标签:wedge 树状 int lowbit 笔记 数组 区间
前置芝士
lowbit 函数。
lowbit(\(n\)) 定义为非负整数 \(n\) 在二进制表示下最低位的 \(1\) 及其后边所有的 \(0\) 构成的数值。例如 \(n=10\) 的二进制表示为 \((1010)_2\),则 \(lowbit(10)=2=(10)_2\)。下面来推导一下 \(lowbit\) 的公式。
设 \(n > 0\),\(n\) 在二进制下的第 \(k\) 位是 \(1\),其后边全部为 \(0\)。
首先把 \(n\) 取反(~), 第 \(k\) 位变为 \(0\),第 \(0\)~\(k-1\) 位都是 \(1\)。再令 \(n=n+1\),此时因为进位,第 \(k\) 位变为 \(1\),第 \(0\)~\(k-1\) 位变为 \(0\)。
可以发现,对于 \(n\) 取反加 \(1\) 后。 \(n\) 的第 \(k+1\) 位到最高位都与原来相反,且只有第 \(k\) 位唯一。根据“与”运算中,只有两个数这一位都为 \(1\),才会得到 \(1\),那么 \(n\) & ~\(n+1\) 显然就只有第 \(k\) 位为 \(1\),而在补码表示下,~\(n=-n-1\)。那么就可以得到:
\(lowbit(n)=n\) & (~\(n+1\))\(=n\) & \((-n)\)。
摘自 lyd 大佬的《算法竞赛进阶指南》。
树状数组能做什么?
求前缀和以及单点修改。时间复杂度都是 \(O(\log n)\)。
普通的数组求前缀和是 \(O(n)\),单点修改是 \(O(1)\)。
普通的前缀和数组和是 \(O(1)\),单点修改是 \(O(n)\)。
所以在同时要求求前缀和和单点修改时,使用树状数组的时间复杂度会更优。
树状数组的思想
根据任意正整数关于 2 的不重复次幂的唯一分解性质(也就是说二进制数和十进制数一一对应),可以把一个正整数 \(x\) 进行二进制分解,得到:
\(x=2^{i_1}+2^{i_2}+...+2^{i_m}\)。
不妨设 \(i_1 > i_2 >...> i_m\),进一步地,区间 \([1,x]\) 可以分成 \(\log x\)(\(m\))个子区间:
1.长度为 \(2^{i_1}\)的子区间 \([1,2^{i_1}]\)。
2.长度为 \(2^{i_2}\)的子区间 \([2^{i_1}+1,2^{i_1}+2^{i_2}]\)。
3.长度为 \(2^{i_3}\)的子区间 \([2^{i_1}+2^{i_2}+1,2^{i_1}+2^{i_2}+2^{i_3}]\)。
……
m.长度为 \(2^{i_m}\)的子区间 \([2^{i_1}+2^{i_2}+...+2^{i_{m_1}}+1,2^{i_1}+2^{i_2}+...+2^{i_m}]\)。
这些子区间的共同特点是:若区间结尾 \(R\),则区间长度就等于 \(R\) 在二进制下最小的2的幂次,也就是 lowbit(\(R\))。
例如当 \(x=7\) 时,\(x=7=2^2+2^1+2^0\),区间 \([1,7]\) 也就会分成 \([1,4],[5,6],[7,7]\) 三个子区间。如果把区间的端点用二进制表示,那么就是 \([001,100],[101,110],[111,111]\)。也就符合了上面提到的特点。
并且可以发现, \(R_i-1=R_i-lowbit(R_i)=L_i-1\)。
那么就可以得出枚举区间 \([1,x]\) 分成的所有子区间的代码:
while(x)
{
printf("%d %d\n",x-lowbit(x)+1,x);
x-=lowbit(x);
}
以上就是树状数组的核心思想。
如果把区间 \([x-lowbit(x)+1,x]\) 内所有的数的和储存到 \(C[x]\) 中。同时,如果把 \(c[x]\) 数组之间的关系用边相连,那么可以发现 \(c[x]\) 具有树形结构。如当 \(N=16\) ,储存区间 \([1,N]\) 时,就会得到 \(c[x]\) 的关系如下图所示:
