简历
Find Moon(SOA)
开发环境:IDEA+Git+Maven
技术框架:SpringCloud Ali (Nacos,Gateway,Hystrix)+Dubbo+MyBatis-Plus+RabbitMQ+
Redis+MangoDB+FastDFS
项目描述:
主打陌生人社交, 用户可以发布音视频作品,可以搜索附近的人,查看好友动态,平台还会通过大数据计算进行智能推荐,通过智能推荐匹配好友,提供了在线即时通讯功能,可以实时的与好友进行沟通
这次项目中的工作内容如下:
实现了用户信息认证、个人中心等功能
实现了发现附近陌生人、附近动态等功能
实现了好友匹配、IM通讯、发布和查看动态等功能
实现了查看用户列表、动态列表、数据统计、用户冻结解冻等功能
解决方案:
●使用JWT加密用户信息用Redis缓存token
●基于MangoDB存储用户的粉丝、好友列表、动态信息
●使用MongoDB-Geo 进行地理位置查询实现搜索附近的人、动态等
●使用第三方API进行图片存储、内容审核、人脸识别、即时通讯
●基于RabbitMQ异步写入用户操作用于数据统计
- 异步解耦 RabbitMQ
- 熔断限流 hystrix
- 网关 gateway
- 远程调用 openFeign ribbon
- 服务注册发现和配置管理 Nacos + Dobbo
这个项目用到什么技术
SpringCloud Ali
Nacos
Redis
FastDFS
RabbitMQ
MongoDB
Dubbo
环信
头条(微服务)
开发环境:IDEA+Git+Maven
技术框架:SpringCloud Ali (Nacos,Gateway,OpenFeign,Sentinel,Seata)+Mybatis-Plus+ES+kafka+xxljob
项目描述:
文章分享平台
九章头条是一个移动资讯应用,可以实时查看热点资讯、国际时政、推荐资讯等。具备实时点击流的监控能力、粉丝行为实时分析能力、热点资讯分析能力,自媒体作者可通过平台发布优质资讯实现创收,并能使用数据助手实时分析数据流量、粉丝行为。
这次项目中的工作内容如下:
实现了热榜推荐、关注推荐、分布式文件管理等功能
实现了素材管理、文章管理、文章发布 、文章审核等功能
实现了用户点赞、阅读、收藏、评论等功能
实现了频道管理、敏感词管理、用户认证审核等功能
解决方案:
● 基于Kafka异步处理文章上下架、用户点赞、评论等事件的消息通知
● 基于Redis存储用户关注、点赞、阅读、收藏等行为数据
● 基于Elasticsearch根据用户喜欢的文章标签进行推荐, 用户喜欢的标签放在Redis中计算,根据所有用户的评论,点赞,关注等行为进行加权计算出分数
