标签:Map Semantic Localization 物体 IROS 建模 类别 位姿 CT
论文地址:https://arxiv.org/abs/1810.11525 论文视频:https://www.youtube.com/watch?v=W-6ViSlrrZgwww.youtube.com
简介
作者提出同时进行目标检测和位姿估计,利用一段连续的图像帧,这个图像帧和slam不同之处在于它是对一个场景的扫描,运动的幅度可能很小,就在一个场景附近各个角度扫的一段图形序列,然后在机器人运动的时候通过ORBSLAM定位机器人自己的位置,利用faster-rcnn对物体进行目标检测,通过粒子滤波进行物体的位姿估计,使用提出的CT-Map方法来对检测结果进行纠正,得到更准确的检测结果和物体的位姿。目标
使机器人能够在物体层面上对世界进行语义映射,其中世界的表示是对物体类别和位姿的置信度。随着神经网络物体检测的不断进步,作者为语义映射提供了更强大的构建模块。然而,由于训练数据集的偏差和多样性不足,这种物体检测在野外经常是嘈杂的。并且对来自此类网络的错误检测保持鲁棒性。作者将物体类别建模为生成推理的隐藏状态的一部分,而不是对检测器给出的类标签做出选择。 考虑到运动式RGB-D观测,作者的目标是推断解释观测结果的物体类别和位姿,同时考虑物体之间的上下文关系和物体位姿的时间一致性。在语义映射期间显式地建模物体-物体上下文关系,而不是假设每个物体在环境中是独立的。简单来说就是相同类别的物体比不同类别的物体更容易共同出现。此外,应加强物理合理性,以防止物体相互交叉,以及漂浮在空中。 物体位姿的时间一致性在语义映射中也起着重要作用。物体可以保留在过去观察的位置,或者随着时间的推移逐渐改变它们的语义位置。在遮挡的情况下,建模时间一致性可能有助于部分观察物体的定位。通过时间一致性建模,机器人可以获得物体永久性的概念,例如,即使没有直接观察物体,也相信物体仍然存在。
创新点
考虑到语义映射中的环境和时间因素,作者提出了环境时间映射(CT-MAP)方法来同时检测物体并通过运动的RGB-D相机观测定位它们的6D位姿。将语义映射问题利用概率表示为物体类别和位姿的置信度估计问题。使用条件随机场(CRF)来建模物体之间的上下文关系和物体位姿的时间一致性。 CRF模型中的依赖性包括以下方面: 1)潜在语义映射变量和观测结果之间的兼容性, 2)物体之间的上下文关系 3)物体位姿的时间一致性。 作者提出了一种基于粒子滤波的算法,在CT-MAP中进行生成推理。核心思想
使用一个个向量(物体的位置和概率)来代表场景中的物体。针对每个物体向量存在的概率,作者用粒子滤波和CRF来更新。基本的思想是利用不同帧之间的同一物体在空间位置的一致性来更新物体存在的置信度。用概率来表示物体存在的置信度的好处就是,即使机器人即使一段时间内没有识别出这个物体,这个物体还是一定概率和粒子的形式再场景中存在的。 方法 作者提出CT-Map的方法。 CT-Map方法保持了对观察场景中物体类别和位姿的置信度。 假设机器人通过外部定位程序(例如ORB-SLAM)在环境中定位。该语义地图由一组N个物体组成机器人位置
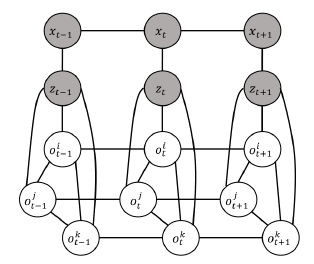
作者是如何建模的?
语义映射的后验概率表示为: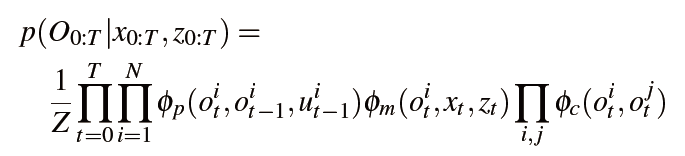 其中Z是归一化常数,并且在t时刻应用于物体
其中Z是归一化常数,并且在t时刻应用于物体 如何建模时间一致性?
具体取决于物体是否在视野中。如果物体在视野中,将动作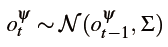 所以预测势能表达为:
所以预测势能表达为:
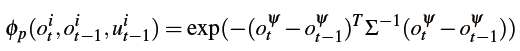 当物体
当物体 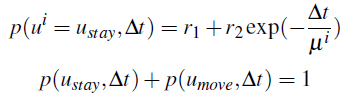 其中
其中 如何给定物体三维网格的观察模型?
物体的测量势能表示为: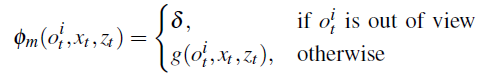 作者使用非零常数δ来说明物体不在视野中的情况。
作者使用非零常数δ来说明物体不在视野中的情况。 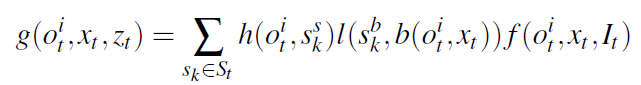 其中
其中 如何捕获物体之间的上下文关系?
