标签:LCP 后缀 姐妹 笔记 len link endpos rk
目录后缀三姐妹 笔记
没错这是百合番(迫真)
符号
- \(\Sigma\) :字符集
- 设 \(s\) 是一个字符串,从 \(1\) 开始编号:
- \(|s|\):串 \(s\) 的长度
- \(s[l:r]\): \(s\) 的子串 \([l,r]\),\(l\) 和 \(1\) 取 \(\max\),\(r\) 和 \(|s|\) 取 \(\min\)
- \(s[p:]\): \(s\) 从 \(p\) 开始的后缀
- \(s[:p]\): \(s\) 到 \(p\) 为止的前缀
后缀数组 (Suffix Array / SA)
基本定义
将所有的后缀拿出来排个序,得到的就是后缀数组。一般我们会存几个数组
-
rk[i]:\(s[i:]\) 的排名 -
kth[i]:排名为 \(i\) 的后缀从哪里开始 -
height[i](代码写作ht[i]):\(LCP(s_{kth(i)},s_{kth(i-1)})\)
前两个是最基本的,第三个拿来求 \(LCP\),应用更广泛。
如何求
前两个:先求出来 \(rk\),然后 kth[rk[i]]=i 即可
考虑求 \(rk\):倍增法。每次的 \(rk[i]\) 为,\(s[i:i+2^k-1]\) 的排名。 取到 \(k=\log n\) 的时候,这个东西就是全部的排名了 (注意取子串这个操作对 \(|s|\) 取 \(\min\))
现在我们已经求好了 \(k\) 的排名,要求 \(k+1\) 的排名。
那很简单,把 \(i\) 位置看作是 \(rk[i],rk[i+2^k]\) 组成的二元组,然后来一个双关键字的排序即可。
然后这样是 \(O(n\log^2 n)\) 的。太慢了。考虑用计数排序(鸡排) 优化掉它,就变成了 \(O(n\log n)\)
如何鸡排:
#define F(i,l,r) for(int i=l;i<=r;++i) #define D(i,r,l) for(int i=r;i>=l;--i) int cnt[N]; int a[N],tmp[N]; void chicken_sort() { F(i,1,n) cnt[a[i]]++; F(i,1,n) cnt[i]+=cnt[i-1]; D(i,n,1) tmp[cnt[a[i]]--]=a[i]; F(i,1,n) a[i]=tmp[i],tmp[i]=0; }这个东西画一下就懂了,意思就是,某个东西出现了 \(cnt\) 次,那就给它分配 \(cnt\) 个空间,然后每次从后往前遍历,从后往前填充它现在应当所在的位置。
注意到两个“从后往前”方向一致,所以它是稳定的。
现在有两个关键字。可以先按一个关键字做一遍(稳定的)鸡排,然后用这个结果做第二遍鸡排,即可。
想象一下怎么写,代码到最后给全。
你想看,就让你看个够啦
接下来考虑 ht 数组。考虑它的辅助数组:\(h\) 数组
\(h[i]\) 表示 \(i\) 和 \(i\) 排名前一位(\(kth(rk(i)-1)\),后记作 \(pre(i)\))的 \(LCP\)
\(h\) 数组有一个性质:
\[h[i]\ge h[i-1]-1 \]证明这个结论之前,先考虑排好序的后缀有甚么性质
在排好序的后缀中,设排序结果为 \(s_1,s_2\cdots s_n\),有:
\[LCP(s_i,s_j)=\min(ht_{i+1},ht_{i+2}\cdots ht_{j}) \]显然可以想象出来
设它(\(LCP\))为 \(k\)。那么 \(s_i,s_j\) 的 \(k+1\) 位一定不同,并且 \(s_i\) 的更小
想像一下排完序之后数组长什么样。每次相邻两个都是,前面若干相同,然后有一个不同,一定是变大的。
那么假设 \([i,j]\) 区间的变化中,有一次的变化落在了 \([1,k]\) 之间,那么 \([1,k]\) 组成的串的字典序就已经 严格 大于 \(s_i[1:k]\) 了,并且以后还会保持严格大于的状态。那么和我们假设的 \(LCP(s_i,s_j)=k\),即他们前 \(k\) 个相同,就矛盾了。
于是 \([i+1,j]\) 的 \(ht\) 一定都 \(\ge k\)
那一定有一个 \(=k\) 吗?显然是有的:要不然 \(k+1\) 位不会有变化,那 \(LCP\) 就是 \(k+1\),或者以上了,又矛盾了。
于是证毕。
然后回到 \(h\) 性质来。结合这个图来证明一下 \(h\) 的性质。
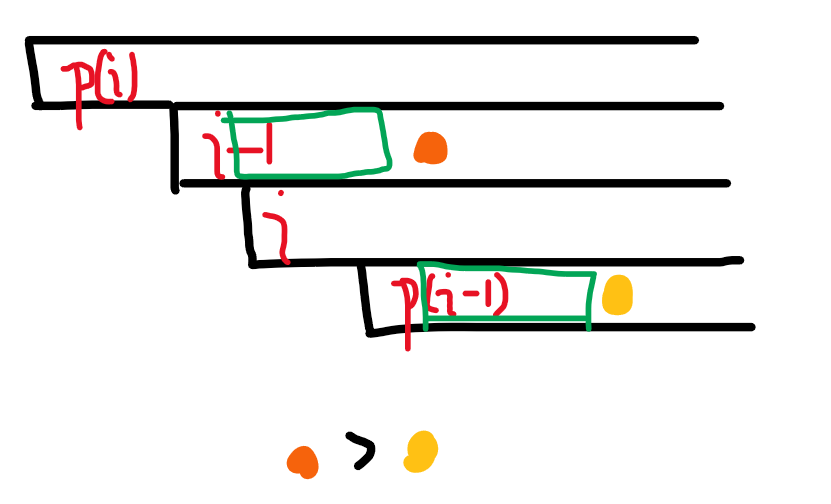
这里的每一个黑色方框表示 \(s\) 的一个后缀。
