标签:Convolutional Multi bag sentence PCNN instance relation embedding 维度
这篇文章从另一个角度来解决Zeng 2015的问题,并且考虑了实体对的多关系的问题。
动机
- Zeng 2015里面仅仅取置信度最高的instance,丢失信息。
- 在数据集中,有约18.3%的entity pair有多种relation, 其他方法均未考虑。
模型
针对以上的两个问题提出了两个解决方法:
- 对bag内部的所有sentence embeding做instance-max-pooling的操作,具体细节后面介绍
- 对于多标签,使用多个二分类函数来做多标签分类,即: 使用sigmod计算每一个类别的概率, 然后判断该bag是否可能有这种关系。
模型的结构如图:
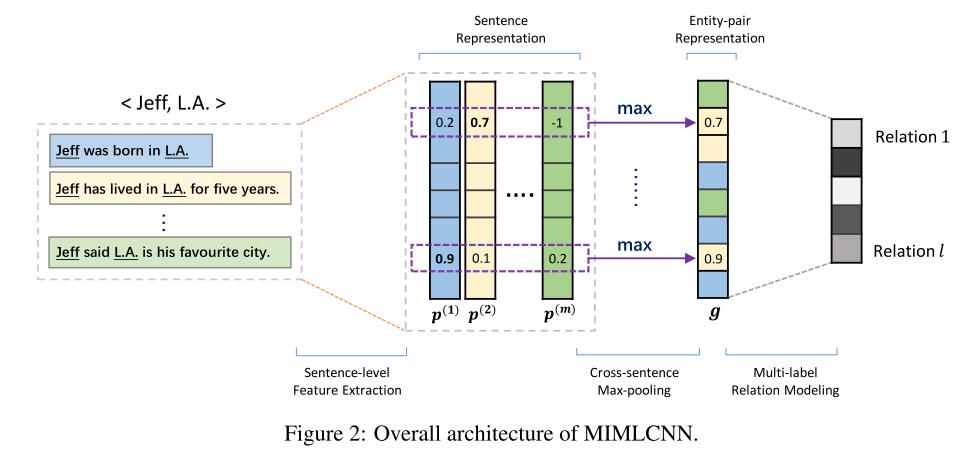
输入也是一个bag,然后利用CNN/PCNN来计算每个sentence的embedding,之后的融合方式很直接,直接对embedding的每一维度取所有sentence的对应维度的最大值。
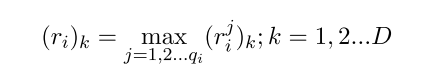
其中k表示embedding的某一维度,jj表示bag中的第j个句子。 这样就可以融合所有sentence的信息了。后面加一个全连接层计算每一个类别的score:
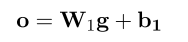
之后不再是加softmax多分类了,而是使用sigmod函数计算每个relation的概率,然后超过某个阈值,就认为该relation是准确的:
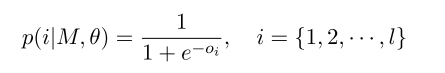
其中ll就是类别的总数。 文中设计了两种损失函数来做对比, Sigmod Loss Vs Squared Loss:
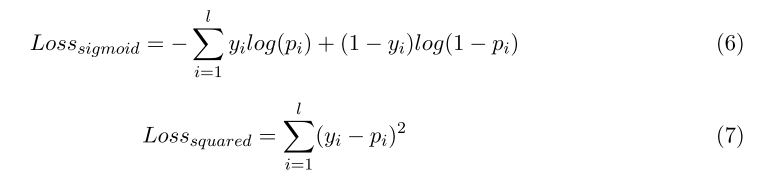
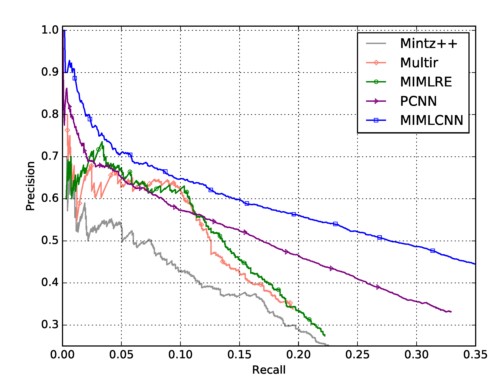
实验 直接看P-R Curve结果,相比PCNN提升比较明显:
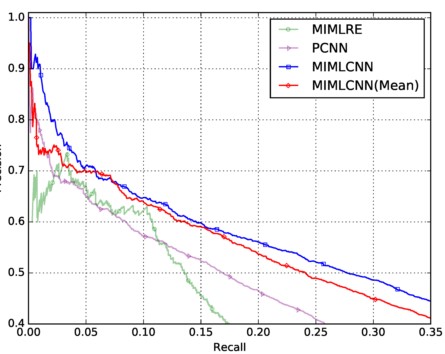
再看取max的设计的作用,与直接取平均对比, 这里有点需要说明,在这个实验中,取平均要比PCNN效果好,而在上一篇平均效果差, 这说明的是multi label有提升的作用:
最后一个是两种损失函数的对比:
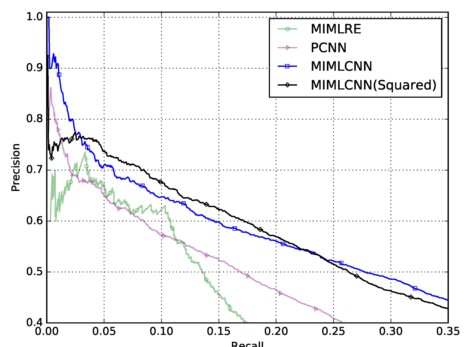
可以看出,二者在不同的区域各自有优势。
总结
仅仅对bags内的sentence的每一维度取了最大值,就可以得到一个很不错的效果, 可以考虑其他稍微复杂一些的融合方式,从而得到更多的信息,Attention仅仅取权重,其实还是属于线性融合。此外这篇文章仍然也是在该CNN/PCNN基础上进行扩展,从这一点来说创新性有些少。 不过文中提出的Multi Label 则是一个新的方向.
标签:Convolutional,Multi,bag,sentence,PCNN,instance,relation,embedding,维度 来源: https://www.cnblogs.com/dhName/p/11751799.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。