标签:self 全家 Seq2Seq encoder seq2seq decoder tf Tensorflow config
原文链接:https://zhuanlan.zhihu.com/p/47929039
Seq2Seq 模型顾名思义,输入一个序列,用一个 RNN (Encoder)编码成一个向量 u,再用另一个 RNN (Decoder)解码成一个序列输出,且输出序列的长度是可变的。用途很广,机器翻译,自动摘要,对话系统,还有上一篇文章里我用来做多跳问题的问答,只要是序列对序列的问题都能来搞,功能很强大,效果也不错。

一个最基本的 seq2seq 代码写起来也很简单,无论是用 Tensorflow 还是 Pytorch,比如:
import tensorflow as tf
class Seq2seq(object):
def __init__(self, config, w2i_target):
self.seq_inputs = tf.placeholder(shape=(config.batch_size, None), dtype=tf.int32, name='seq_inputs')
self.seq_inputs_length = tf.placeholder(shape=(config.batch_size,), dtype=tf.int32, name='seq_inputs_length')
self.seq_targets = tf.placeholder(shape=(config.batch_size, None), dtype=tf.int32, name='seq_targets')
self.seq_targets_length = tf.placeholder(shape=(config.batch_size,), dtype=tf.int32, name='seq_targets_length')
with tf.variable_scope("encoder"):
encoder_embedding = tf.Variable(tf.random_uniform([config.source_vocab_size, config.embedding_dim]), dtype=tf.float32, name='encoder_embedding')
encoder_inputs_embedded = tf.nn.embedding_lookup(encoder_embedding, self.seq_inputs)
encoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
encoder_outputs, encoder_state = tf.nn.dynamic_rnn(cell=encoder_cell, inputs=encoder_inputs_embedded, sequence_length=self.seq_inputs_length, dtype=tf.float32, time_major=False)
tokens_go = tf.ones([config.batch_size], dtype=tf.int32) * w2i_target["_GO"]
decoder_inputs = tf.concat([tf.reshape(tokens_go,[-1,1]), self.seq_targets[:,:-1]], 1)
with tf.variable_scope("decoder"):
decoder_embedding = tf.Variable(tf.random_uniform([config.target_vocab_size, config.embedding_dim]), dtype=tf.float32, name='decoder_embedding')
decoder_inputs_embedded = tf.nn.embedding_lookup(decoder_embedding, decoder_inputs)
decoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
decoder_outputs, decoder_state = tf.nn.dynamic_rnn(cell=decoder_cell, inputs=decoder_inputs_embedded, initial_state=encoder_state, sequence_length=self.seq_targets_length, dtype=tf.float32, time_major=False)