\(p(i)\) 就是 \(pre(i)\),仅对这个图中有效。
\(h[i-1]\) 就是 \(LCP(i-1,p(i-1))\)。然后现在我们同时拿掉第一个字符,得到两个绿色的串,长度为 \(h[i-1]-1\)。然后绿色的串后面分别是橙色,黄色的字符,橙色>黄色 (由于我们排好了序)
那么橙色就是 \(i\) 后面那个位置,得到 \(s[i:]\) 的字典序要大于 \(s[p(i-1)-1:]\),并且 \(s[i:]\) 和 \(s[p(i-1)-1:]\) 的 \(LCP\) 就是 \(h[i-1]-1\)。
所以 \(s[p(i-1)-1:]\) 的排名在 \(s[i:]\) 的严格前面。那么,它的排名 \(\le\) \(p(i)\) 串的排名。由 \(LCP=min(ht)\) 的那个性质,我们知道 \(LCP(s[i:],s[p(i-1)-1:])\le LCP(i,pre(i))\)
原因很简单,由那个性质,$LCP\le $ 每一个 \(ht\),而 \(LCP(i,pre(i))\) 就是 \(h[i]\),即 \(ht[rk(i)]\),是 \(LCP(s[i:],s[p(i-1)-1:])\) 的其中一个 \(ht\)。所以有这个 $\le $。
然后代换一下就有了,\(h[i-1]-1\le h[i]\)
有了这个性质有啥用呢?每次令 \(h[i]=h[i-1]-1\),然后暴力找一遍,就可以 \(O(n)\) 的求 \(h\) 数组了。因为每次只会退一步,那一共只会退 \(n\) 步,那我们 ++ 的次数一定不会超过 \(2n\),显然是线性的。
根据 \(h\) 就可以求 \(ht\),然后再来一个 \(st\) 表,就可以支持:
\(O(n\log n)\) 的预处理,求出后缀数组的几个数组,以及支持 \(O(1)\) 查询后缀 \(LCP\)。
这大概是一个封装好的板子
struct node{int x,y,id;} t[N],t2[N];
int cc[N];
inline void chicken_sort()
{
F(i,0,n) cc[i]=0,t2[i]=(node){0,0,0};
F(i,1,n) cc[t[i].y]++;
F(i,1,n) cc[i]+=cc[i-1];
D(i,n,1) t2[cc[t[i].y]--]=t[i];
F(i,1,n) t[i]=t2[i],t2[i]=(node){0,0,0}; // 这是普通的鸡数排序, 做两遍即可
F(i,0,n) cc[i]=0,t2[i]=(node){0,0,0};
F(i,1,n) cc[t[i].x]++;
F(i,1,n) cc[i]+=cc[i-1];
D(i,n,1) t2[cc[t[i].x]--]=t[i];
F(i,1,n) t[i]=t2[i],t2[i]=(node){0,0,0};
}
class Suffix_Array
{
public:
char tt[N];
int kth[N],rk[N],h[N],ht[N];
int st[N][22],lg[N];
void Build(char s[])
{
F(i,1,n) tt[i]=s[i]; sort(tt+1,tt+n+1);
F(i,1,n) rk[i]=lower_bound(tt+1,tt+n+1,s[i])-tt;
// 直接排序一遍得到最开始的rk
F(k,1,20)
{
F(i,1,n) t[i]=(node){rk[i],rk[min(n+1,i+(1<<(k-1)))],i}; // 双关键字
chicken_sort();
int tot=0;
for(int l=1,r=1;l<=n;l=r)
{
++tot;
while(t[l].x==t[r].x and t[l].y==t[r].y and r<=n) // 注意要处理一下相同的, 并赋以相同的rk
{
rk[t[r].id]=tot;
++r;
}
}
if (tot==n)
{
break;
}
}
F(i,1,n) kth[rk[i]]=i;
F(i,1,n) if (rk[i]>1)
{
h[i]=max(h[i-1]-1,0);
int p=i,q=kth[rk[i]-1];
while(s[p+h[i]]==s[q+h[i]]) // 暴力找
{
++h[i];
}
}
F(i,1,n) ht[rk[i]]=h[i];
lg[1]=0; F(i,2,n) lg[i]=lg[i>>1]+1;
F(i,1,n) st[i][0]=ht[i];
F(k,1,20) if ((1<<k)<=n)
