local/soft/packages/ cd /urs/local/soft/packages/ # 解压 tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
2、配置环境变量
vim /etc/profile JAVA_HOME=/usr/local/soft/jdk1.8.0_171 HADOOP_HOME=/usr/local/soft/hadoop-2.7.6 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH # 重新加载环境变量 source /etc/profile
3、修改Hadoop配置文件
-
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/ -
core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> -
hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
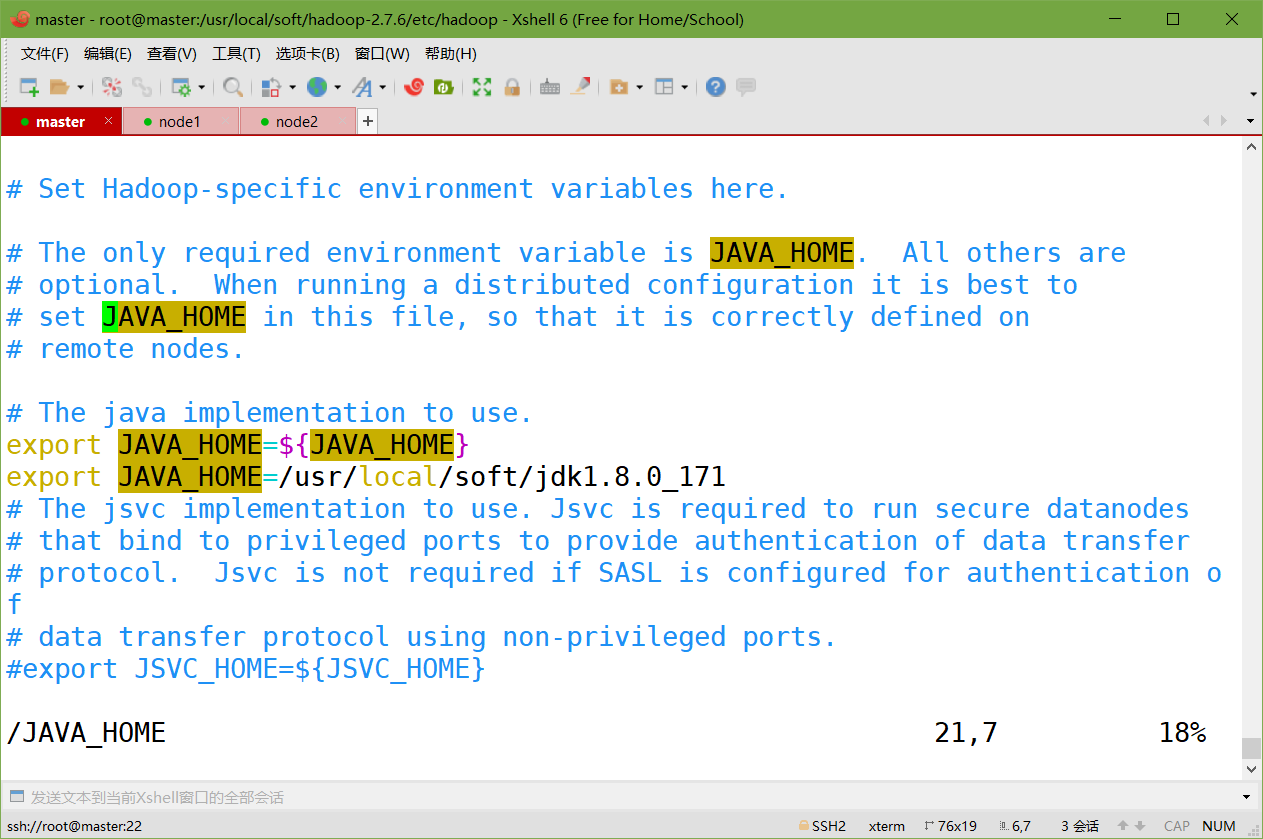
-
hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> -
mapred-site.xml.template
# 1、重命名文件 cp mapred-site.xml.template mapred-site.xml # 2、修改 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> -
slaves
node1 node2
-
yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
4、分发Hadoop到node1、node2
cd /usr/local/soft/ scp -r hadoop-2.7.6/ node1:`pwd` scp -r hadoop-2.7.6/ node2:`pwd`
5、格式化namenode(第一次启动的时候需要执行)
hdfs namenode -format
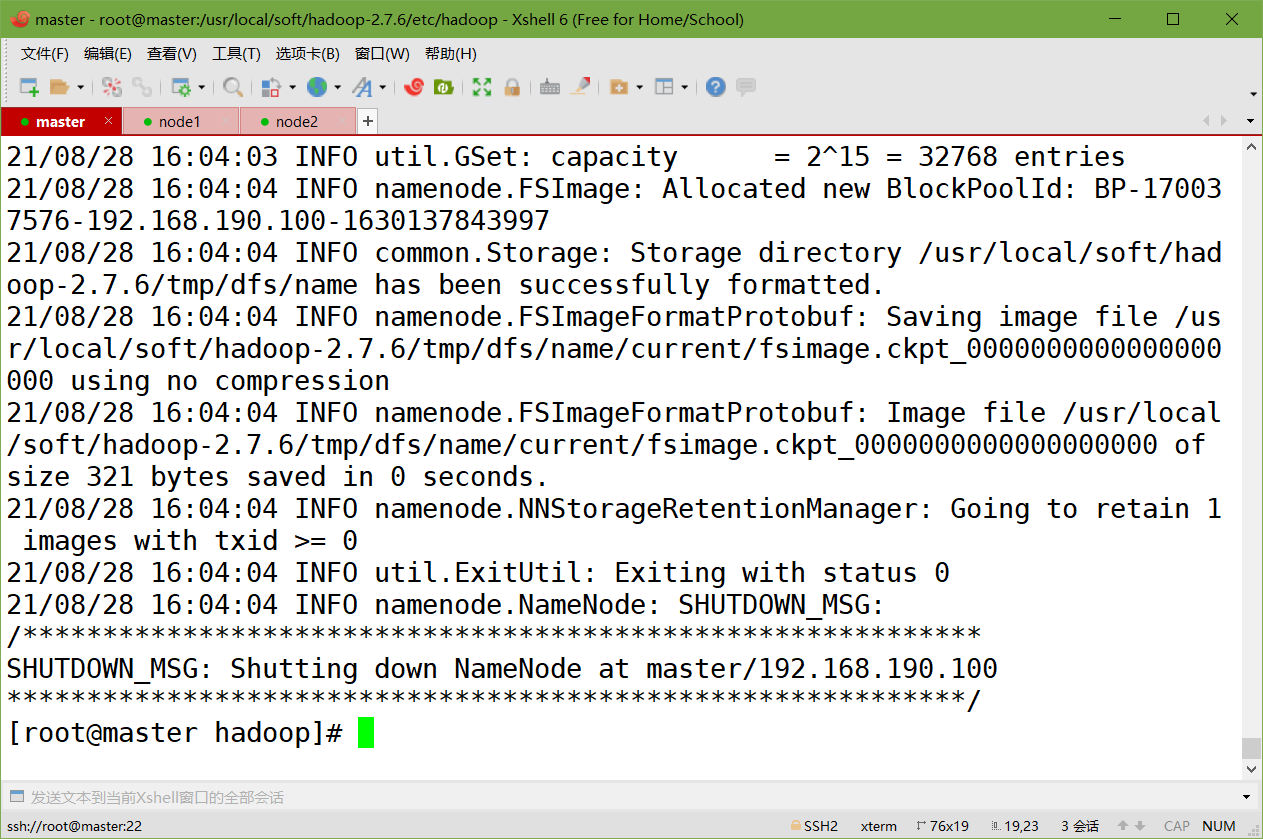
6、启动Hadoop集群
start-all.sh
7、检查master、node1、node2上的进程
-
master:
[root@master soft]# jps 2597 NameNode 2793 SecondaryNameNode 2953 ResourceManager 3215 Jps
-
node1:
[root@node1 jdk1.8.0_171]# jps 11361 DataNode 11459 NodeManager 11559 Jps
-
node2:
[root@node2 ~]# jps 11384 DataNode 11482 NodeManager 11582 Jps
8、访问HDFS的WEB界面
http://master:50070 50070前为master IP地址
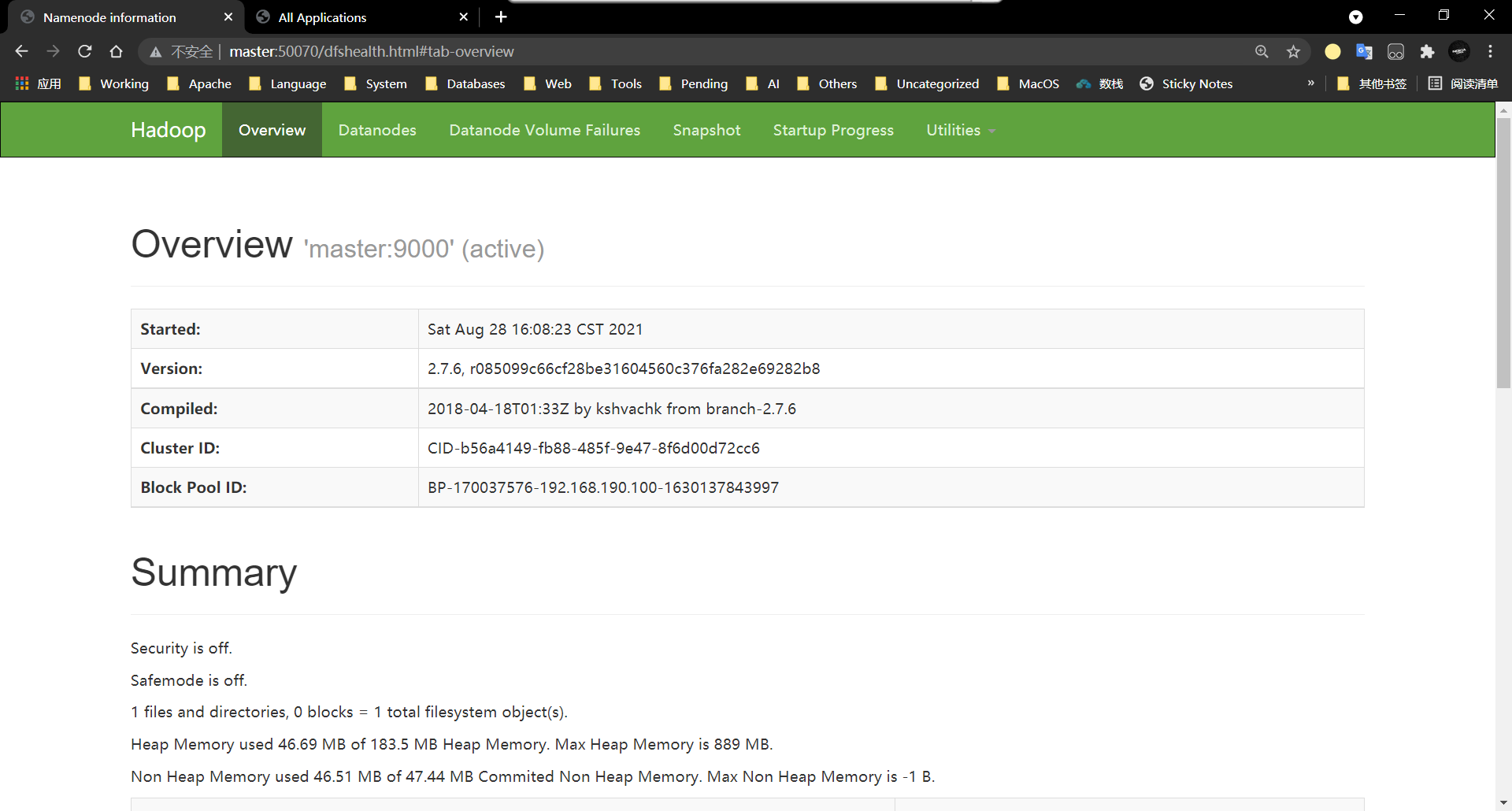
9、访问YARN的WEB界面
http://master:8088 8088前为master IP地址
标签:Cloudera,环境,Hadoop,hadoop,master,Apache,数据,搭建 来源: https://www.cnblogs.com/Longtianm/p/16295232.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。