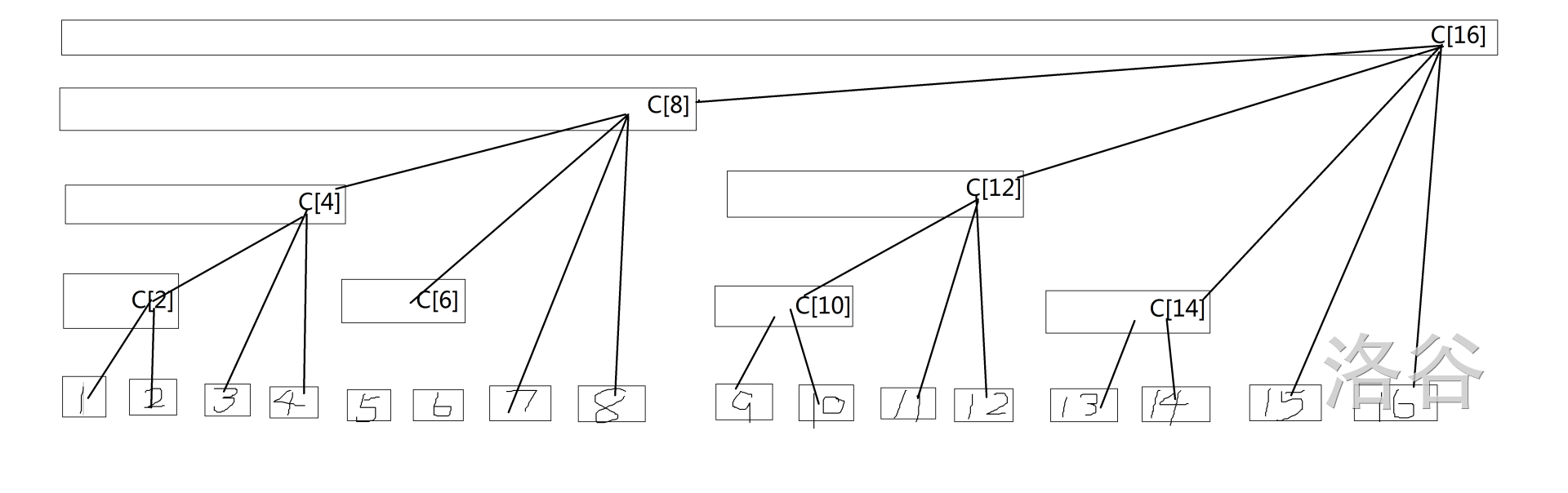
同时可以发现,该结构中满足一些性质:
1.每个内部节点 \(c[x]\) 保存以它为根的子树中所有叶子节点的和。
2.除树根外,每个节点 \(c[x]\) 的父节点就是 \(c[x+lowbit(x)]\)。
3.树的深度为 \(\log N\)。
这里举的是 \(N\) 为 2 的整次幂的特殊情况。对于一般的情况,最终得到的 \(c[x]\) 也是一个满足上述性质的森林结构。
那么求 \([1,x]\) 的区间和,代码就可以这样写:
int query(int x)
{
int res=0;
while(x)
{
res+=c[x];
x-=lowbit(x);
}
return res;
}
对于单点修改操作,即将 \(a[x]\) 加上 \(k\)。根据上述树形结构,只有节点 \(c[x]\) 和所有的祖先节点中包含 \(a[x]\) ,只需对这些节点进行修改即可。而根据性质 \(2\),就可以得到单点修改操作的代码:
void updata(int x,int k)
{
while(x<=n)
{
c[x]+=k;
x+=lowbit(x);
}
}
于是就可以通过这道 树状数组 1。
而对于 树状数组 2 这道题。题目中虽然是区间修改,但是是单点查询。于是就可以运用差分的思想。在树状数组中记录差分数组的前缀和,查询的时候直接输出差分数组的前缀和加上该点原来的数值即可。
所以树状数组的代码是数据结构中最简单的,没有之一。
树状数组与逆序对
对于求逆序对数量,可以用归并排序直接进行求解。但是也可以用树状数组来求解。
对于一个序列 \(a\) ,在它的数值范围上建立一个树状数组。
倒序扫描给定的序列 \(a\),对于每一个数 \(a[i]\) ,在树状数组中查询 \([1,a[i]-1]\)的前缀和,即与 \(a[i]\) 构成的且 \(a[i]\) 在前的逆序对数量。
每次扫描完以后,就把这个数添加到树状数组中,注意是把树状数组中表示 \(a[i]\) 的这个子节点 \(+1\),而不是 \(+a[i]\)。也就是 \(updata(a[i],1)\)。
最终得到的就是总的逆序对数量。时间复杂度为 \(O((N+M)\log M)\),其中 \(M\)
为 \(a_i\) 的范围大小(一般情况下就是最大的 \(a_i\))。但是需要注意,如果 \(M\) 太大,那么这样做的时间复杂度就太高了。当然也可以离散化,但是离散化本身就包含了排序,所以当数据范围太大时还是直接用归并排序就好了。
应用——康托展开。
一个简单的整数问题2
问题1就是树状数组模板2,这里就直接省略了。
题意
给定一个整数序列,要求支持区间修改和区间查询两种操作。
思路
可以发现,这次的两个操作都是区间,那么如果按照单点一个个修改过去肯定会 TLE。所以说需要更优的做法。
如果按照前一题的做法,用树状数组维护差分数组。那么要求修改后的前缀和 \(c[x]\) 可以这样推导:
$c[x]=\sum_{i=1}{x}\sum_{j=1}{i}b[j] $。
对于 \(b[i]\) ,在公式中不容易看出端倪,于是可以画出来,得:
\(\begin{bmatrix} b_1& & & & \\ b_1& b_2& & & \\ b_1& b_2& b_3& & \\ ... \\ b_1& b_2& b_3& ...&b_n \end{bmatrix} \)
如果再将这个矩阵补齐,就可以得到:
