mysql初始化密码常见报错问题mysql5.6是密码为空直接进入数据库的,但是mysql5.7就需要初始密码 cat /var/log/mysqld.log | grep password 然后执行 mysql -uroot -p ,输入上面的到的密码进入,用该密码登录后,必须马上修改新的密码,不然会报如下错误: mysql> use mysql;ERROR 1820 (HY00
本文讲述的知识蒸馏基于迁移学习所展开,所以对迁移学习(教师网络)中的一些细节有所要求,具体请见深度学习3 使用keras进行迁移学习,主要是指对教师网络的最后一个dense层不能使用激活函数,应添加一个激活层进行激活输出,这样子方便移除激活函数,自行对数据进行升温,然后再激活。 1、导入
Android系统会有各种各样的xml配置文件存在。本文重点是列出来,供各位查看。想到啥更新啥! 1.通知策略(用于systemUI通知的显示) 实机里位置:data/system/notification_policy.xml 2.勿扰模式 源码里位置:\android\frameworks\base\core\res\res\xml\default_zen_mode_config.xml
参考资料: 书籍《ASP.NET Core IN ACTION SECOND EDITION》ch14、ch15 0. 照例吐槽 1. 什么是认证 Authentication 和授权 Authorization 2. ASP.NET Core 中的 users 和 claims Principal Claims 3. 认证和授权的抽象过程 Authentication 中间件和 Authorization 中间件在
发表时间:2021 文章要点:这篇文章把RL看作序列建模问题(sequence modeling problem),直接用transformer来拟合整个序列 (reats states, actions, and rewards as simply a stream of data,其实还拟合了reward-to-to return),拟合完了后就直接用这个transformer来做预测,中间还用了beam sea
App Privacy Policy This application does not collect or transmit any user's personally identifiable information. No personal information is used, stored, secured or disclosed by services this application works with.Technical information No technical
kind: CustomResourceDefinition [root@bogon deploy]# grep 'kind: CustomResourceDefinition' -rn * cluster.karmada.io_clusters.yaml:4:kind: CustomResourceDefinition multicluster.x-k8s.io_serviceexports.yaml:15:kind: CustomResourceDefinition mult
今天在为项目编写API统一返回结果的代码时,发现不能通过Filter来定义授权失败后的响应结果,于是我翻看了一下官方文档和aspnetcore源码,原来需要自定义实现IAuthorizationMiddlewareResultHandler接口。 Asp.Net Core 5自带的验权中间件,在验权失败后,是直接返回一个401。这对
发表时间:2021 文章要点:文章想说,在动作空间很大或者连续的时候,想要枚举所有动作来做MCTS是不现实的。作者提出了sample-based policy iteration framework,通过采用的方式来做MCTS(Sampled MuZero)。大概思路就是说,在MCTS里面扩展动作的时候,并不枚举所有动作,而是取一个动作子集来作为
发表时间:2021 文章要点:文章接着muzero做的,当时muzero里面提出了一个MuZero Reanalyze(Reanalyse)的方式,这篇文章提出的MuZero Unplugged算法其实就是把MuZero Reanalyse用到offline RL里面。作者想说的就是这个方法不仅可以用在online RL上,在offline RL上同样表现很好,相当于一个算
基本使用 1.创建生命周期策略 PUT _ilm/policy/yztest-policy { "policy": { "phases": { "hot": { "min_age": "0ms", "actions": { "rollover": { "max
文章目录 前言1. 行为价值函数的重要性2. ϵ−贪婪策略 (ϵ−greedy policy)3. 现时策略蒙特卡罗控制 (On-policy MC Control)4. 现时策略时序差分控制 (On-policy TD Control)4.1 Sarsa 算法4.2 Sarsa(λ) 算法 5. 借鉴策略 Q 学习算法 (Off-policy TD Control: Q-learnin