decoder_logits = tf.layers.dense(decoder_outputs.rnn_output, config.target_vocab_size)
self.out = tf.argmax(decoder_logits, 2)
这里就是定义两个 RNN,都是直接准备好输入序列用 dynamic_rnn 运行就可以,encoder rnn 的输入就是模型输入的单词序列,decoder rnn 的输入需要简单制作一下,就是把期望输出往后挪一下,然后前面加一个“_GO”的标记。就是如下图的样子。

模型写完了,代码很简单,跑就完事了。
但是这只是个引子。正文这里才开始。
1. Teacher Forcing
相关的全家桶成员:TrainingHelper,GreedyEmbeddingHelper,BasicDecoder,dynamic_decode
上面的代码虽然简单粗暴,实际上已经使用了一种 Teacher Forcing 的策略。就是说在 decoder 阶段,正常情况下某个时刻的输入应该是上一时刻的输出,但是使用了 Teacher Forcing,不管模型上一个时刻的实际输出的是什么,哪怕输出错了,下一个时间片的输入总是上一个时间片的期望输出。把两个套路的图放一起就能看到区别

这样做是好的,因为:
- 防止上一时刻的错误传播到这一时刻,decode 出一个序列,要是第一个单词错了,整个序列就跑偏了,这个序列就没啥意义了,计算 loss 更新参数作用都很小了。用了 Teacher Forcing 可以阻断错误积累,斧正模型训练,加快参数收敛(我自己试了一下,用和不用 Teacher Forcing,训练时候的 loss 下降速度和最终结果真的差了不少)
- 这样就可以提前把 decoder 的整个输入序列提前准备好,直接放到 dynamic_rnn 函数就能出结果,实现起来简单方便
但是,有个最大的问题:模型训练好了,到了测试阶段,你是不能用 Teacher Forcing 的,因为测试阶段你是看不到期望的输出序列的,所以必须乖乖等着上一时刻输出一个单词,下一时刻才能确定该输入什么。不能提前把整个 decoder 的输入序列准备好,也就不能用 dynamic_rnn 函数了
咋整?这时就必须用 raw_rnn 函数,手动补充 loop_fn 循环,手动去写在 decoder rnn 的每一个时间片上,先把上一个时间片的输出向量映射到词表上,再找出概率最大的词,再用 embedding 矩阵映射成向量成为这一时刻的输入,还要判断这个序列是否结束了,结束了还要拿“_PAD”作为输入……,写出来差不多是这个样子:
(算了不放了,20多行太长了。总之很麻烦,感兴趣可以去源代码里的 model_seq2seq.py 看一下)
这时,全家桶可以非常轻松解决这个问题,放代码:
tokens_go = tf.ones([config.batch_size], dtype=tf.int32) * w2i_target["_GO"]
decoder_embedding = tf.Variable(tf.random_uniform([config.target_vocab_size, config.embedding_dim]), dtype=tf.float32, name='decoder_embedding')
decoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
if useTeacherForcing:
decoder_inputs = tf.concat([tf.reshape(tokens_go,[-1,1]), self.seq_targets[:,:-1]], 1)
helper =tf.contrib.seq2seq.TrainingHelper(tf.nn.embedding_lookup(decoder_embedding, decoder_inputs), self.seq_targets_length)
else:
helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embedding, tokens_go, w2i_target["_EOS"])
decoder = tf.contrib.seq2seq.BasicDecoder(decoder_cell, helper, encoder_state, output_layer=tf.layers.Dense(config.target_vocab_size))
decoder_outputs, decoder_state, final_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(decoder, maximum_iterations=tf.reduce_max(self.seq_targets_length))
