标签:Uber 容器 20 节流 内核 配额 CPU cpusets

本文译自 Avoiding CPU Throttling in a Containerized Environment。作者:Joakim Recht和Yury Vostrikov
在 Uber,所有有状态的工作负载都运行在一个跨大型主机的通用容器化平台上。有状态的工作负载包括MySQL®、Apache Cassandra®、ElasticSearch®、Apache Kafka®、Apache HDFS™、Redis™、Docstore、Schemaless等,在很多情况下,这些工作负载位于同一台物理主机上。
凭借 65,000 个物理主机、240 万个内核和 200,000 个容器,提高利用率以降低成本是一项重要且持续的工作。但最近,由于 CPU限流,导致利用率提升这件事没有那么顺利了。
事实证明,问题在于 Linux 内核如何为进程运行分配时间。在这篇文章中,我们将描述从 CPU 配额切换到cpusets(也称为 CPU pinning),如何使我们能够以 P50 延迟的轻微增加换取 P99 延迟的显著下降。由于资源需求的变化较小,这反过来又使我们能够将整个集群范围内的核心分配减少 11%。
Cgroups、配额和 Cpusets
CPU 配额和 cpusets 是Linux内核的调度器功能。Linux内核通过cgroups实现资源隔离,所有容器平台均以此为基础。通常,一个容器映射到一个 cgroup,它控制着在容器中运行的任何进程的资源。
有两种类型的 cgroup(Linux 术语中的控制器)用于执行 CPU 隔离:CPU和cpuset 。它们都控制允许一组进程使用多少 CPU,但有两种不同的方式:分别通过 CPU 时间配额和 CPU pinning。
CPU 配额
CPU控制器使用配额来实现隔离。对于一个CPU 集,你指定要允许的 CPU 比例(核心)。使用以下公式将其转换为给定时间段(通常为 100 毫秒)的配额:
配额 = core_count * 周期(quota = core_count * period)
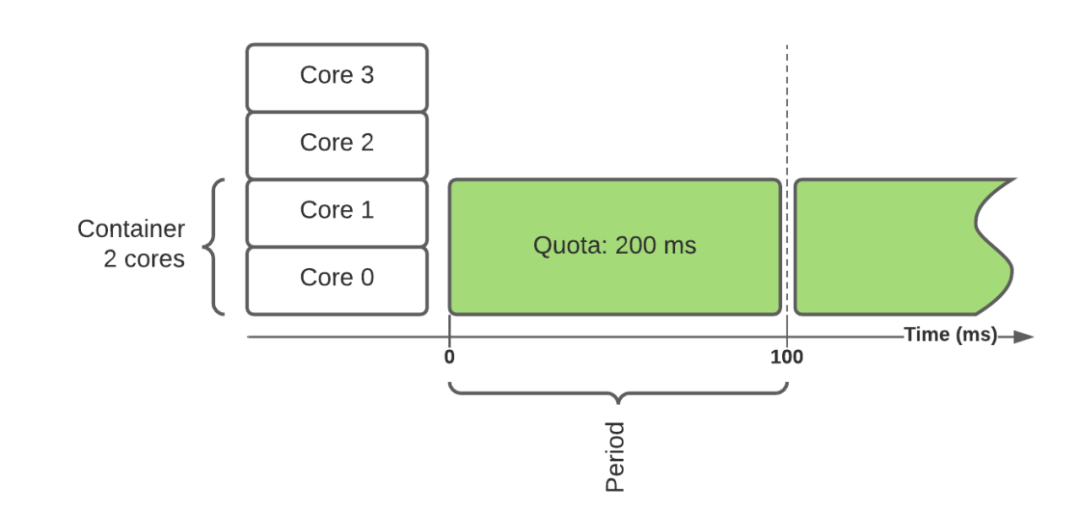
在上面的例子中,有一个需要 2 个内核的容器,这相当于每周期需要 200 毫秒的 CPU 时间。
CPU 配额和节流
由于容器内的多处理/线程,这种方法被证明是有问题的。这会使容器过快地用完配额,导致它在剩余时间段内受到限制。如下图所示:
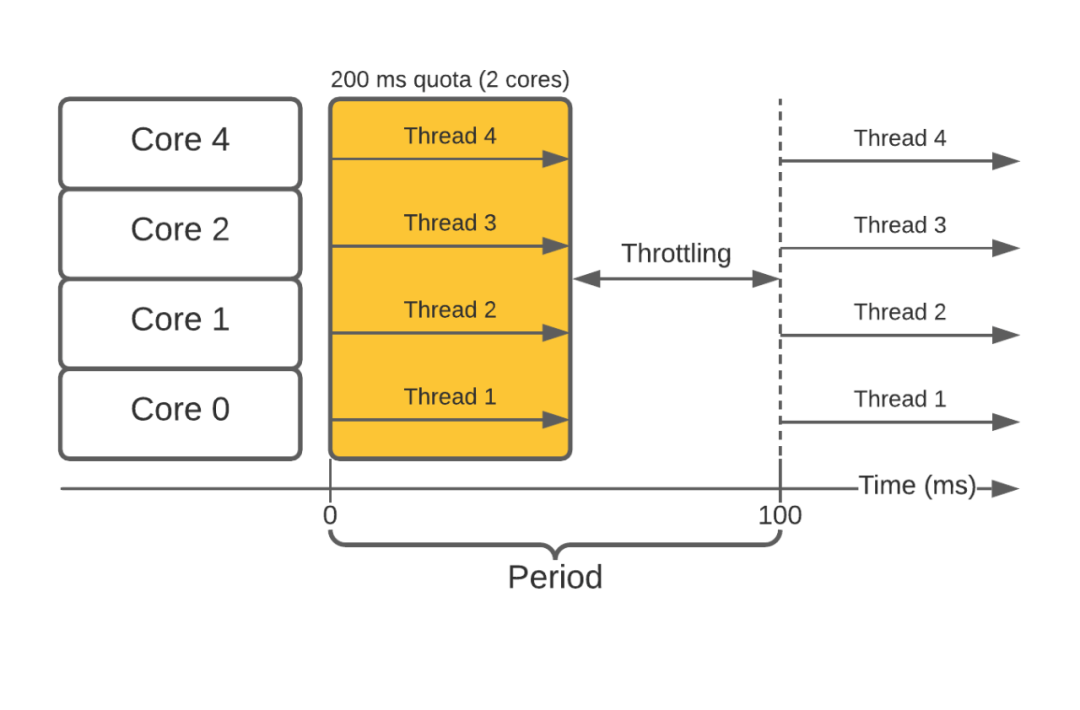