{
F(i,1,n)
{
st[i][k]=min(st[i][k-1],st[i+(1<<(k-1))][k-1]);
}
} // st表
}
inline int mn(int l,int r) // 求一下最小值就是区间LCP了
{
if(l>r) swap(l,r); ++l;
int k=lg[r-l+1];
return min(st[l][k],st[r-(1<<k)+1][k]);
}
inline void clear()
{
F(i,0,n)
{
tt[i]=kth[i]=rk[i]=h[i]=ht[i]=lg[i]=0;
F(k,0,21)
{
st[i][k]=0;
}
}
}
}S;
后缀树 (Suffix Trie)
考虑把每个后缀都插入到 Trie 里。
然后这个东西太大了,点数太多。
发现它的叶子只有 \(n\) 个,所以很多都是单叉,只有最多 \(n-1\) 个点能是多叉的,把链缩起来即可。
其实这是一个建虚树的过程。
事实上我并不会只建一个后缀树,我只会拿 SAM 建后缀树。所以咕到 SAM 来讲。
如何应用
放在树上考虑,做一些dp,贪心,之类的
后缀自动机 (Suffix Automaton / SAM)
提示:本篇仅供个人复习用,想要更好的体验首选 oi-wiki
基本定义&性质&简单证明
自动机
自动机的定义:
简单来说,就是边上带一个字符作为权的有向图。顺着有向图的边走,可以到达一个点,把边上的字符连起来,就是这个点表示的状态。一个点的状态不一定是一个,可能是一个集合。
当然如果自动机有环,那一个点就有无穷多状态了。
我们接触过的自动机,Trie 就是一个:它的点状态是唯一的。
我们称一个自动机能 接受 一个串,当且仅当,我们按照这个串的字符,在自动机上走,不会没有转移可以走。否则称这个自动机 不接受 这个串。
SAM 是一个点,边都是 \(O(n)\) 的自动机,并且它能且仅能接受串的 所有后缀。它是一个高度压缩的自动机,毕竟把 \(n^2\) 压缩到了 \(n\)

这是一个 SAM 的例子(oiwiki),串为 abbb
点的状态
设 \(endpos(t)\) 表示字符串 \(t\) 在 \(s\) 中出现的末尾位置的集合。那么 SAM 上一个点,表示的状态集合(为什么是集合看上面) 就是若干个 \(endpos\) 集合相同的串。
\(endpos\) 集合有几条性质,
-
对于两个串 \(u,v\),\(|u|<|v|\):
-
要么 \(endpos\) 不相交,要么 \(endpos(v)\) 是 \(endpos(u)\) 的子集。
-
如果他俩 \(endpos\) 相同,那肯定 \(u\) 是 \(v\) 的后缀
-
-
若干串的 \(endpos\) 相同,那它们肯定是层层套起来的后缀,而且长度是连续的-1-1-1...-1
证明很简单:
- 如果 \(endpos\) 有相交,交一次就会交多次,那肯定就是子集,要么就是没交;
- 和1一样的思路,交一次就会交多次,如果是恰好相同,那显然就是后缀了
- 考虑如果有跳着,不连续的,那中间的肯定 \(endpos\) 都一样,都可以算进来,于是就是连续的了
现在来考虑如何表示出一个点的状态:
首先是一个 \(endpos\),但是它显然无法显式维护出来。
那么我们可以维护几个变量,首先是长度区间 \([minlen,maxlen]\) (由性质3,一个点表示的字符串集长度应该是连续的),然后还有转移边。
后缀链接link
为了能够构造出 SAM,还需要一个辅助数组:后缀链接 \(link\)。\(link\) 表示最长的一个后缀使得它 \(endpos\) 不同,这个后缀对应的节点。
比如串 abaab 。abaab,baab,aab 的 \(endpos\) 都是 \(\{5\}\),而 ab 这个后缀的 \(endpos\) 是 \(\{2,5\}\)
所以 abaab 这个节点的 \(link\),就是 ab 对应的节点。
我们发现它有一个很好的性质:\(maxlen(link(u))=minlen(u)-1\)
然后我们就不用维护 \(minlen\) 了,直接取一下 \(maxlen(link(u))+1\) 即可。
代码里用 len 表示 \(maxlen\)
它还有另一个性质,每个点的 \(link\) 组成一颗树。
显然,因为 \(len\) 每次只会少,不会多,所以不会有环,而且显然会到 \(0\) ,所以联通,那就是树了
如何构造
考虑增量法构造:每次增加一个字符 \(c\)。
