标签:RoI 位置 map 论文 feature 解读 Conv5 类别 FCN
背景
基于ResNet 101的Faster RCNN速度很慢,本文通过提出Position-sensitive score maps(位置敏感分值图)来给模型加速。
方法
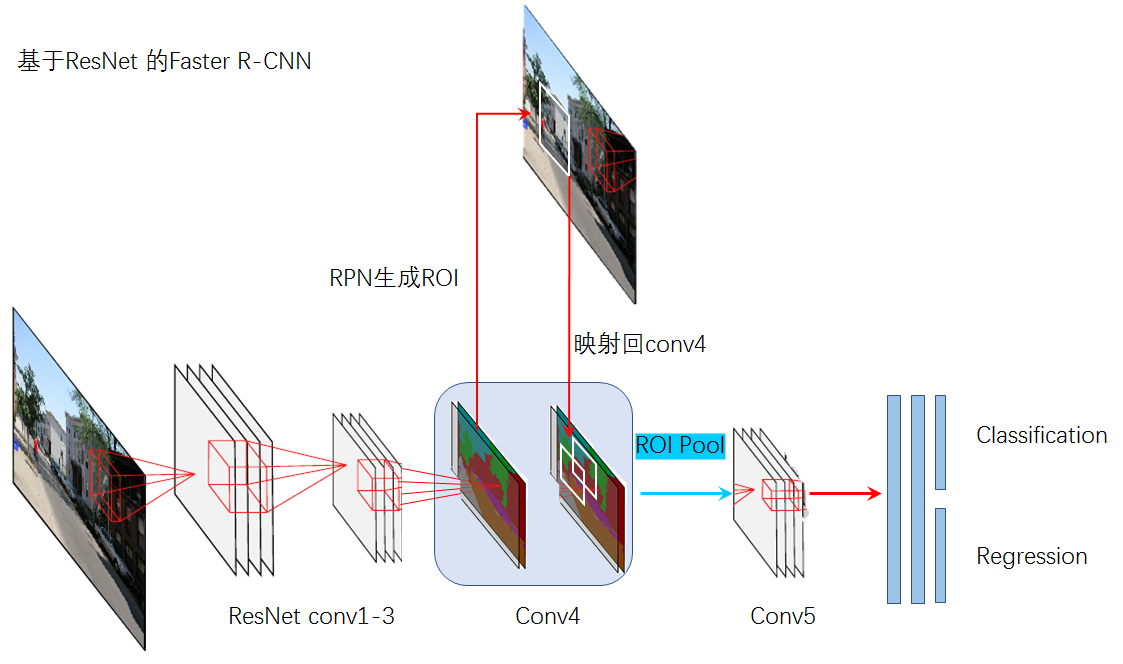
首先分析一下,为什么基于ResNet 101的Faster R-CNN很慢?
其实主要的原因是ROI Pooling层后面的Conv5无法共享计算,每一个RoI都要计算一次,一次检测RoI可能有几百个,计算量巨大。
我们已经知道Conv层的作用是提取特征,那为什么不跟把Conv5放到RoI Pooling前面,让RoI映射到Conv5输出的feature map呢?
这是因为Conv5会使feature map进一步压缩,w*h变小,feature map小了,位置敏感性显然会降低,从而检测的结果不准。
于是,作者提出了一种兼顾速度和准度的结构。
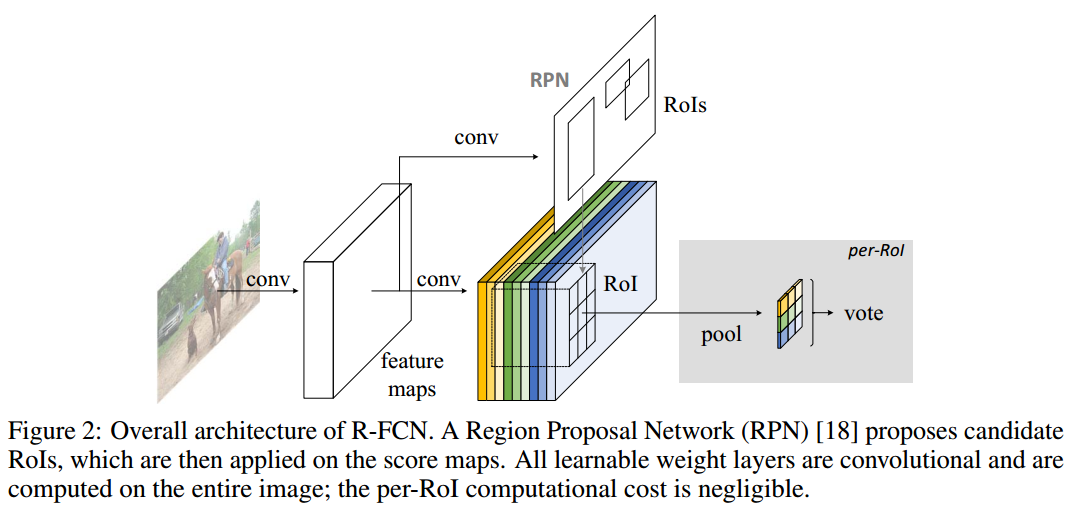
观察上面的模型,我们可以看到,在RoI pooling层后面用来提取特征的Conv层都放到前面了,所以共享了计算,速度加快。
同时,作者提出一种Position-sensitive score maps的方法来解决位置信息丢失,大致是这样的。
原图片经过一系列的Conv层,输出一个channel为k*k*(C+1)的feature map,k=3,代表一张图片的九宫格各位置,C为类别数。可以看到feature map的每一个点,都是k*k*(C+1)-d的feature vector,其中包含了这个点在某位置且为某类的得分信息。
RPN提出的RoI,映射到feature map中,也被分为k*k个bin。
接下来,进行一次Position-sensitive RoI pooling(位置敏感池化)操作。步骤如下:找到一个左上角的bin,然后找到他所对应的(C+1)-d的类别得分信息,可以对w*h的bin的类别信息进行平均池化,得到一个(C+1)的类别信息;其他8个位置也按照同样步骤。
经过这一步,就能得到一个k*k*(C+1)的feature map,再对k*k个(C+1)的vector平均一次(论文用的方法),得到(C+1)的vector,softmax返回一个概率最大的类别就行了。
总结
可以看到,之所以作者的方法之所以位置精度高,主要是因为他把问题从给一个RoI分类转变成了给一个RoI的九个位置分类,从而提高了位置敏感度。
标签:RoI,位置,map,论文,feature,解读,Conv5,类别,FCN 来源: https://www.cnblogs.com/xin1998/p/11385595.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。