对于提供低延迟请求的容器来说,这是个问题。突然间,由于节流,通常需要几毫秒才能完成的请求可能需要超过 100 毫秒。
简单的解决方法是为进程分配更多的 CPU 时间。虽然这很有效,但在规模上也很昂贵。另一种解决方案是根本不使用隔离。然而,这对于同一地点的工作负载来说是一个非常糟糕的主意,因为一个进程可能会完全耗尽其他进程。
使用 Cpusets避免节流
cpuset 控制器使用 CPU pinning 而不是配额——它基本上限制了一个容器可以在哪些内核上运行。这意味着有可能将所有容器分布在不同的核上,以便每个核只服务于一个容器。这样就实现了完全隔离,不再需要配额或节流,换句话说,可以用延迟的一致性和更繁琐的核管理,来与处理突发和简单配置进行妥协。上面的例子看起来像这样:
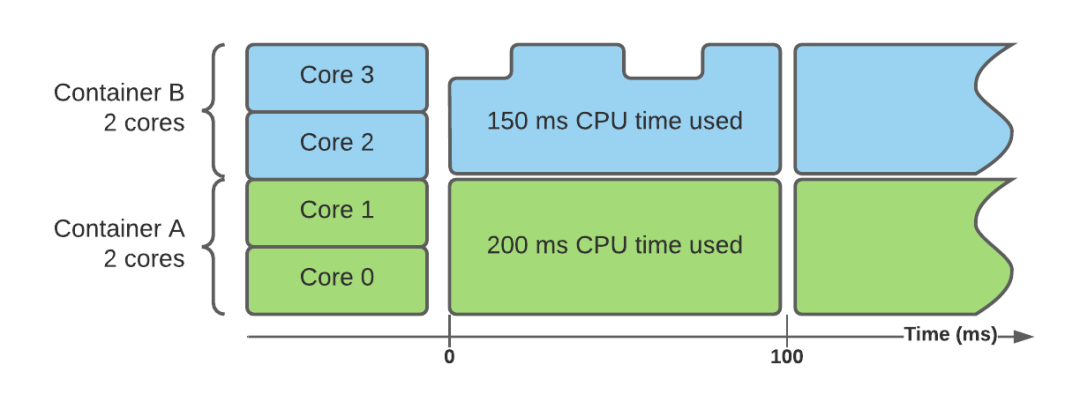
两个容器在两组不同的内核上运行。它们被允许在这些核心上尽可能地使用,但不能使用未分配的核心。
这样做的结果是 P99 的延迟变得更加稳定。下面是一个在启用 cpuset 时对生产数据库集群(每一行是一个容器)进行节流的例子。正如预期的那样,所有节流都消失了:
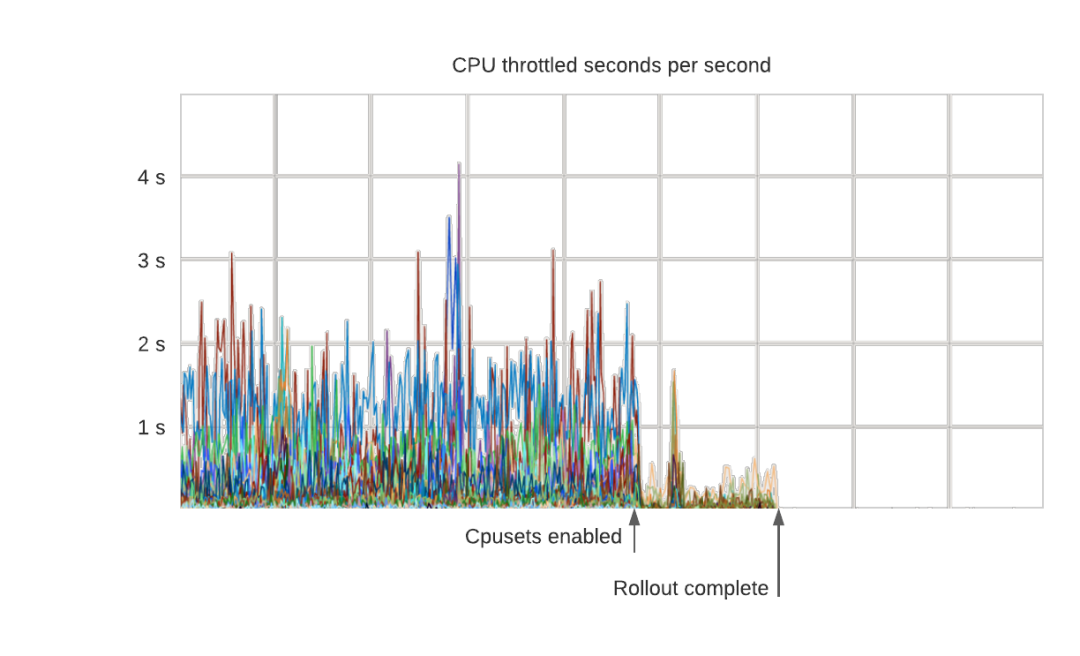