\( \begin{bmatrix} {\color{Red} b_1}& {\color{Red} b_2} & {\color{Red} b_3}&...&{\color{Red} b_5}\\ b_1& {\color{Red} b_2} & {\color{Red} b_3}&...&{\color{Red} b_5} \\ b_1& b_2& {\color{Red} b_3}&... &{\color{Red} b_5} \\ b_1& b_2& b_3& &{\color{Red} b_5} \\ ... \\ b_1& b_2& b_3& ...&b_n \end{bmatrix} \)
于是 \(\sum_{i=1}^{n}\sum_{j=1}^{i}b[j]=(b[1]+b[2]+..b[n])*(n+1)-b_1*1-b_2*2-...-b_n*n\)。
于是就可以建立两个树状数组,分别维护 \(b[i]\) 的前缀和,\(b[i]*i\) 的前缀和。这样就可以通过本题了。
code:
#include<cstdio>
using namespace std;
const int N=1e5+10;
#define int long long
int n,m,a[N],c1[N],c2[N];
int lowbit(int x){return x&(-x);}
void updata(int c[],int x,int k)
{
while(x<=n)
{
c[x]+=k;
x+=lowbit(x);
}
}
int query(int c[],int x)
{
int res=0;
while(x)
{
res+=c[x];
x-=lowbit(x);
}
return res;
}
int sum(int x){return query(c1,x)*(x+1)-query(c2,x);}
signed main()
{
scanf("%lld%lld",&n,&m);
for(int i=1;i<=n;i++)
{
scanf("%lld",&a[i]);
int b=a[i]-a[i-1];
updata(c1,i,b);
updata(c2,i,i*b);
}
while(m--)
{
char op[2];
int l,r,d;
scanf("%s%lld%lld",op,&l,&r);
if(op[0]=='Q') printf("%lld\n",sum(r)-sum(l-1));
else
{
scanf("%lld",&d);
updata(c1,l,d),updata(c2,l,l*d);
updata(c1,r+1,-d),updata(c2,r+1,-(r+1)*d);
}
}
return 0;
}
谜一样的牛
题意
有 \(n\) 头身高从 \(1\)~\(n\) 的奶牛排成一列,每头奶牛只知道自己前面有多少只奶牛比自己矮。求每只奶牛具体的身高。
思路
首先可以注意到,对于最后一头牛,如果他前面有 \(a_n\) 只奶牛比他矮,那他的身高就应该是 \(a_n+1\)。同时由于每只奶牛的身高互不相同,前面的奶牛的身高就不可能是 \(a_n+1\)了。于是就可以从后往前推奶牛的身高。
而对于第 \(i\) 只奶牛,如果他后面的 \(n-i\) 只奶牛的身高都已经确定,并且前面还有 \(a_i\) 只奶牛比他矮,那么这只奶牛的身高就是在除去已经确定的身高后,可能的身高中的第 \(a_i+1\) 小数。
而如果我们维护一个 \(01\) 序列,其中第 \(i\) 个数为 \(1\) 表示 \(i\) 这个身高还没有确定的奶牛。而如果我们统计一下前 \(i\) 个数的前缀和 \(s_i\),那么身高 \(i\) 在没有确定的身高内排第 \(s_i\) 小。同时显然这个前缀和具有单调性,那么就可以用二分的方法快速找出在未确定的身高中第 \(k\) 大的数,同时为了快速查找前缀和。就可以用树状数组维护这个 \(01\) 序列。
最终的时间复杂度就是 \(O(n\log^2 n)\)。
code:
#include<cstdio>
using namespace std;
const int N=1e5+10;
int c[N],a[N],n,ans[N];
