标签:50000 10 df8 df 爬取 弹幕 opts 47687
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于菜J学Python ,作者J哥
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542

前言
最近由腾讯视频、爱奇艺联合出品综艺《哈哈哈哈哈》(又名五哈)话题不断,节目中由邓超、陈赫、鹿晗组成的兄弟旅行团,开启了一段由东到西穿越中国的真实旅行。作为首个双平台联播的超级网综,给广大观众带来了无限欢乐,妥妥登上了综艺热搜榜第一。
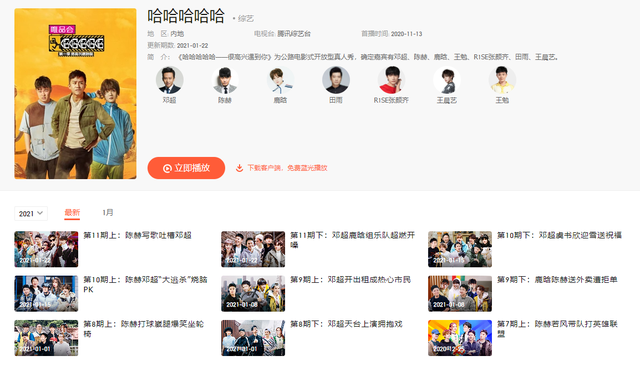

腾讯视频综艺热搜TOP3
本文通过爬取腾讯视频《哈哈哈哈哈》47687条弹幕,进行可视化分析和情感分析。
数据获取
《哈哈哈哈哈》目前已播出10期,本文爬取了第10期上下两篇弹幕。弹幕数据爬虫在往期原创文章中已详细讲解,本文不做赘述,以下给出完整代码:
#-*- coding = uft-8 -*-
import requests
import json
import time
import pandas as pd
df = pd.DataFrame()
for page in range(15, 3973, 30):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = 'https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id=6384458060%26vid%3Dd0035ka5c02&count=80'.format(page)
print("正在提取第" + str(page) + "页")
html = requests.get(url,headers = headers)
bs = json.loads(html.text,strict = False) #strict参数解决部分内容json格式解析报错
time.sleep(1)
#遍历获取目标字段
for i in bs['comments']:
name = i['opername'] #昵称
content = i['content'] #弹幕
upcount = i['upcount'] #点赞数
user_degree =i['uservip_degree'] #会员等级
timepoint = i['timepoint'] #发布时间
comment_id = i['commentid'] #弹幕id
cache = pd.DataFrame({'用户名':[name],'弹幕':[content],'会员等级':[user_degree],
'发布时间':[timepoint],'弹幕点赞':[upcount],'弹幕id':[comment_id]})
df = pd.concat([df,cache])
df.to_csv('haha-1.csv',encoding = 'utf-8')
print(df.shape)
数据处理
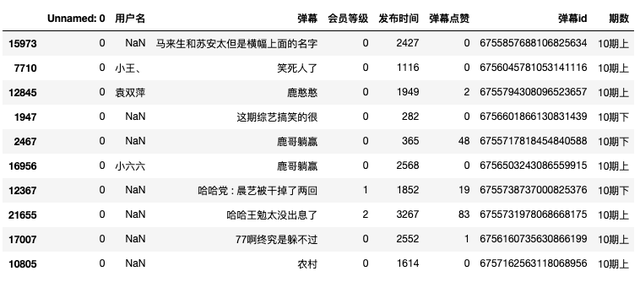
1.数据读取并预览
首先,将两个弹幕csv文件进行数据合并,采用concat方法。
import pandas as pd
import numpy as np
df1 = pd.read_csv("/弹幕/腾讯/哈哈哈哈哈/haha-1.csv")
df1["期数"] = "10期上"
df2 = pd.read_csv("/弹幕/腾讯/哈哈哈哈哈/haha-2.csv")
df2["期数"] = "10期下"
df = pd.concat([df1,df2])
df.sample(10)
抽样10条弹幕数据,预览效果如下:
2.查看数据信息
df.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 47687 entries, 0 to 21820 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Unnamed: 0 47687 non-null int64 1 用户名 13433 non-null object 2 弹幕 47687 non-null object 3 会员等级 47687 non-null int64 4 发布时间 47687 non-null int64 5 弹幕点赞 47687 non-null int64 6 弹幕id 47687 non-null int64 7 期数 47687 non-null object dtypes: int64(5), object(3) memory usage: 3.3+ MB
发现数据存在以下几个问题:
(1)字段名称可调整
(2)Unnamed、弹幕id字段多余
(3)用户名字段有缺失值,可填充
(4)发布时间字段类型需要调整
3.数据清洗
#重命名字段
df = df.rename(columns={'用户名':'用户昵称','弹幕':'弹幕内容','发布时间':'发送时间','评论点赞':'弹幕点赞','期数':'所属期数'})
#过滤不需要的字段
df = df[["用户昵称","弹幕内容","会员等级","发送时间","弹幕点赞","所属期数"]]
#缺失值填充
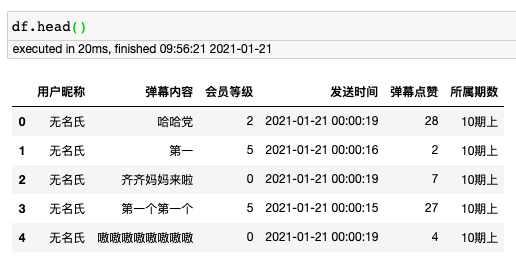
df["用户昵称"] = df["用户昵称"].fillna("无名氏")
清洗后,数据预览如下:
数据可视化
1.弹幕在讨论些什么
通过对4万+弹幕制作词云图,我们发现,弹幕中出现频率较高的词汇有「哈哈哈、鹿晗、晨艺、虞书欣」等。这综艺的初衷,是让观众在看节目的过程中频繁大笑,由弹幕可知,效果还是很明显的。鹿晗在这一期表现亮眼,躺赢刺杀游戏,被很多观众夸赞。