节流现象消失了,因为容器能够自由使用所有分配的内核。更有趣的是,由于容器能够以稳定的速率处理请求,P99 的延迟也得到了改善。在这种情况下,由于消除了严重的节流,延迟下降了50%左右。
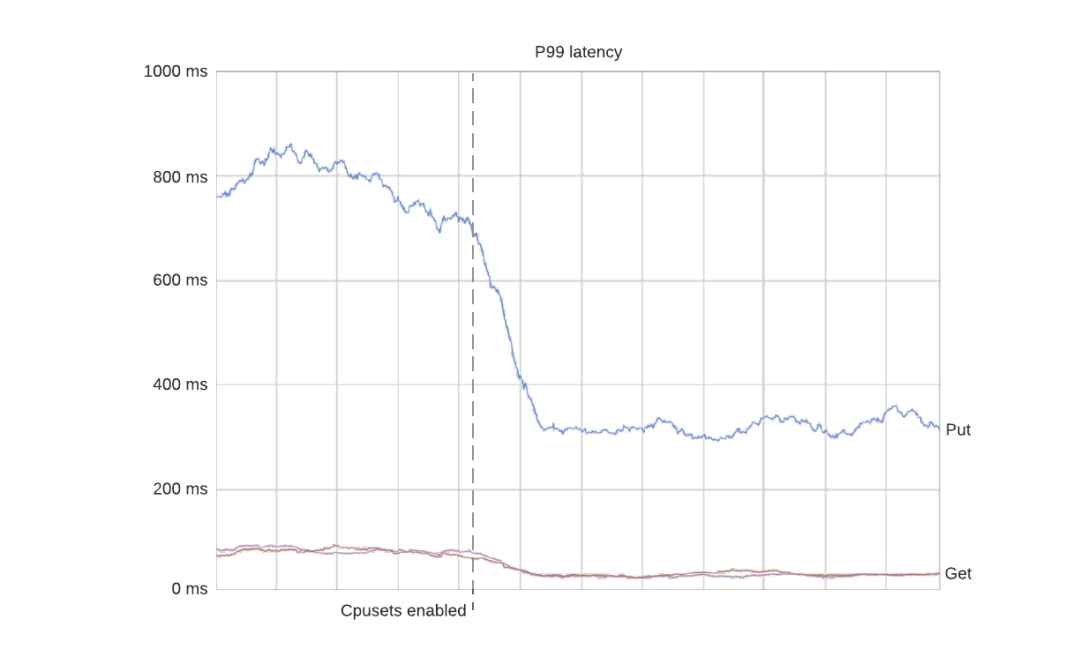
在这一点上值得注意的是,使用 cpusets 也有负面影响。特别是,P50 延迟通常会增加一点,因为它不再可能突入未分配的核心。结果 P50 和 P99 的延迟变得更接近,这通常是可取的。这点将在本文末尾进行更多讨论。
分配 CPU
为了使用 cpusets,容器必须绑定到核心。正确分配内核需要一些关于现代 CPU 架构如何工作的背景知识,因为错误的分配会导致性能显著下降。
CPU 通常围绕以下结构构建:
- 一台物理机可以有多个 CPU 插槽
- 每个插座都有独立的L3缓存
- 每个 CPU 有多个核心
- 每个核心都有独立的 L2/L1 缓存
- 每个核心都可以有超线程
- 超线程通常被视为核心,但分配 2 个超线程而不是 1 个可能只会将性能提高 1.3 倍
所有这些都意味着选择正确的内核实际上很重要。最后一个问题是编号不是连续的,有时甚至不是确定性的——例如,拓扑可能如下所示:
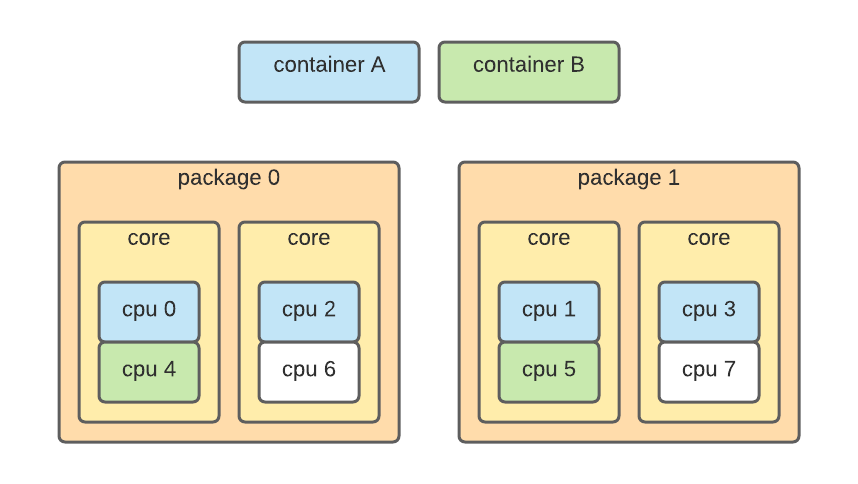