● 基于xxljob定时计算文章热度,根据近期热度推荐上热门
我写进去的技术
- 分布式事务 seata
- 异步解耦 kafka
- 实时数据处理 kafkaStream
- 全局搜索 ES
- 熔断限流 sentinel
- 网关 gateway
- 远程调用 openFeign ribbon
- 服务注册发现和配置管理 nacos
这个项目用到什么技术
SpringCloud Ali
- Seata -分布式事务
- 文章自动审核会涉及到文章保存 用到了远程调用
- 微服务之间的调用,也许会出现A服务任务完成结果调用传送给B服务,但是B服务也许会执行失败
- 此时就要到分布式事务
- Nacos
- Sentinel
SpringCloud
- ribbon
- Gateway
- openFeign
ElasticSearch
kafka
- kafkaStream
- 实时流式计算
FreeMarker
数据
- Redis
- MongoDB
- minio
- MyBatisPlus
xxl-job
- 分布式任务调度
- 定时调度
Skywalking
探花
APP端
单点登录
- 注册
- 上传头像(ALiFace)
- 保存用户信息
- 登录接口放行
- 基于WebMvcConfigurer接口类对所有接口处理
- addInterceptors:拦截器
- addInterceptor:需要一个实现HandlerInterceptor接口的拦截器实例
- addPathPatterns:用于设置拦截器的过滤路径规则;
addPathPatterns("/**")对所有请求都拦截 - excludePathPatterns:用于设置不需要拦截的过滤规则
- 拦截器主要用途:进行用户登录状态的拦截,日志的拦截等。
源码复习
实现思想
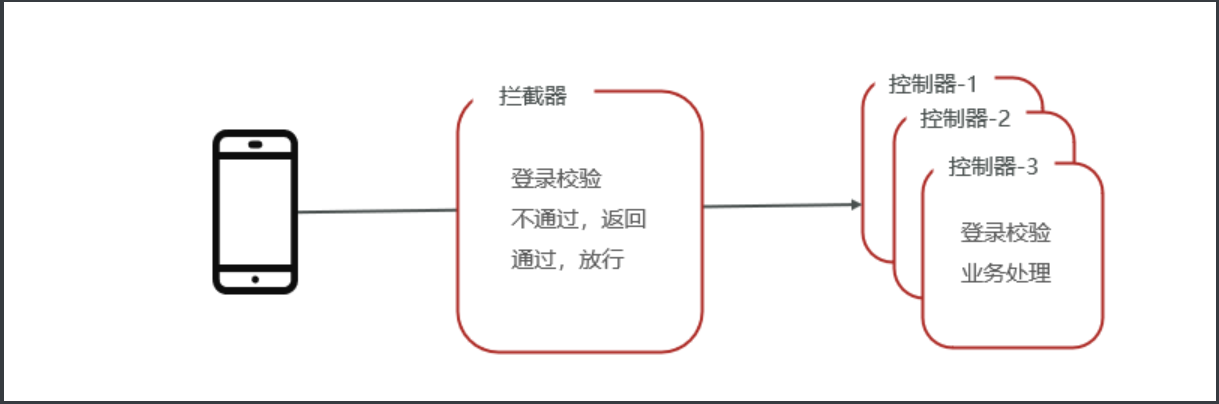
放行用户进入登录接口拦截所有后续请求交给给Interceptor进行验证
-
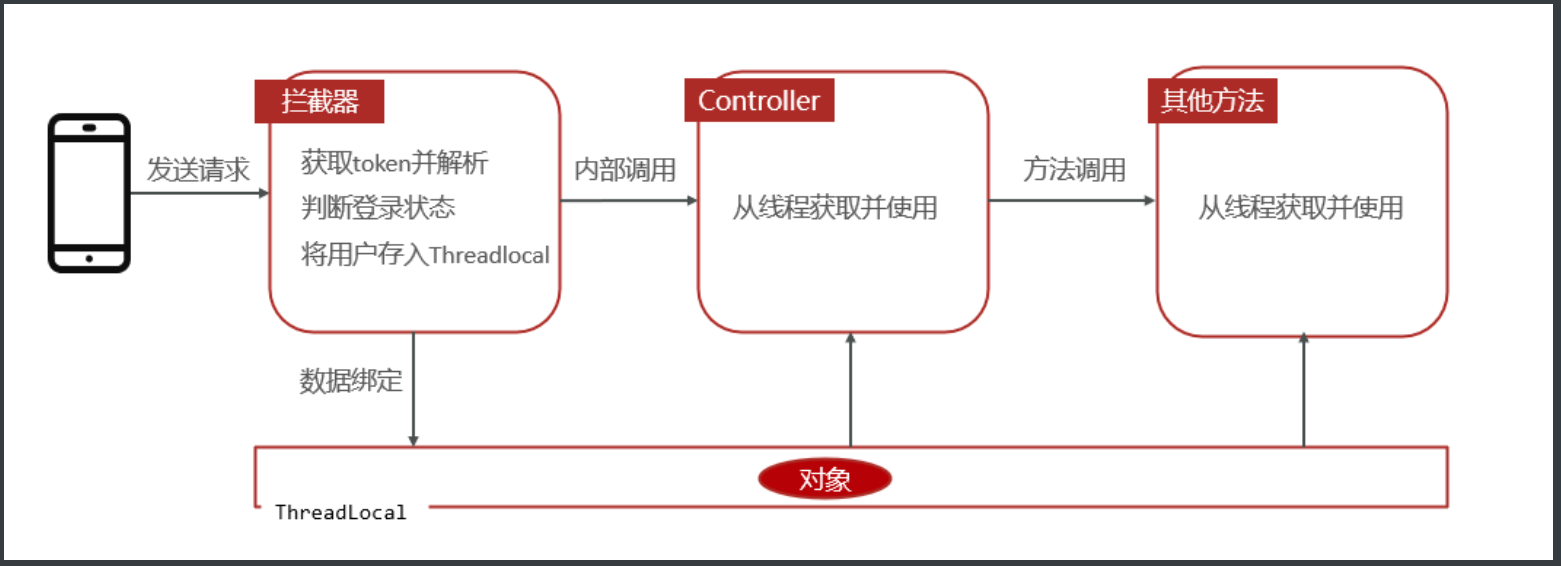
统一JWT验证处理(重点)
-
基于ThreadLocal + HandlerInterceptor拦截器的形式统一处理
-
拦截器HandlerInterceptor解释
-
- HandlerInterceptor是一种动态拦截方法调用的机制; - 类似于Servlet 开发中的过滤器Filter,用于对处理器进行前置处理和后置处理。
-
-
ThreadLocal 解释
- 线程内部的存储类,赋予了线程存储数据的能力。 - 线程内调用的方法都可以从ThreadLocal中获取同一个对象。 - 多个线程中ThreadLocal数据相互隔离源码复习