#绘制词云图
text1 = get_cut_words(content_series=df['弹幕内容'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=200,
collocations=False,
font_path='simhei.ttf',
icon_name='fas fa-video',
size=653,
#palette='matplotlib.Inferno_9',
output_name='./haha.png')
Image(filename='./haha.png')
2.弹幕里都提到了谁
鹿晗被观众提及7329次,王晨艺3222次,张颜齐1632次。鹿晗的吸粉体质为这个综艺带来了较大的流量,而陈赫在最新一期的节目中似乎被一些观众遗忘。
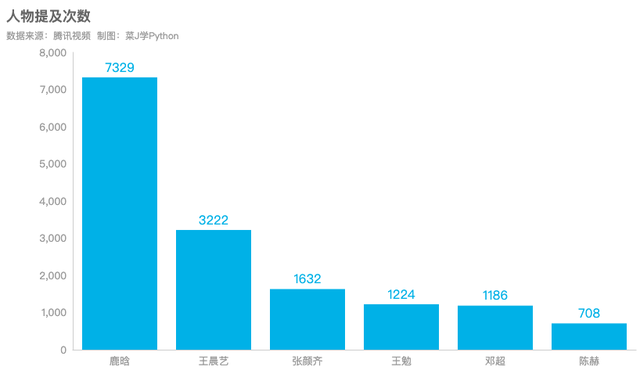
df8 = df["人物提及"].value_counts()[1:11]
print(df8.index.to_list())
print(df8.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WALDEN))
.add_xaxis(df8.index.to_list())
.add_yaxis("",df8.to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="人物提及次数",subtitle="数据来源:腾讯视频 \t制图:菜J学Python",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='top'))
)
c.render_notebook()
我们分别对六位主要提及演员进行词云图绘制,发现他们的人缘是真的好,几乎看不到负面的评价。陈赫的外号还挺多:赫赫、赫哥,不做词云我还不知道呢,看来J哥要补充知识点了。

3.谁是弹幕发射机
每天都是小春日和共发射弹幕158条,遥遥领先其他弹幕党,名副其实的弹幕发射机。想太多de猫紧随其后,发射了97条弹幕,如果大家还有印象的话,他(她)还是《令人心动的offer》第2季弹幕发射机。
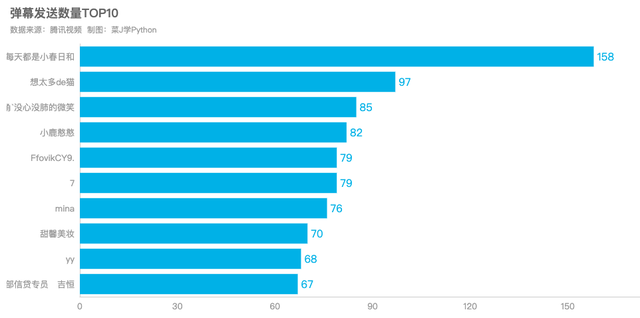
df8 = df["用户昵称"].value_counts()[1:11]
df8 = df8.sort_values(ascending=True)
df8 = df8.tail(10)
print(df8.index.to_list())
print(df8.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WALDEN,width="1100px",height="500px"))
.add_xaxis(df8.index.to_list())
.add_yaxis("",df8.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="弹幕发送数量TOP10",subtitle="数据来源:腾讯视频 \t制图:菜J学Python",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
#yaxis_opts=opts.AxisOpts(axislabel_opts={"rotate":40})#更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
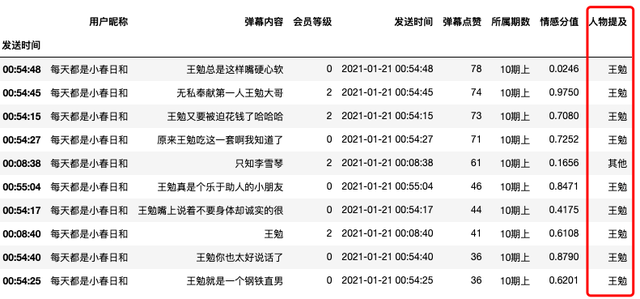
我们来看看弹幕发射机讨论了些啥,通过弹幕点赞数降序排列,筛选出点赞数最多的10条弹幕,弹幕内容几乎全为王勉相关内容,死忠粉无疑了。
df_first = df[df["用户昵称"]=="每天都是小春日和"]
df_first.sort_values('弹幕点赞',inplace=True,ascending=False)
df_first[:10]
标签:50000,10,df8,df,爬取,弹幕,opts,47687 来源: https://www.cnblogs.com/hhh188764/p/14313105.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。