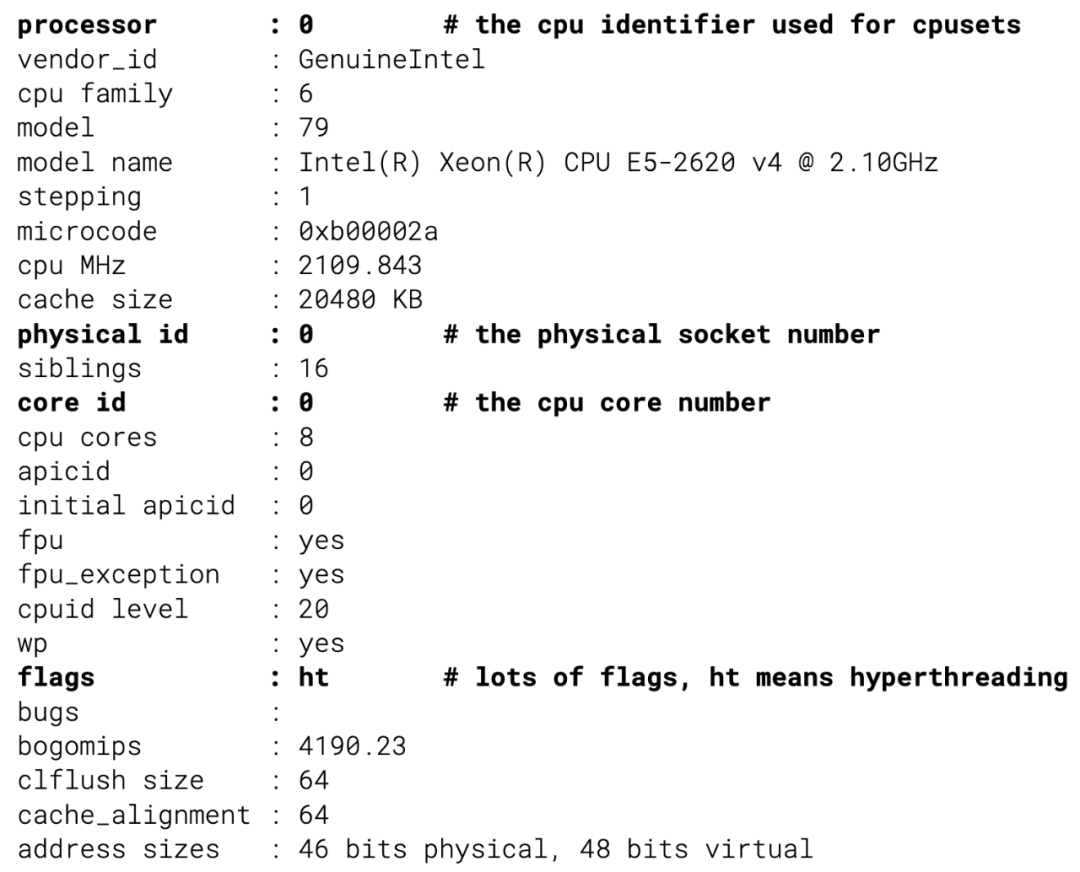
在这种情况下,一个容器被安排在物理套接字和不同的内核上,这会导致性能下降——我们已经看到由于错误的套接字分配,P99 延迟降低了多达 500%。为了处理这个问题,调度器必须从内核收集确切的硬件拓扑,并使用它来分配内核。原始信息在 /proc/cpuinfo 中找到:
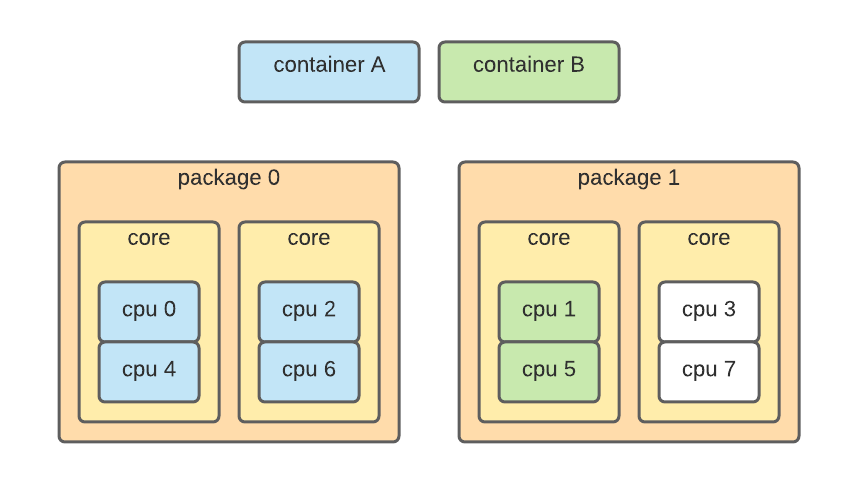
利用这些信息,我们可以分配物理上相互接近的核心:
缺点和局限性
虽然 cpusets 解决了大部分延迟的问题,但也存在一些限制和权衡:
无法分配小数核心。这对于数据库进程来说不是问题,因为它们往往很大,因此向上或向下舍入不是问题。但是,这确实意味着容器的数量不能大于内核的数量,这对于某些工作负载来说是有问题的。
系统范围的进程仍然可以窃取时间。例如,通过 systemd、kernel workers 等在宿主机上运行的服务,仍然需要在某个地方运行。理论上也可以将它们分配给一组有限的内核,但这可能很棘手,因为它们需要的时间与系统负载成正比。一种解决方法是在容器子集上使用实时进程调度——后文会介绍这一点。
需要进行碎片整理。随着时间的推移,可用内核将变得碎片化,并且需要移动进程以创建连续的可用内核块。这可以在线完成,但是从一个物理套接字移动到另一个将意味着内存访问突然变得远程。这也可以缓解,另一篇文章会介绍。
没有突发限制。有时你可能希望使用主机上未分配的资源来加速正在运行的容器。在这篇文章中,我们讨论了独占的 cpusets,但可以将同一个核心分配给多个容器(即 cgroups),也可以将 cpusets 与配额结合使用,这允许突破限制。
结论
切换到有状态工作负载的 cpusets 是 Uber 的一项重大改进。它使我们能够实现更稳定的数据库级别的延迟,并且通过减少过度配置以处理由于节流导致的峰值,节省了大约 11% 的内核。由于没有突发限制,相同大小的容器现在在主机之间的表现是一样的,这也导致了更稳定的性能。
Uber 的有状态部署平台是内部开发的,但Kubernetes ® 也通过使用静态策略来支持cpusets 。
有关Uber如何测试配额和 cpusets 的细节,见附录。
云原生技术社区有20+技术交流群,想进群跟技术大牛们聊天,或加入志愿者队伍,请加小助手微信:

标签:Uber,容器,20,节流,内核,配额,CPU,cpusets 来源: https://www.cnblogs.com/cntc/p/16575766.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。