标签:cgroups 隔离 cpuacct 控制组 sys cgroup usage Docker cpu
作用
cgroups(controll groups)可以把一系列系统任务及其子任务(线程/进程)划分为等级不同的组,从而对任务组使用的物理资源(CPU、内存、IO等)进行限制和记录。
- 资源限制:对任务使用的资源总额进行限制,一旦超过这个配额就发出相关提示;
- 优先级分配:通过分配的CPU时间片数量及磁盘IO带宽大小,实际上就相当于控制了任务运行的优先级;
- 资源统计:cgroups可以统计系统的资源使用量,如CPU使用时长,内存用量等;
- 任务控制:cgroups可以对任务执行挂起、恢复等操作。
组织结构
cgroups的组织结构中有以下几种元素:
-
任务(task):系统的一个进程或线程;
-
控制组(cgroup):按某种资源控制标准划分而成的任务组,一个任务可以加入某个cgroup,也可以在不同cgroup中迁移;
-
子系统(subsystem):即资源调度器,如CPU子系统可以控制CPU时间分配;
-
层级(hierarchy):由一系列控制组以一个树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制。
它们之间的关系需要遵循一定的规则:
- 同一个层级可以绑定多个子系统;
- 一个已经有层级绑定的子系统,不能附加到其他含有别的子系统的层级之上;
- 一个任务不能存在于同一层级的不同控制组中;
- 调用fork()或clone()方法后,父子任务(进程)的控制组互不影响。
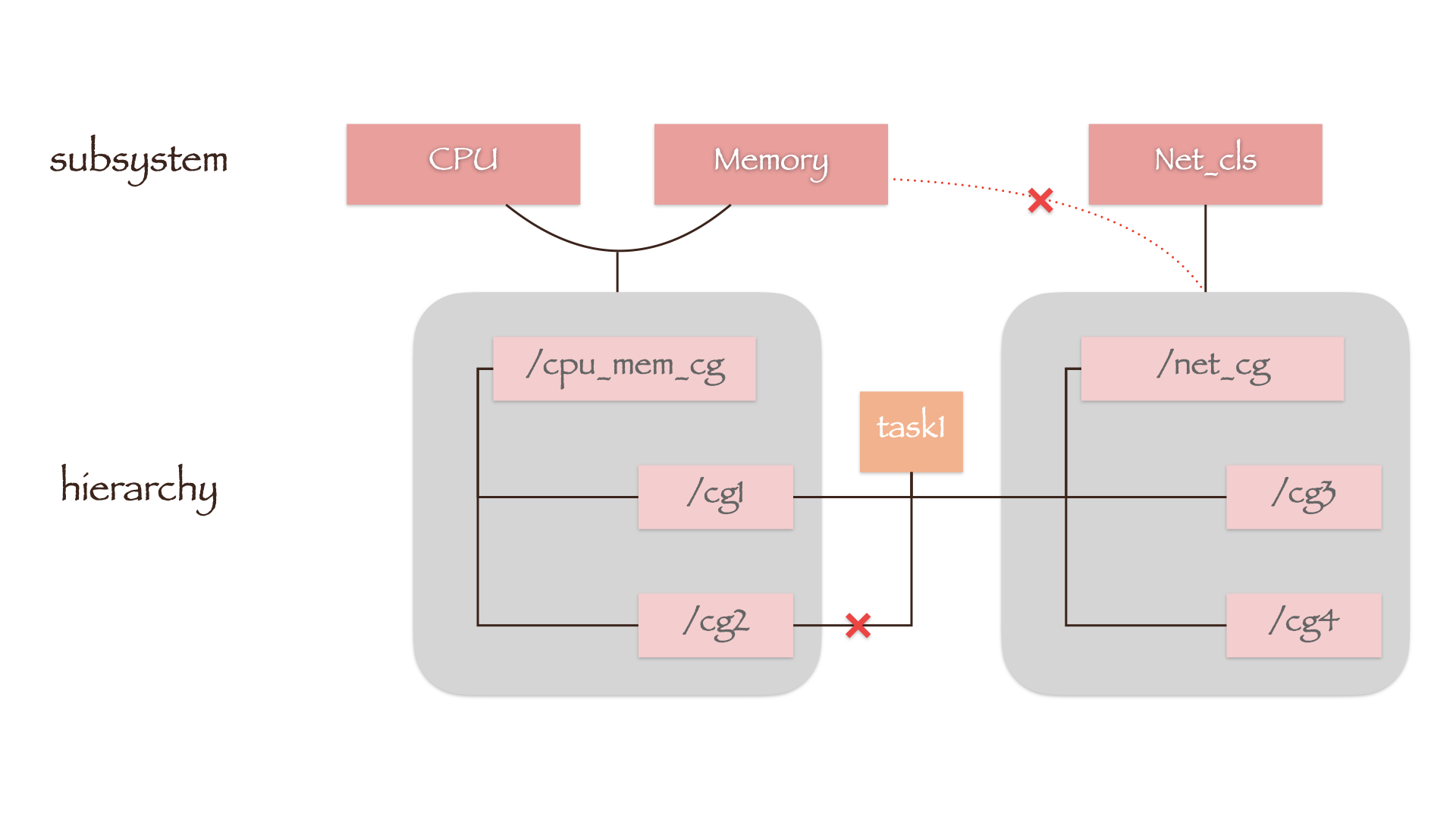
在上图的cgroups结构中,左侧的层级同时绑定了CPU子系统和Memory子系统;由于此时Memory子系统已经有层级绑定,因此无法附加到一个已经绑定了Net_ls子系统的层级上;如果任务task1处于左侧层级下的cg1控制组中,那么便无法加入同一层级下的cg2控制组,但是可以加入右侧层级的cg3控制中。
实现
cgroup的实现形式表现为一个文件系统,可以通过mount -t cgroup命令查看各种子系统的挂载情况:
[root@koktlzz ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
以CPU子系统为例,若在其挂载的目录下创建一个目录newcg,那么便创建了一个新的控制组且系统会自动在其中生成一些的控制组文件:
[root@koktlzz ~]# cd /sys/fs/cgroup/cpu
[root@koktlzz cpu]# mkdir newcg
[root@koktlzz cpu]# ls newcg
cgroup.clone_children cpuacct.usage_all cpuacct.usage_sys cpu.rt_period_us notify_on_release
cgroup.procs cpuacct.usage_percpu cpuacct.usage_user cpu.rt_runtime_us tasks
cpuacct.stat cpuacct.usage_percpu_sys cpu.cfs_period_us cpu.shares
cpuacct.usage cpuacct.usage_percpu_user cpu.cfs_quota_us cpu.stat
而CPU子系统的挂载目录中,本身就包含了这类文件。同时还有一些控制组目录,如docker:
[root@koktlzz cpu]# ls /sys/fs/cgroup/cpu
assist cpuacct.usage cpuacct.usage_sys cpu.rt_runtime_us newcg user.slice
cgroup.clone_children cpuacct.usage_all cpuacct.usage_user cpu.shares notify_on_release
cgroup.procs cpuacct.usage_percpu cpu.cfs_period_us cpu.stat release_agent
cgroup.sane_behavior cpuacct.usage_percpu_sys cpu.cfs_quota_us docker system.slice
cpuacct.stat cpuacct.usage_percpu_user cpu.rt_period_us init.scope tasks
Docker daemon首先会在子系统的挂载目录下创建一个名为docker的控制组,然后在docker控制组中再为每个容器创建一个以容器id命名的子控制组。即使上层控制组的文件系统被卸载,下层的子控制组配置依然有效。docker控制组的层级结构如下所示:
[root@koktlzz docker]# tree /sys/fs/cgroup/cpu/docker
