标签:
1,引言
- 本次测试的环境是:Windows10, Python3.4.3 32bit
- 安装Scrapy : $ pip install Scrapy #实际安装时,由于服务器状态的不稳定,出现好几次中途退出的情况
3,编写运行第一个Scrapy爬虫
3.1. 生成一个新项目:tutorial
$ scrapy startproject tutorial
项目目录结构如下:
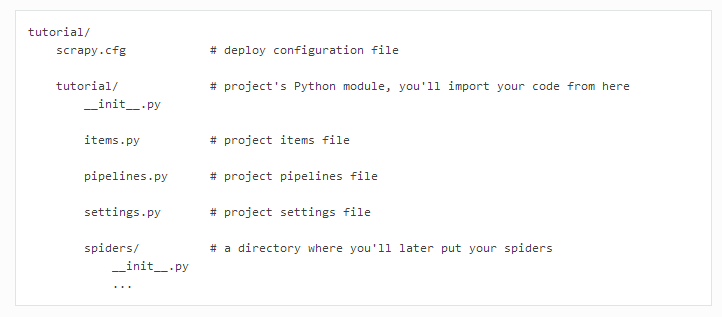 3.2. 定义要抓取的item
3.2. 定义要抓取的item# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
3.3. 定义Spiderimport scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath('//ul/li'):
item = DmozItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item
3.4. 运行
$ scrapy crawl dmoz -o item.json
1) 结果报错:
A) ImportError: cannot import name '_win32stdio'
B) ImportError: No module named 'win32api'
3) 解决过程:
A) 需要手工去下载
twisted/internet下的 _win32stdio 和 _pollingfile,存放到python目录的lib\sitepackages\twisted\internet下
B) 下载并安装
pywin32再次运行,成功!在控制台上可以看到scrapy的输出信息,待运行完成退出后,到项目目录打开结果文件items.json, 可以看到里面以json格式存储的爬取结果。
[
{"title": [" About "], "desc": [" ", " "], "link": ["/docs/en/about.html"]},
{"title": [" Become an Editor "], "desc": [" ", " "], "link": ["/docs/en/help/become.html"]},
{"title": [" Suggest a Site "], "desc": [" ", " "], "link": ["/docs/en/add.html"]},
{"title": [" Help "], "desc": [" ", " "], "link": ["/docs/en/help/helpmain.html"]},
{"title": [" Login "], "desc": [" ", " "], "link": ["/editors/"]},
{"title": [], "desc": [" ", " Share via Facebook "], "link": []},
{"title": [], "desc": [" ", " Share via Twitter "], "link": []},
{"title": [], "desc": [" ", " Share via LinkedIn "], "link": []},
{"title": [], "desc": [" ", " Share via e-Mail "], "link": []},
{"title": [], "desc": [" ", " "], "link": []},
{"title": [], "desc": [" ", " "], "link": []},
{"title": [" About "], "desc": [" ", " "], "link": ["/docs/en/about.html"]},
{"title": [" Become an Editor "], "desc": [" ", " "], "link": ["/docs/en/help/become.html"]},
{"title": [" Suggest a Site "], "desc": [" ", " "], "link": ["/docs/en/add.html"]},
{"title": [" Help "], "desc": [" ", " "], "link": ["/docs/en/help/helpmain.html"]},
{"title": [" Login "], "desc": [" ", " "], "link": ["/editors/"]},
{"title": [], "desc": [" ", " Share via Facebook "], "link": []},
{"title": [], "desc": [" ", " Share via Twitter "], "link": []},
{"title": [], "desc": [" ", " Share via LinkedIn "], "link": []},
{"title": [], "desc": [" ", " Share via e-Mail "], "link": []},
{"title": [], "desc": [" ", " "], "link": []},
{"title": [], "desc": [" ", " "], "link": []}
]
第一次运行scrapy的测试成功。4,接下来的工作
接下来,我将使用GooSeeker API来实现网络爬虫,省掉对每个item人工去生成和测试xpath的工作量。目前有2个计划:
- 在gsExtractor中封装一个方法:从xslt内容中自动提取每个item的xpath
- 从gsExtractor的提取结果中自动提取每个item的结果
5,文档修改历史
2016-11-04:V1.0,首次发布
标签: 来源: http://gooseeker.blogspot.com/2016/11/apipythonfirefox.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。