int lowbit(int x){return x&(-x);}
void add(int x,int k)
{
while(x<=n)
{
c[x]+=k;
x+=lowbit(x);
}
}
int query(int x)
{
int res=0;
while(x)
{
res+=c[x];
x-=lowbit(x);
}
return res;
}
int find(int k)
{
int l=1,r=n;
while(l<r)
{
int mid=l+r>>1;
if(query(mid)>=k) r=mid;
else l=mid+1;
}
return l;
}
int main()
{
scanf("%d",&n);
add(1,1);
for(int i=2;i<=n;i++) scanf("%d",&a[i]),add(i,1);
for(int i=n;i>=1;i--)
{
ans[i]=find(a[i]+1);
add(ans[i],-1);
}
for(int i=1;i<=n;i++) printf("%d\n",ans[i]);
return 0;
}
[GZOI2017]配对统计
树状数组题的难点在于想到可以用树状数组做。
题意
给定 \(n\) 个正整数,对于一组匹配 \((x,y)\),如果对于任意的 \(i=1,2,⋯,n\),满足 \(|a_x-a_y| \leq |a_x-a_i|(i \ne x)\)。那么就称 \((x,y)\) 为一组好的匹配。
给出 \(m\) 询问,每次询问区间 \([l,r]\) 中好的匹配的数量。
记第 \(i\) 次询问的答案为 \(ans_i\),那么最终只需输出 \(\sum_{i=1}^{m} ans_i*i\)。
思路
首先观察题目中对于“好的匹配”的定义,可以发现。对于一个数 \(a_x\) ,能和它组成好的匹配的数 \(a_y\) 一定满足 \(|a_x-a_y|\) 的值最小,也就是 \(a_y\) 是与 \(a_x\) 相差最小的数。于是就可以想到排序,将原数组排序后,对于任意的 \(i=2,3,⋯,i-2,i-1\)。能和 \(a_i\) 组成好的匹配的数一定在 \(a_{i-1}\) 和 \(a_{i+1}\) 中(\(a[1]\) 和 \(a[n]\) 需要特判) 。于是就可以在 \(O(n \log n)\) 的时间内求出所有的好的匹配。
然而对于题目中的查询操作。有一个很 navie 的想法:用树状数组 \(c[x]\) 维护区间 \([1,x]\) 内的配对数量,对于每一个 \((x,y)\)(设 \(x<y\) 的),直接 $ add(y,1) $。在查询的时候输出 \(query(r)-query(l-1)\) 。
可惜这样的想法是错误的,因为在相减的时候只减去了 \(x<l,y<l\) 时的不合法配对,并没有减去 \(x<l,y>l\) 时的不合法配对。
注意到本题中并未要求支持修改操作,于是可以考虑离线做法。
上述错误做法出现的问题是并未减去 \(x<l,y>l\) 时的不合法配对。如果将 \(add(y,l)\) 改成 \(add(l,1)\),可以发现当 \(r=n\) 时,\(query(r)-query(l-1)\) 得到的答案就是正确的了,因为此时的 \(query(l-1)\) 中只限制了 \(x<l\),而 \(y \geq l\)的配对也被计算在其中。
但是一旦当 \(r < n\) 时,这样的做法又是错误的,因为此时的 \(query(r)\) 的 \(y\) 可以比 \(r\) 还大。相减时无法减去这些不合法匹配。
那如果在树状数组中不保存这些不合法匹配呢?
于是可以想到先将配对按照 \(y\) 的大小进行排序,将所有的询问先记录下来,再按照右端点 \(r\) 的大小进行排序。在求解每一次询问时,都只把 \(y \leq r\) 的配对记录到树状数组中。这样就避免了 \(r >y\) 的不合法匹配。再将已经记录到树状数组中的配对的数量减去 \(x \ l\) 的不合法匹配,就可以得到正确答案了。