/sys/fs/cgroup/cpu/docker
├── cgroup.clone_children
├── cgroup.procs
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_all
├── cpuacct.usage_percpu
├── cpuacct.usage_percpu_sys
├── cpuacct.usage_percpu_user
├── cpuacct.usage_sys
├── cpuacct.usage_user
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.rt_period_us
├── cpu.rt_runtime_us
├── cpu.shares
├── cpu.stat
├── d682e9c84e04ebe41461fdf3aa6d22903c68cf2260218d1051af13e2bb1a0edd
│ ├── cgroup.clone_children
│ ├── cgroup.procs
│ ├── cpuacct.stat
│ ├── cpuacct.usage
│ ├── cpuacct.usage_all
│ ├── cpuacct.usage_percpu
│ ├── cpuacct.usage_percpu_sys
│ ├── cpuacct.usage_percpu_user
│ ├── cpuacct.usage_sys
│ ├── cpuacct.usage_user
│ ├── cpu.cfs_period_us
│ ├── cpu.cfs_quota_us
│ ├── cpu.rt_period_us
│ ├── cpu.rt_runtime_us
│ ├── cpu.shares
│ ├── cpu.stat
│ ├── notify_on_release
│ └── tasks
├── notify_on_release
└── tasks
其中的d682e9c84e04ebe41461fdf3aa6d22903c68cf2260218d1051af13e2bb1a0edd控制组是一个正在运行的nginx容器id:
[root@koktlzz docker]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d682e9c84e04 nginx "/docker-entrypoint.…" 2 days ago Up 2 days 0.0.0.0:80->80/tcp nginx
这个容器内的进程pid都会写入到该控制组的tasks目录中,把任务的TID(即线程或进程的id)写入到这个文件就意味着将这个任务加入到该控制组中:
[root@koktlzz docker]# cat d682e9c84e04ebe41461fdf3aa6d22903c68cf2260218d1051af13e2bb1a0edd/tasks
2452208
2452318
[root@koktlzz docker]# ps -ef | grep 2452208
UID PID PPID C STIME TTY TIME CMD
root 2452208 2452188 0 1月29 ? 00:00:00 nginx: master process nginx -g daemon off;
101 2452318 2452208 0 1月29 ? 00:00:00 nginx: worker process
root 2689799 2687314 0 02:29 pts/0 00:00:00 grep --color=auto 2452208
Docker daemon通过在控制文件(如cpu.cfs_quata_us)中写入预设的资源配额实现cgroups的限制功能,其中5000代表限制CPU的最高使用率为50%:
[root@koktlzz docker]# docker run -d --cpu-quota=50000 nginx
85ff8f8f779067c4938a011420d9afdb76baa3f69b17d76c0cfe9b8f716b228f
[root@koktlzz docker]# cat 85ff8f8f779067c4938a011420d9afdb76baa3f69b17d76c0cfe9b8f716b228f/cpu.cfs_quota_us
50000
标签:cgroups,隔离,cpuacct,控制组,sys,cgroup,usage,Docker,cpu 来源: https://www.cnblogs.com/koktlzz/p/14354907.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。