实现思想
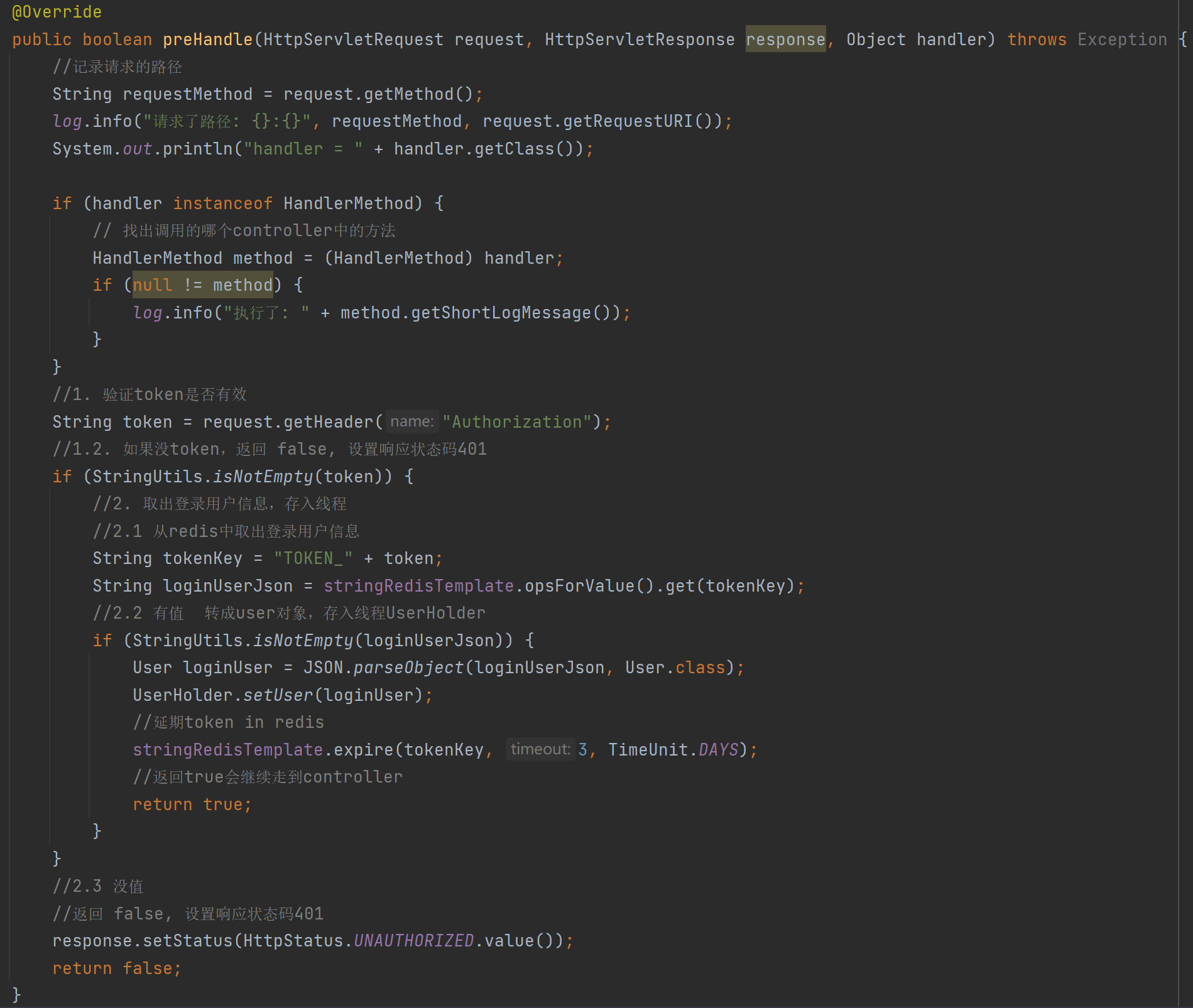
- 定义一个实现HandlerInterceptor接口统一处理Token的类
- 重写preHandle方法,这个方法会在controller之前执行
- 在preHandle方法中拦截获取请求头中的'Authorization'判断token是否有效
- 如果有效就将token中的用户信息封装进ThreadLocal中,放行请求进入controller并延长token在redis中的存储时间
- 如果无效就返回401让用户先登陆账号
- 定义一个实现HandlerInterceptor接口统一处理Token的类
-
-
信息管理
-
上传头像
- 使用百度AI对头像图片进行人脸检测,如果不是人脸则提示用户
- 如果是人脸则上传到阿里云OSS,返回OSS的URL并保存到用户表中
-
查看、更新用户资料
- 查看
- 从用户资料表中查询用户信息封装给前台
- 数据库操作条件为ThreadLocal线程中共享的用户id
- 更新
- 将前端传来的用户资料保存到用户资料表中
- 数据库操作条件为ThreadLocal线程中共享的用户id
- 查看
-
设置陌生人问题
- 将前端传来的陌生人问题文本保存或更新到陌生人问题表中
- 数据库操作条件为ThreadLocal线程中共享的用户id
-
设置黑名单
- 配置Mybatis-Plus分页插件
- 根据前端提供的当前页码和每页查询条数查询黑名单表返回VO数据
圈子互动
- 个人中心
- 发布动态
- 将前端传来的图片上传到OSS并返回URL
- 图片URL、文本内容、地理位置信息、发布时间按保存到MongoDB的动态表里
- 并将发布时间保存到时间线表内对应的每位好友(可用RabbitMQ)
- 用异步线程池提升效率
- 发布小视频(FastDFS、SpringCache)
- 将小视频上传到第三方服务器,并返回小视频存放信息,比如视频存储和封面的URL
- 同时使用SpringCache将存放信息放入Redis,下次查询可以直接从缓存里面拿(@Cacheable)
- 小视频列表
- 根据分页条件,按时间倒序查询
- 优先从redis中使用SpringCache查询(@Cacheable)
- SpringCache
- @EnableCaching(开启缓存支持)
- 打在启动类上,否则下面的注解没用
- @Cacheable
- 打在方法上
- 先从缓存里面查询数据,有就从缓存拿,没有再从数据库拿
- @CacheEvict
- 打在方法上
- 将缓存的数据删除
- @EnableCaching(开启缓存支持)