R1换环回重发布引入ospf R4.R6进行双点双向重发布 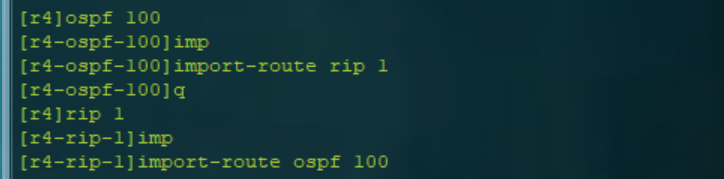 R4.R6路由表 解决环路 在R6抓取91.1.1.1路由 [r6]ip ip-prefix a1 permit 91.1.1.1 24 [r6]route-policy b1 deny node 10 Info: New Sequence
要求: 1.如图搭建网络拓扑,所有路由器各自创建一个环回接口,合理规划IP地址 2.R1-R2-R3-R4-R6之间使用OSPF协议,R4- R5-R6之间使用RIP协议 3.R1环回重发布方式引入OSPF网络 4.R4/R6上进行双点双向重发布 5.分析网络中出现路由环路的原因 6.路由优化,全网可达 R1环回重发布方式引
BGP聚合实验 如下拓扑: 基本配置 # AR2基础配置 sysname AR2 # interface GigabitEthernet0/0/0 ip address 12.1.1.2 255.255.255.0 # interface LoopBack0 ip address 2.2.2.1 255.255.255.255 # interface LoopBack1 ip address 2.2.2.2 255.255.255.255 #
一、双写一致性 双写一致性,也就是说 Redis 和 mysql 数据同步 双写一致性数据同步的方案有: 1、先更新数据库,再更新缓存 这个方案一般不用: 因为当有两个请求AB先后更新数据库后,A应该先更新缓存,但是因为网络原因,B却先更新了缓存,导致了脏数据,所以不考虑用。 2、先删缓存,再更新数据库
Reinforcement Learning (RL) is one of the most exciting fields of Machine Learning today, and also one of the oldest. It has been around since the 1950s, producing many interesting applications over the years,(For more details, be sure to check out
在我们实施微服务之后,服务间的调用变的异常频繁。多个服务之间可能是互相依赖的关系。某个服务出现故障或者是服务间的网络出现故障都会造成服务调用的失败,进而影响到某个业务服务处理失败。某一个服务调用失败轻则造成当前相关业务无法处理;重则可能耗尽资源而拉垮整个应用。为了
发表时间:2019 文章要点:这篇文章主要想把actor-critic方法里面加个replay buffer来提高采样效率。先是分析了把actor-critic变成off-policy的过程中需要做的修正,主要是importance sampling和V-trace,以及即使这样也会产生误差。然后就说把off-policy的数据混合on-policy的数据一起训
发表时间:2016(NIPS 2016) 文章要点:提出了一种新的在off-policy算法中修正behavior policy和target policy的方法:Retrace(λ)。最常见的修正当然是importance sampling,这个方式不仅用在value based方法中,在policy based方法中也最常用。除此之外,在value based 方法中还有Q(λ)和TB(λ)。
全文阅读:https://www.lianxh.cn/news/d6fc0275d8995.html 目录 IntroductionA small DSGE modelSpecifying the DSGE to dsgeImpulse–responsesConclusion 今天,在 Stata Blog 看到了一篇文章,使用一个简单范例介绍了 Stata 中如何估计 DSGE 模型的参数。 Source: Estimatin
目的:重发布实验 原因:优先级的问题 重发布的ospf的优先级为:150,而rip的优先级围为:100 选路是更据优先级来的,所以产生了选路不佳的问题 第一种方法: 过滤掉此路由 步骤: 写入 ip ip-prefix 1 拒绝学习5.5.5.5的路由 进入rip协议,启用此条规则 第二种方法: 1:写入规则 ip ip-prefix
uvm_mem_mam的用法: 1. 几个相关的class: uvm_mem_mam uvm_mem_mam_cfg : 用来配置uvm_mem_mam,在uvm_mem_man.new()的时候引入; uvm_mem_mam_policy: 在分配memory空间的时候用; 一般情况下需要重新定义一下; class pcie_mem_man_policy extends uvm_mem_mam_policy; bit
2.2.4. PE4上将Loopback0地址引入OSPF。AS 200中,各OSPF网元到PE4的Loopback0的路由,要包含内部的cost。 解法:在PE4上引入Loopback0接口的直连路由,由于router-policy不匹配Loopback接口,使用地址前缀来匹配Loopback0接口的路由。 ip ip-prefix 1 index 10 permit 172.16.1.2 32 great
打开 API portal,找到要编辑的 API,点击打开,进入明细页面: 点击 Policies: 在策略编辑器的右侧,您可以看到开箱即用的策略,可帮助您为您的用例选择策略。所有安全策略都分组在安全下,类似的流量管理策略、中介策略和扩展策略也相应地分组。 策略编辑器的左侧有 Flows,PreFlow 和 PostFl