GAN 学习笔记
生成模型
什么是生成模型?
- GMM: 用来做聚类,(非监督学习)
- NB(朴素贝叶斯):(监督学习,可以用来做垃圾邮件分类)
- Logistics 回归是生成模型吗?No!
生成模型与解决的任务之间没有必然的联系,关注的是样本本身。对于监督学习\(p(x, y)\) , 非监督学习 \(p(x,z)\) , 有些模型甚至仅用 \(X\) , 成为 Autoregression model 。
GAN(生成式对抗网络)
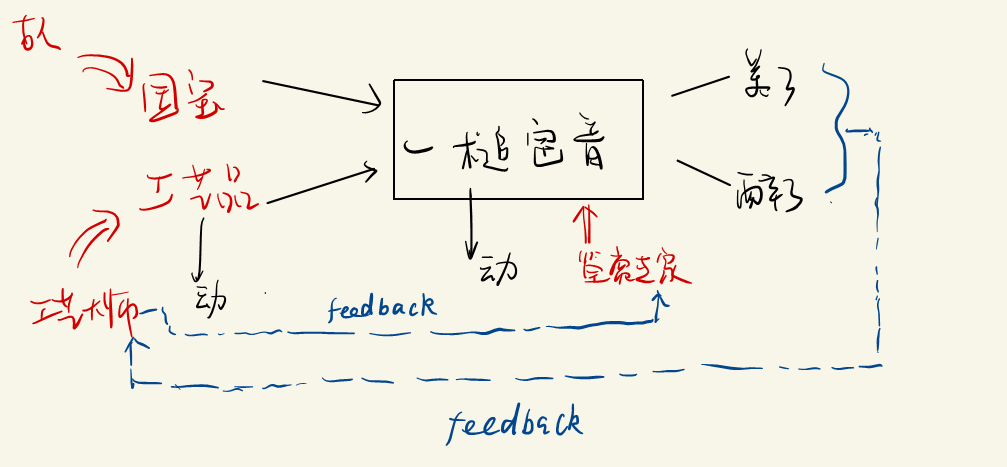
- 工艺大师的目的:成为高水平,可以以假乱真的大师。($P_g \rightarrow P_d $)
如果用统计模型去刻画这个模型,如何去表示?模型中的生成器和判别器可以通过一些模型去表示。
GAN的流程:
- Initialize the generator and dicriminator
- In each traning iteration
- Step 1 : Fixed generator G , and update discriminator D.
- Step 2 : Fixed Discriminator D , and update generator G ;
Auto - Encoder
graph LR A[Random Generator] -->C(N.N) F(A vector as code) --> C(N.N Decoder) C --> D[N.N Decoder] -->G[Image]VAE
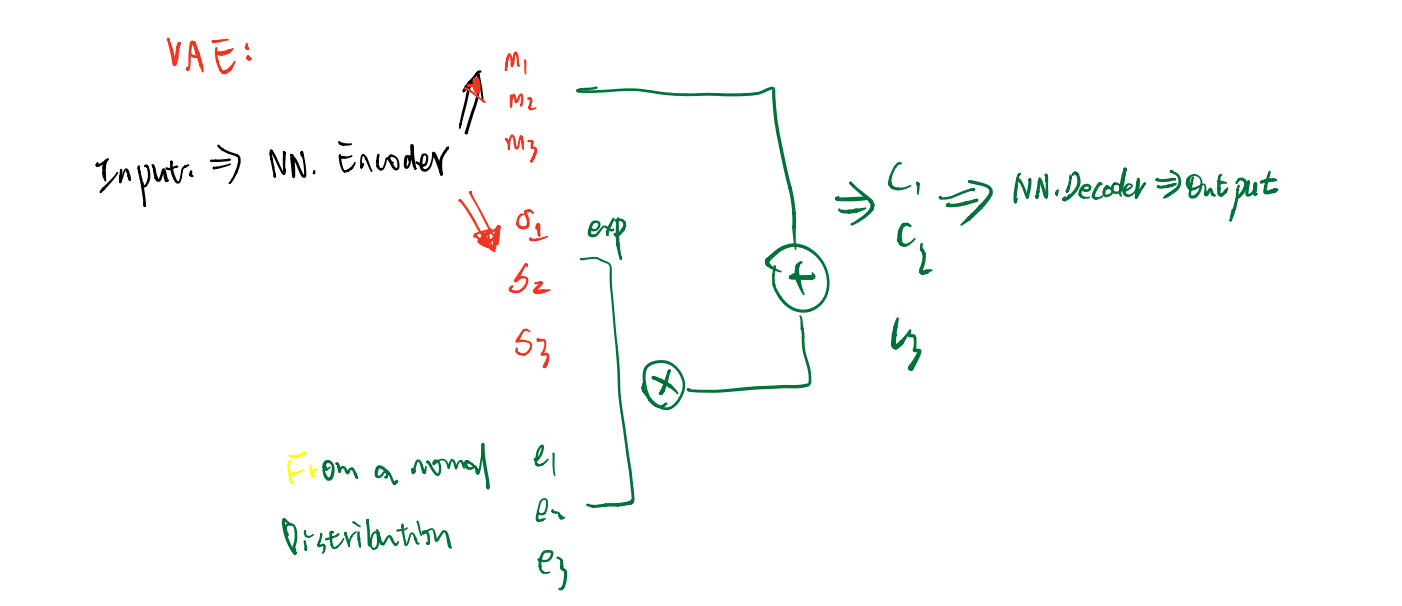
这里会对 \(\sigma\) 进行限制:
\[\min ~ \sum_{i} ^{3} \left[ exp(\sigma_{i}) - (1+\sigma_{i}) + m_{i}^{2} \right] \]VAE存在着一些问题:它不能真的尝试去模拟真的图像
GAN——数学表示
数学符号:
-
\(\{x_{i}\}_{i}^{N}\) 样本数据
-
\(P_{data}:\) Population Density
-
\(P_g(x;\theta_{g}):\) 生成模型的density; 可以用
NN进行逼近 -
\(z \sim P_{Z}(Z)\) , Proposed Density,一般用来生成 \(\tilde{x}_{i}\)