- 查看个人动态
- 根据前台page pageSize分页按时间降序返回自己的动态给前台
- 动态查询
- 查询好友动态
- 根据个人ID查询出所有好友的ID
- 以所有好友的ID和时间线为条件
- 分页倒序返回给前台
- 查询推荐动态
- 推荐动态是通过大数据推荐系统计算后将动态id保存到Redis中
- 根据用户自己的ID取Redis中查询被推荐的数据
- 如果没有给用户推荐就随机推荐一页动态,如果有分配推荐则分页倒序返回给前端
- 根据ID查询动态
- 使用场景:当手机端查看评论内容时可以点击用户头像查询别人的动态
- 互动
pojo类中有一个CommentType字段,用来判断评论类型
- 动态评论
- 分为两步
- 展示评论列表
- 根据动态ID查询到这条动态下的评论数据,倒序返回给前台
- 发布评论
- 接收到动态ID和评论内容,向动态表插入评论内容后刷新评论列表
- 展示评论列表
- 分为两步
- 点赞
- 动态表中以boolean类型标识点赞与否
- 点赞和取消点赞以点赞者ID与动态ID为条件对数据进行操作
- 并将结果状态存入Redis中作为标识
- 喜欢
- 与点赞逻辑类似
即时通讯
环信为开发者提供了Server SDK,是对环信IM 服务端API 的封装,这样做是为了节省服务器端开发者对接环信API的时间,只需要配置自己的appkey相关信息即可使用。
登录注册的同时在环信上注册用户账号,将环信用户账号存入用户表
- 通讯
- 查看佳人信息、查看陌生人问题、回复陌生人问题
- 在首页可以查看感兴趣人的详细资料。
- 点击“聊一下”,可以查看对方对陌生人设置的的问题
- 用户输入陌生人问题的答案 , 点击聊一下 , 通过服务器端,给目标用户发送一条陌生人消息
- 联系人管理(添加、删除、列表)
- 收到陌生人信息之后可以点击确认将对方添加为好友,双方的好哦与关系保存到好友表中,同时环信上叶将两人联系为好友
- 删除关系则同时解除数据库表和环信的好友关系
- 根据个人ID在好友表查询,互为好友关系的用户以分页添加时间倒序返回给前端
- 信息通讯(图、音、视频)
- 调用
- 访客
- 访客记录,谁看过我、查看访客列表
- 附近的人
MongoDB 支持对地理空间数据的查询操作。
地理位置查询,必须创建索引才可以能查询,目前有两种索引。
2d :
使用2d index 能够将数据作为二维平面上的点存储起来,在MongoDB 2.4以前使用2d。
2dsphere:
2dsphere索引支持查询在一个类地球的球面上进行几何计算,以GeoJSON对象或者普通坐标对的方式存储数据。MongoDB内部支持多种GeoJson对象类型:
- 上报定位