考虑显然需要新增的节点:表示整个串的节点 \(cur\)。设 \(las\) 等于上一个整串的节点,那么 \(len[cur]=len[las]+1\),显然。
然后考虑加上转移边 \(c\)。显然要对上一个串的所有的后缀加上转移边 \(c\):显然不需要找所有后缀,遍历 \(las\) 的 \(link\) 树到根的路径,没有 \(c\) 就加上。
然后考虑求 \(link[cur]\)。我们需要找到上一次串的一个最长的后缀 \(x\),使得 \(x+c\) 在前面出现过。那加上这一次加入后的出现,就至少两次出现,所以就是 \(link[cur]\) 了。
设我们找到的第一个后缀状态(\(las\) 的 \(link\) 树上到根的路径上的点),使得它有 \(c\) 的转移,这个点为 \(p\),然后到 \(c\) 转移到的点为 \(q\)。
\(p\) 表示的就是我们要的 \(x\) 串,然后 \(x+c\) 串是我们要的 \(link\)。那它的长度理应是 \(len[p]+1\)。
如果 \(len[q]\) 恰好是 \(len[p]+1\),那 \(q\) 就是 \(link[cur]\),很幸运。
然而 \(len[q]\) 不一定是 \(len[p]+1\),它可能还有其它的转移边到 \(q\),导致这个 \(len\) 跳了一些。
这时候我们要把 \(q\) 状态拆开,复制出一个新状态 \(q'\),其它的和 \(q\) 一样,但是 \(len[q']=len[p]+1\)。然后把原来到 \(q\) 的转移边都连到 \(q'\),然后 \(q'\) 复制 \(q\) 的转移边,即可。换句话说,这个 \(q'\) 就是取了 \(q\) 表示的串的后 \(len[p]+1\) 长度的后缀。
于是还要维护一下 \(link[q]=q'\)。当然,\(link[cur]=q'\),这是我们想要的。
然后就有了一份构造 \(SAM\) 的代码
int nx[N][26],len[N],lk[N];
int tot=1,las=1;
int add(int c) // 0<=c<=25
{
int cur=++tot;
cnt[cur]=1;
len[cur]=len[las]+1;
int p=las;
while(p and !nx[p][c]) // 遍历后缀,加上 c 转移
{
nx[p][c]=cur;
p=lk[p];
}
if (!p) // 很 trival,但是别忘了
{
lk[cur]=1;
}
else
{
int q=nx[p][c];
if (len[q]==len[p]+1)
{
lk[cur]=q;
}
else
{
int q2=++tot;
len[q2]=len[p]+1; // len[q']=len[p]+1
lk[q2]=lk[q]; F(i,0,25) nx[q2][i]=nx[q][i]; // 复制其它的
lk[cur]=q2; lk[q]=q2; // 搞一下 link
while(p and nx[p][c]==q) // 改一下转移
{
nx[p][c]=q2;
p=lk[p];
}
}
}
las=cur;
return cur;
}
如何应用
现在你有了一个有向无环图,其中所有的路径对应了所有的子串。
那可以用拓扑排序来搞很多问题。
然后利用 \(link\) 树的性质,每个点的 \(endpos\) 集合其实就是它 \(link\) 树上子树里的并。线段树合并可以轻松搞出来这个,然后就可以用 \(endpos\) 集合来干很多好事了。
以及,可以基于 \(link\) 树跑 dp,也是常见套路。
还有,根据 \(link\) 树,跑一遍线段树合并,即可将 \(endpos\) 集合显式的存储在线段树上,这还是很有用的。
建后缀树
反过来跑一遍SAM,得到的 \(link\) 树就是后缀树
证:
考虑后缀树上的一个分叉:\(u\) 分裂成了几个儿子 \(v_1,v_2...v_k\)
那么显然 \(u\) 出现了 \(k\) 次,但是儿子们的出现次数都只有 \(1\)次。造成这个东西的原因就是,出现次数不一样,那也就是,\(endpos\) 集合不一样。所以它就是一个 \(link\) 的关系。
考虑在原串中跳 \(endpos\) 集合,得到的东西是一个前缀的所有后缀。
后缀树上的节点,是一个后缀的所有前缀。
所以反过来建SAM即可。
标签:LCP,后缀,姐妹,笔记,len,link,endpos,rk 来源: https://www.cnblogs.com/LightningUZ/p/14259109.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。