-
\(D(Z) = D(\tilde{x},\theta_{d}):\) 表示 Discrimination 识别是否是“国宝”的概率,越接近于1,越可能是国宝
-
\(\tilde{x} = G(z;\theta_g)\)
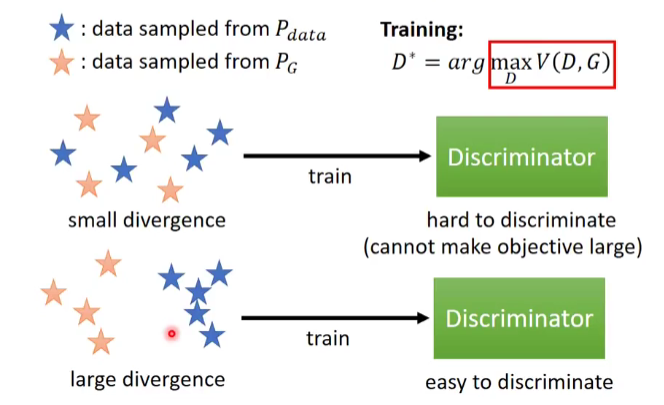
对于高专家来说:
- 如果 \(x\) 是来自于 \(P_{data}\) , 我们可以发现 \(D(x;\theta_{d})\)是较大的 \(\Longrightarrow\) \(\log(D(x;\theta_{d}))\) 是较大点的;
- 如果 \(x\) 是来自于 \(P_{generator}\) , 我们可以发现 \(D(x;\theta_{d})\)是较小的 \(\Longrightarrow\) \(1 - D(x;\theta_{d})\)是较大点的\(\Longrightarrow\) \(\log(1 -D(G(Z))\)是较大的;
所以对于高专家的目标函数为:
\[\max_{D} \rm E_{x \sim P_{data}} [~\log P(x)~] + E_{z \sim P_{z}} [~ \log (1 - D(Z))~] \]对于高级技师来说,想以假乱真:
- 如果 \(x\) 是来自于 \(P_{generative}\) , 我们可以高级技师希望 \(D(x;\theta_{d})\)是较大的 \(\Longrightarrow\) \(\log(1 -D(G(Z))\)是较小的;
所以在这个体系中,总的目标为:
\[\min_{G} \max_{D} ~ \rm E_{x \sim P_{data}} [~\log P(x)~] + E_{z \sim P_{z}} [~ \log (1 - D(Z))~] \]小结:GAN的复杂度在于模型的学习,我们并没有直接面对\(P_g (x , \theta_{g})\) ,而是用神经网络去逼近\(P_g (x , \theta_{g})\) ,所以GAN是一种 Implict Density Model 。
标签:log,--,模型,学习,GAN,theta,sim 来源: https://www.cnblogs.com/RankFan/p/14698932.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。