- 当客户端检测用户的地理位置,当变化大于500米时或每隔5分钟,向服务端上报地理位置
- 将前台发来的经纬度和地名保存到mongoDB数据库
- 搜索附近
- 根据前台发送的性别和距离筛选出附近的人排除自己后返回
后台系统
配置
-
gateway网关
-
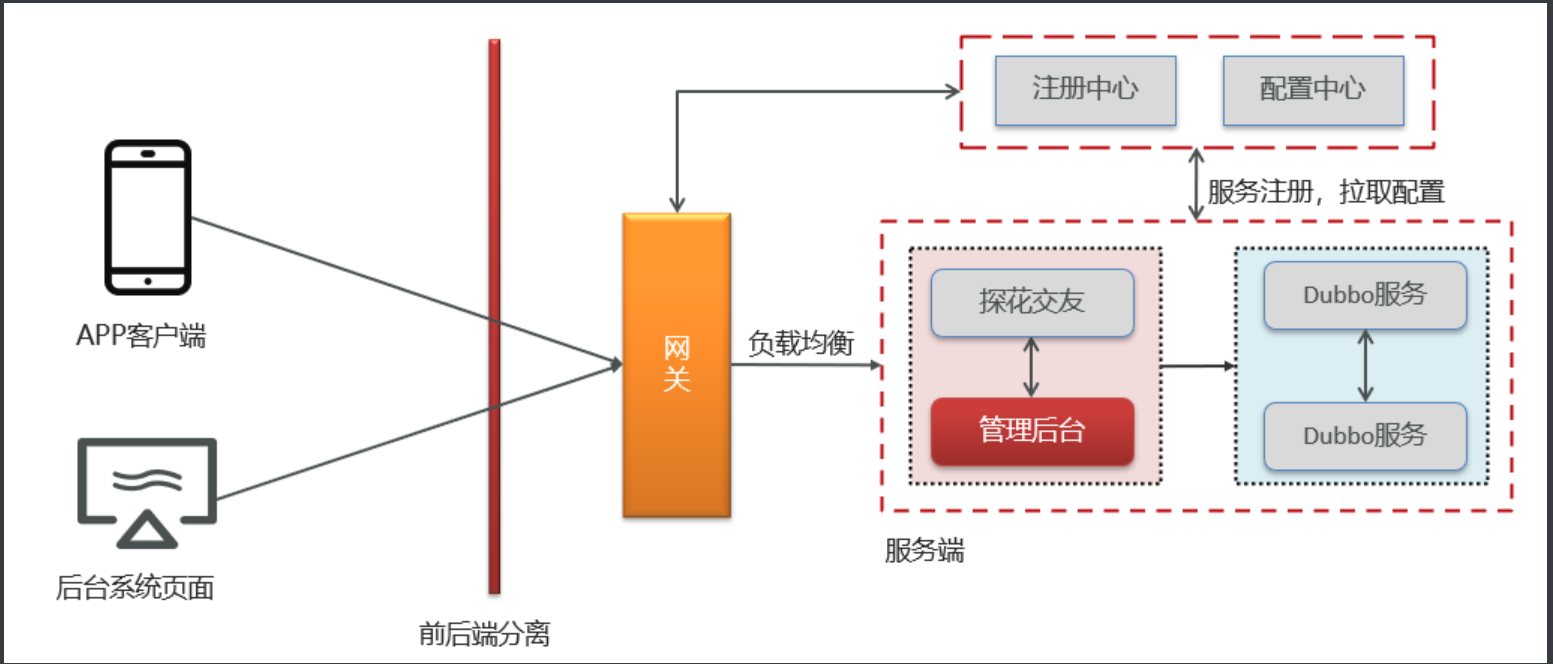
-
配置
server: port: 8888 spring: application: name: tanhua-gateway redis: host: 101.33.219.225 port: 6379 cloud: nacos: discovery: server-addr: 101.33.219.225:8848 gateway: globalcors: add-to-simple-url-handler-mapping: true corsConfigurations: '[/**]': allowedHeaders: "*" allowedOrigins: "*" allowedMethods: - GET - POST - DELETE - PUT - OPTION routes: # 手机端访问 - id: tanhua-app-server # 转发的地址, lb负载均衡, lb://{spring.application.name} uri: lb://tanhua-app-server predicates: # 路由断言 如果请求路径为 /app/tanhua-app-server 转给 tanhua-app-server处理 - Path=/app/** filters: # 把/app截取掉 1 为 /app 2为 /app/XX - StripPrefix= 1 # 管理后台 #- id: tanhua-admin # uri: lb://tanhua-admin # predicates: # - Path=/admin/** # filters: # - StripPrefix= 1 #自定义配置,定义不需要校验token的连接,即白名单 #gateway: # excludedUrls: /user/login,/user/loginVerification,/system/users/verification,/system/users/login
-
-
Nacos配置中心
-
nginx负载均衡
后台系统
- 生成验证码
- 用户登录
- 获取用户资料
- 查看用户列表
- 查看用户详情
- 查看视频列表
- 查看动态列表
- 用户冻结解冻
数据统计和动态审核
- 查询数据列表
- 数据统计
- 定时任务
- 首页统计
- 阿里云内容审核
- 动态审核
头条