这里就是用 helper 这个类来帮你自动地给 decoder rnn 的每个时刻提供不同的输入内容,用或不用 Teacher Forcing 的区别只在于将 helper 定义为 TrainingHelper 或是 GreedyEmbeddingHelper。 且这两种方式,从模型变量的角度看是没有区别的,只是数据的流动方式不同,也就是说,在实际应用中,可以在 train 阶段新建一个用 TrainingHelper 的模型,训练完了保存模型参数,在 test 阶段再新建另一个用 GreedyEmbeddingHelper 的模型,直接加载训练好的参数就可以用
dynamic_decode 函数类似于 dynamic_rnn,帮你自动执行 rnn 的循环,返回完整的输出序列
这样,本来手打实现需要二三十行的功能,调接口10行左右就写完了。另外还有一个神奇的地方,不知道是 tf.contrib.seq2seq 全家桶在实现的时候加了什么 trick,试验了一下总是比我自己写的seq2seq的loss收敛速度以及最终结果都要好一些,放个对比图
2. Attention
相关的全家桶成员:AttentionWrapper,BahdanauAttention/LuongAttention
seq2seq 里 attention 的作用就不详细说了,直接放一个我看到过的最直观的一个图,图片来源写在图注里,侵删。
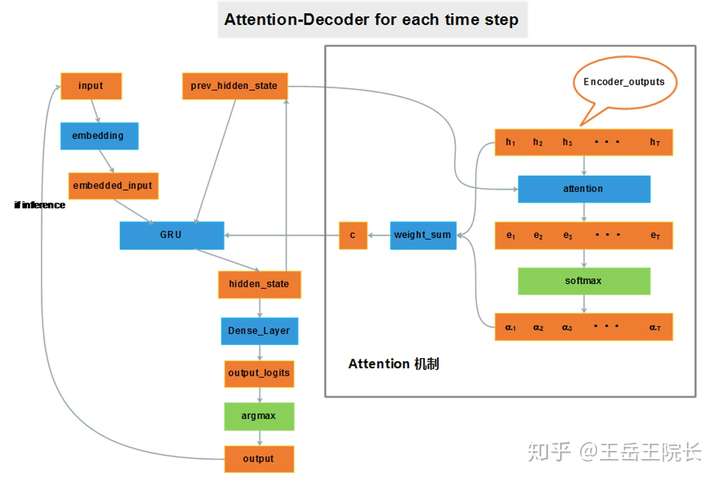 图片来源:CSDN上博主thriving_fcl的博客,https://blog.csdn.net/thriving_fcl/article/details/74853556
图片来源:CSDN上博主thriving_fcl的博客,https://blog.csdn.net/thriving_fcl/article/details/74853556
简单解释一下。跟之前基础 seq2seq 模型的区别,就是给 decoder 多提供了一个输入“c”。因为 encoder把很长的句子压缩只成了一个小向量“u”,decoder在解码的过程中没准走到哪一步就把“u”中的信息忘了,所以在decoder 解码序列的每一步中,都再把 encoder 的 outputs 拉过来让它回忆回忆。但是输入序列中每个单词对 decoder 在不同时刻输出单词时的帮助作用不一样,所以就需要提前计算一个 attention score 作为权重分配给每个单词,再将这些单词对应的 encoder output 带权加在一起,就变成了此刻 decoder 的另一个输入“c”
这个自己实现起来也挺简单的,但是全家桶提供了更为简单的使用方式,上代码:
decoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
if useAttention:
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(num_units=config.hidden_dim, memory=encoder_outputs, memory_sequence_length=self.seq_inputs_length)
# attention_mechanism = tf.contrib.seq2seq.LuongAttention(num_units=config.hidden_dim, memory=encoder_outputs, memory_sequence_length=self.seq_inputs_length)
decoder_cell = tf.contrib.seq2seq.AttentionWrapper(decoder_cell, attention_mechanism)
decoder_initial_state = decoder_cell.zero_state(batch_size=config.batch_size, dtype=tf.float32)
decoder_initial_state = decoder_initial_state.clone(cell_state=encoder_state)
decoder = tf.contrib.seq2seq.BasicDecoder(decoder_cell, helper, decoder_initial_state, output_layer=tf.layers.Dense(config.target_vocab_size))