所有环境中的物体类别之间存在共同的上下文关系。例如,杯子出现在桌子上会比出现在地板上更频繁,鼠标在键盘旁边会比在咖啡机旁边出现得更频繁。作者将这些共同的上下文关系称为类别级的上下文关系。在特定环境中,某些物体实例之间存在上下文关系。例如,电视总是放在某个桌子上,麦片盒通常存储在特定的柜子中。作者将特定环境中的这些上下文关系称为实例级上下文关系。 作者手动将类别级上下文关系编码为模型的先验知识,也可以从公共场景数据集中学习。由于实例级上下文关系在不同环境中是变化的,因此必须随着时间的推移学习特定环境的关系。环境势能由类别级势能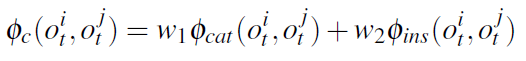 将
将 粒子滤波的算法

实验和效果
使用Faster R-CNN 作为物体探测器。给定RGB-D观测的RGB通道,应用物体检测器并从区域提出网络中获取边界框,以及相应的类别得分向量。然后对这些边界框使用非最大抑制,并合并具有大于0.5的交叉联合(IoU)的边界框。 在所有实验中,作者使用等式5中的物体检测
作者使用Faster R-CNN物体探测器的噪声物体探测,而CT-Map可以通过将物体类别建模隐藏状态的一部分来纠正一些错误探测。为了评估CT-Map的物体检测性能,在数据集中的每个RGB-D序列的末尾处,对场景中所有物体进行六自由度位姿估计,并将它们投射回该序列中的每个相机帧上,以生成带有类别标签的边界框。通过考虑不同的势能集合来进行两个语义映射过程: 1)时间映射(T-Map):考虑CRF模型中的预测势能; 2)环境时间映射(CT-Map):考虑CRF模型中的预测和环境势能。 在观测中,T-Map和CT-Map均包括测量势能。 作者使用mAP作为物体检测指标。如下表所示,T-Map通过结合预测和观察势能改进了Faster R-CNN,并且CT-Map通过另外结合环境势能进一步改善了性能。Faster R-CNN在测试场景中表现不佳,因为训练数据不一定涵盖测试时遇到的差别。虽然通过提供更多的训练数据可以进一步提高Faster R-CNN的性能,但是CT-Map在训练受限的情况下提供了更具有鲁棒性的目标检测 作者场景数据集上的mAP: 在某些情况下,由于遮挡,Faster R-CNN检测到的物体不可靠。如果之前在环境中观测过一个物体,通过对物体的时间一致性进行建模,来预测物体可以去的位置。因此,即使由于遮挡而未触发对物体的检测,该方法仍然可以定位物体并声明检测。但是,如果物体存在很严重的遮挡且深度观测缺少物体足够的几何信息,无法对物体进行定位。
在某些情况下,由于遮挡,Faster R-CNN检测到的物体不可靠。如果之前在环境中观测过一个物体,通过对物体的时间一致性进行建模,来预测物体可以去的位置。因此,即使由于遮挡而未触发对物体的检测,该方法仍然可以定位物体并声明检测。但是,如果物体存在很严重的遮挡且深度观测缺少物体足够的几何信息,无法对物体进行定位。
位姿估计
对于数据集中的每个RGB-D序列,定位最后看到每个物体的帧,并使用已知的相机矩阵将深度帧投影回3D点云。然后,手动标记物体的ground truth六自由度位姿。之后将每个RGB-D序列末尾估计出的物体位姿与ground truth进行比较。 位姿估计精度由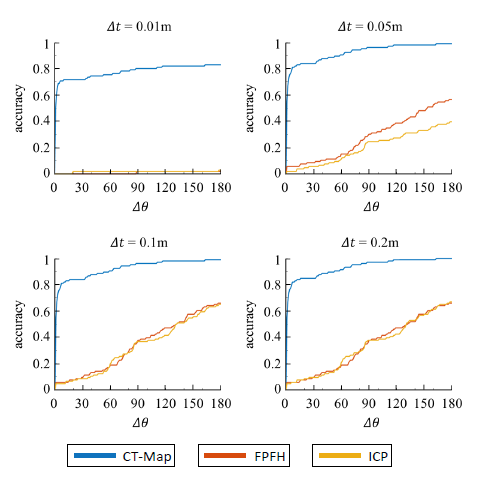 CT-Map显着优于ICP和FPFH。由于生成推断反复地对物体位姿假设进行采样并根据观察结果对其进行评估,因此CT-Map不会像ICP和FPFH这样的判别方法受到局部最小值的影响。
作者提供的视频,机器人带动RGBD相机移动的过程,采集到多帧数据(RGBD序列),粒子在不断运动,在数据末尾,粒子收敛到物体的范围内。
CT-Map显着优于ICP和FPFH。由于生成推断反复地对物体位姿假设进行采样并根据观察结果对其进行评估,因此CT-Map不会像ICP和FPFH这样的判别方法受到局部最小值的影响。
作者提供的视频,机器人带动RGBD相机移动的过程,采集到多帧数据(RGBD序列),粒子在不断运动,在数据末尾,粒子收敛到物体的范围内。

标签:Map,Semantic,Localization,物体,IROS,建模,类别,位姿,CT 来源: https://www.cnblogs.com/lh641446825/p/11568653.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。