day01
- 登录
- 网关鉴权
day02
- 文章列表
- MinIo
- FreeMarker
day03
- 自媒体素材上传
- 素材添加
- 素材列表
- 文章列表
- 文章添加文章操作
day04
- 文章自动审核
- 异步审核
- openFeign
- Hystrix服务降级
day05
- 分布式事务Seata
- 忘了用在哪了
day06
基于Kafka异步处理文章上下架
- kafka
- 分区 - 偏移量 - 异步通知
- 文章上下架
day07 & day08
基于Redis存储用户关注、点赞、阅读、收藏等行为数据
点赞的流程
比如说点赞,第一次查看的都是远程加载,查看的时候你点赞的那一刻会把信息保存在浏览器(localStore)或者App本地紧接着把点赞数据传到服务器,但我仅仅是把我的点赞给服务器(取消点赞同理),并没有获取服务器点赞的总数量。
我会每隔一段时间(5s OR 10s)检查本地数据 ,看他有没有超过5s,如果超过了5s我再从服务器加载最新的点赞数量 ,或者你只要刷新页面也会加载新数据
day09
基于Elasticsearch加权计算推荐用户爱好内容
- ES + MongoDB
- 文章搜索
day10
基于xxljob定时计算文章热度,根据近期热度推荐上热门
热门数据功能分析
热门文章关注的点是两个 1热点文章 2定时问题
推荐功能的数据是从最近发布的数据进行展示,既然是推荐那它看的人一定是很多的,数据加载一定要讲究效率问题,还有另外一个问题,就是数据量大的时候加载效率该怎么解决,加载数据量大的时候我们就要想法子替换数据库查询用noSql,所以这一块我们要想办法把数据替换到noSql里面去。
还有一个问题就是这个数据到底是加载所有数据还是加载推荐的一些部分数据呢?其实只是加载推荐的部分数据而已,这个推荐数据它一般都是热门的,并不会把一些非热门的数据给你。
这一块就会设计到文章的热门数据计算,那热门数据计算我们就整一个热门数据计算。
比如说一篇文章,它有很多人去评论点赞分享收藏,这个时候我们程序就对这个文章做一些事情,那就是给这个文章做加分操作,得分越高的就越靠前展示,到时候我们就把这个数据存储到redis缓存里面去,存到
redis缓存之后,别人看到这个数据之后就可以直接在redia里面加载了。
但是这个数据是用户给文章点一下我就给它加一分吗,是的,就是这么做,点赞阅读评论转发都会加分。加了之后我们就会去计算总的得分,总分越高就会越靠前展示。
不过我们这一块并不打算做实时点击计算,我并不会立刻把数据推送到redis里面去,定时计算什么意思呢,用户点赞就点赞,收藏就收藏,我过一阵子,比如过10分钟、20分钟再批量导入到redis。
定时计算的流程