decoder_outputs, decoder_state, final_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(decoder, maximum_iterations=tf.reduce_max(self.seq_targets_length))直观上看就是把原来定义的最基础 GRU 单元(decoder_cell)外面套一个 AttentionWrapper,直接替换原来的 decoder_cell 就好,只有两个字,省事。全家桶提供了两种可选 attention 策略:BahdanauAttention 和 LuongAttention,具体区别不细说了,主要是 attention score 怎么计算以及“c”怎么结合到输入中的问题,实践上效果差异基本不大
但是还是想说,太省事了,太傻瓜式了,个人不太喜欢这种过度封装的感觉。毕竟 attention 其实是一个“听上去很屌,不明觉厉”,做起来发现“哦,原来就是这么回个事,naive”,所以推荐自己写 attention,其实照着上面那个图梳理下数据流通过程,挺简单的:
def attn(self, hidden, encoder_outputs):
# hidden: B * D
# encoder_outputs: B * S * D
attn_weights = tf.matmul(encoder_outputs, tf.expand_dims(hidden, 2))
# attn_weights: B * S * 1
attn_weights = tf.nn.softmax(attn_weights, axis=1)
context = tf.squeeze(tf.matmul(tf.transpose(encoder_outputs, [0,2,1]), attn_weights))
# context: B * D
return context
# ……
input = tf.cond(finished, lambda: tokens_eos_embedded, get_next_input)
if useAttention:
input = tf.concat([input, self.attn(previous_state, encoder_outputs)], 1)
# ……3. Beam Search
相关的全家桶成员:tile_batch,BeamSearchDecoder
嗨呀这个可是太厉害了。感觉这个是全家桶里性价比最高的一个功能了
先说 Beam Search。这是个只在 test 阶段有用的设定。之前基础的 seq2seq 版本在输出序列时,仅在每个时刻选择概率 top 1 的单词作为这个时刻的输出单词(相当于局部最优解),然后把这些词串起来得到最终输出序列。实际上就是贪心策略
但如果使用了 Beam Search,在每个时刻会选择 top K 的单词都作为这个时刻的输出,逐一作为下一时刻的输入参与下一时刻的预测,然后再从这 K*L(L为词表大小)个结果中选 top K 作为下个时刻的输出,以此类推。在最后一个时刻,选 top 1 作为最终输出。实际上就是剪枝后的深搜策略
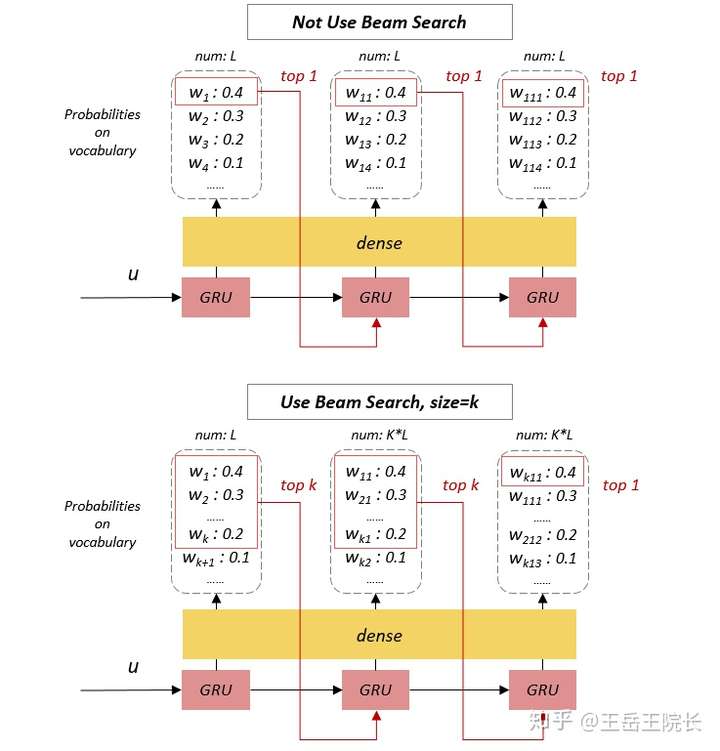
这个实现起来其实挺麻烦的,所以我在不用全家桶实现的那个 seq2seq 版本里也没有实现这个功能
但是全家桶提供了一个非常省事的使用方式,放代码:
tokens_go = tf.ones([config.batch_size], dtype=tf.int32) * w2i_target["_GO"]
decoder_cell = tf.nn.rnn_cell.GRUCell(config.hidden_dim)
if useBeamSearch > 1:
decoder_initial_state = tf.contrib.seq2seq.tile_batch(encoder_state, multiplier=useBeamSearch)
decoder = tf.contrib.seq2seq.BeamSearchDecoder(decoder_cell, decoder_embedding, tokens_go, w2i_target["_EOS"], decoder_initial_state , beam_width=useBeamSearch, output_layer=tf.layers.Dense(config.target_vocab_size))
else:
decoder_initial_state = encoder_state