还有一些实现上的细节见代码。
最后,别忘了开 long long。
code:
#include<cstdio>
#include<algorithm>
using namespace std;
#define LL long long
const int N=3e5+10;
const int M=3e5+10;
int n,m,c[N];
LL ans;
struct node{
int val,id;
bool operator <(const node &t)const{
return val<t.val;
}
}a[N];
struct match{
int l,r;
bool operator <(const match &t)const{
if(r!=t.r)return r<t.r;
return l<t.l;
}
}p[N<<1];//除了最大和最小的数,极端情况下每个数都能有两个好的匹配,所以数组大小要*2
int tot=0;
struct quest{
int l,r,id;
bool operator <(const quest &t)const{
if(r!=t.r)return r<t.r;
return l<t.l;
}
}q[M];
int max(int a,int b){return a>b?a:b;}
int min(int a,int b){return a<b?a:b;}
int lowbit(int x){return x&(-x);}
void updata(int x,int k)
{
for(int i=x;i<=n;i+=lowbit(i)) c[i]+=k;
}
int query(int x)
{
int res=0;
for(int i=x;i;i-=lowbit(i)) res+=c[i];
return res;
}
void add(int a,int b)
{
p[++tot].l=min(a,b);
p[tot].r=max(a,b);
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++) scanf("%d",&a[i].val),a[i].id=i;
sort(a+1,a+n+1);
for(int i=2;i<n;i++)
{
int res1=a[i].val-a[i-1].val,res2=a[i+1].val-a[i].val;
if(res1<res2) add(a[i].id,a[i-1].id);
else if(res1>res2) add(a[i].id,a[i+1].id);
else add(a[i].id,a[i-1].id),add(a[i].id,a[i+1].id);//当两边都相等时当然就都是好的匹配
}
add(a[1].id,a[2].id);
add(a[n-1].id,a[n].id);//特判
sort(p+1,p+tot+1);
for(int i=1;i<=m;i++) scanf("%d%d",&q[i].l,&q[i].r),q[i].id=i;//别忘了记录是第几个询问,最终的答案还要*i
sort(q+1,q+m+1);
int now=1;
for(int i=1;i<=m;i++)
{
while(p[now].r<=q[i].r&&now<=tot) updata(p[now++].l,1);
ans+=(LL)q[i].id*(now-1-query(q[i].l-1));//因为出循环时的匹配是不合法的,所以实际已记录的匹配数量为now-1
}
printf("%lld\n",ans);
return 0;
}
[eJOI2019]异或橙子
异或前缀和问题。
题意