首先我们会查询最近几天分布的所有文章,然后去通过它的一些用户行为操作计算它的得分,点赞评论阅读收藏等等等等,然后得到这个得分对应的值之后,把这个对应的值存储到redis里面,之后我们在用户查看推荐文章的时候直接在redis里面查看就可以了。
热门数据的特性
热门数据基本上所有用户都是一样的,热门数据是有限的,且时间都是附近的
热门数据设计方案实现
热点数据有两个特性
数据有限
- 加载效率非常快,排除sql加载,要不是redis要不是mongoDB,如果是mongoDB它不可能是这么点数据,所以他肯定是基于内存noSql来加载的,因为数据非常有限,不会存储大量空间
数据时效性很高
- 跟时间排序有关
用户行为会改变文章热门程度
点赞的流程
比如说点赞,第一次查看的都是远程加载,查看的时候你点赞的那一刻会把信息保存在浏览器(localStore)或者App本地紧接着把点赞数据传到服务器,但我仅仅是把我的点赞给服务器(取消点赞同理),并没有获取服务器点赞的总数量。
我会每隔一段时间(5s OR 10s)检查本地数据 ,看他有没有超过5s,如果超过了5s我再从服务器加载最新的点赞数量 ,或者你只要刷新页面也会加载新数据
另外他怎么保证之前的数据慢慢淘汰的呢
用户行为(点赞、评论、转发)都是异步操作 @Async,之后的操作都用来存储数据和淘汰
1实现文章点赞收藏等功能记录到MongoDB (一般记录到MongoDB而不是Redis)
2热门数据统计,只统计当前点赞的文章数据就行,统计该文章的热门得分值,往redis缓存中进行存储,存的是zset,zset有排序分页功能 zsetKey [1001:2022022500001....]
3但我们每次执行异步操作的时候都会检查redis缓存是否已存在需要存入的文章数据
- 如果有就根据用户行为在redis进行加分
- 如果没有则判断redis的zset容量是否满
- 不满则直接添加
- 满了则找到最低分值的文章进行替换
为甚zset的得分值要这么写呢,应为我们要保证文章的时效性,如果我们只需要一周的热点文章的话,每天或者每周定时清理超时的热点数据,这样用户就不会在热点数据里看到很久以前的数据了

- xxljob
- 分布式任务调度
- 定时计算热点文章
- 推荐系统
day11
实时计算文章热度
- kafkaStream
- 实时计算热点文章
day12
- 实时链路追踪
- 软件使用
- 日志记录
标签:简历,点赞,用户,查询,文章,动态,数据 来源: https://www.cnblogs.com/RefineCcl/p/15937858.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。