decoder = tf.contrib.seq2seq.BasicDecoder(decoder_cell, helper, decoder_initial_state, output_layer=tf.layers.Dense(config.target_vocab_size))
decoder_outputs, decoder_state, final_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(decoder, maximum_iterations=tf.reduce_max(self.seq_targets_length))这回就是把 decoder 从 BasicDecoder 换成 BeamSearchDecoder 就完事了,这封装的,流弊
因为使用了 Beam Search,所以 decoder 的输入形状需要做 K 倍的扩展,tile_batch 就是用来干这个。如果和之前的 AttentionWrapper 搭配使用的话,还需要把encoder_outputs 和 sequence_length 都用 tile_batch 做一下扩展,具体可以看代码,不细说了
4. Sequence Loss
相关的全家桶成员:sequence_loss
这个其实是一个 seq2seq 训练中不怎么值得一提但却比较重要的一个地方。放个图说。按照通常的 loss 计算方法,如图假设 batch size=4,max_seq_len=4,需要分别计算这 4*4 个位置上的 loss。但是实际上“_PAD”上的 loss 计算是没有用的,因为“_PAD”本身没有意义,也不指望 decoder 去输出这个字符,只是占位用的,计算 loss 反而带来副作用,影响参数的优化
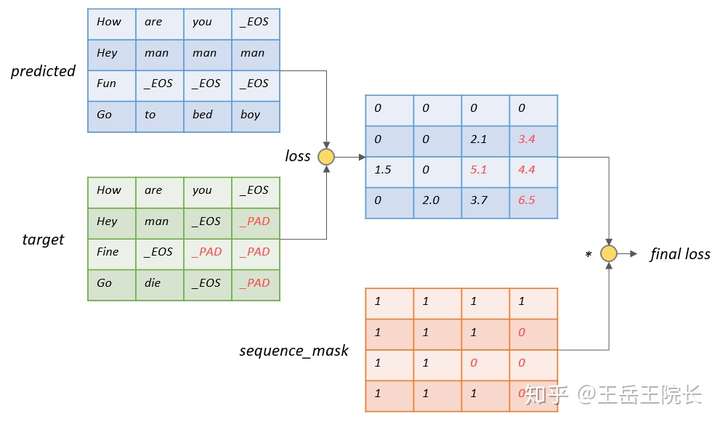
所以需要在 loss 上乘一个 mask 矩阵,这个矩阵可以把“_PAD”位置上的 loss 筛掉。其实有了这个 sequence_mask 矩阵之后(tensorflow 提供的函数 tf.sequence_mask 可以直接生成),直接乘在 loss 矩阵上就完事了。所以全家桶里这个 sequence_loss 实际上并没有什么用处
还是放下代码:
sequence_mask = tf.sequence_mask(self.seq_targets_length, dtype=tf.float32)
self.loss = tf.contrib.seq2seq.sequence_loss(logits=decoder_logits, targets=self.seq_targets, weights=sequence_mask)如果不用全家桶,写出来差不多是这样:
sequence_mask = tf.sequence_mask(self.seq_targets_length, dtype=tf.float32)
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=decoder_logits, labels=self.seq_targets)
self.loss = tf.reduce_mean(loss * sequence_mask)二者并没有什么区别
最后再上一遍结论吧
tensorflow 所提供的这个 seq2seq 全家桶功能还是很强大,很多比如 Beam Search 这些实现起来需要弯弯绕绕写一大段,很麻烦的事情,直接调个接口,一句话就能用,省时省力,很nice
优点就是封装的很猛,简单看一眼文档,没有教程也能拿过来用。缺点就是封装的太猛了,太傻瓜式了,特别是像 Attention 这类比较重要的东西,一封起来就看不到数据具体是怎么流动的,会让用户失去很多对模型的理解力,可控性也减少了很多,比如我现在还没发现怎么输出 attention score(。。[尴尬捂脸],如果有知道的请教我一下,感激不尽)
有得必有失,想要简便快捷拿过来就用使用,不想花时间去学习原理再去一行行码字,就要失去一些对模型的控制力和理解,正常。总的来说这个全家桶还是很好用,很强大,给了不熟练 Tensorflow 或不熟悉 seq2seq 的玩家一个 3 分钟上手 30 分钟上天的机会。但是使用的同时最好了解一下原理,毕竟如果真的把深度学习变成了简单的调包游戏,那这游戏以后很难上分啊
上一句话写给能看到的人,也写给我自己
标签:self,全家,Seq2Seq,encoder,seq2seq,decoder,tf,Tensorflow,config 来源: https://www.cnblogs.com/flightless/p/11974898.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。