给出一个整数序列 \(a\) ,要求支持两种操作,单点修改和询问在 \([l,r]\) 中所有的子区间异或值的异或和。如当 \(l=1,r=3\) 时,最终的答案就是 \(a_1 \wedge a_2 \wedge a_3 \wedge(a_1 \wedge a_2)\wedge(a_2 \wedge a_3)\wedge(a_1 \wedge a_2 \wedge a_3)\) 。
思路
首先需要知道一些关于异或的前置芝士。
\(a \wedge a=0,a \wedge 0=a\)。
异或运算既满足结合律,又满足交换律。
回到本题上来,对于每一个区间,可以统计一下每个数出现的次数。(为了方便,以下用 \(|x|\) 表示 \(x\) 出现的次数,用 \(ans\) 表示询问的答案)如:
当 \(l=1,r=3\) 时,\(|a_1|=3,|a_2|=4,|a_3|=3,ans=a_1 \wedge a_3\)。
当 \(l=1,r=4\) 时,\(|a_1|=4,|a_2|=6,|a_3|=6,|a_4|=4,ans=0\)。
当 \(l=1,r=4\) 时,\(|a_1|=5,|a_2|=6,|a_3|=7,|a_4|=6,|a_5|=5,ans=a_1 \wedge a_3 \wedge a_5\)。
于是就可以大胆地猜想。当区间长度为偶数时,\(ans=0\)。
因为当区间长度为偶数时,每一个数都出现了偶数次,自然答案就为 \(0\)。
而当区间长度为奇数时,下标和区间端点下标奇偶性相同的数出现了奇数次。不相同的出现了偶数次。于是 \(ans=a_l \wedge a_{l+2} \wedge...\wedge a_{r-2} \wedge a_r\)。
于是可以用两个前缀和数组分别存储下标为奇数和偶数的数的异或前缀和。
同时题目中要求单点修改,于是就可以用树状数组来维护前缀和。但是需要注意,在将 \(a[x]\) 修改为 \(y\) 时,不能直接 \(add(x,y)\),因为这样子只是多 \(\wedge y\) ,并没有删去 \(a[x]\),因此需要 \(add(x,a[x]^y)\),让 \(a[x] \wedge a[x]\),也就是删去这个数。
code:
#include<cstdio>
using namespace std;
const int N=2e5+10;
int lowbit(int x){return x&-x;}
int n,q,c[2][N],a[N];
int max(int a,int b){return a>b?a:b;}
void updata(int c[],int x,int k){for(int i=x;i<=n;i+=lowbit(i)) c[i]^=k;}
int query(int c[],int x){int res=0;for(int i=x;i;i-=lowbit(i)) res^=c[i];return res;}
int main()
{
scanf("%d%d",&n,&q);
for(int i=1;i<=n;i++) scanf("%d",&a[i]),updata(c[i&1],i,a[i]);
while(q--)
{
int opt,l,r;
scanf("%d%d%d",&opt,&l,&r);
if(opt==1) updata(c[l&1],l,a[l]^r),a[l]=r;
else
{
if((r-l+1)&1)
{
printf("%d\n",query(c[l&1],r)^query(c[l&1],l-1)); //奇数
}
else puts("0");
}
}
return 0;
}
标签:wedge,树状,int,lowbit,笔记,数组,区间 来源: https://www.cnblogs.com/NLCAKIOI/p/14930141.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。