标签:Web http String yahoo 1242 news com LeetCode startUrl
原题链接在这里:https://leetcode.com/problems/web-crawler-multithreaded/
题目:
Given a URL startUrl and an interface HtmlParser, implement a Multi-threaded web crawler to crawl all links that are under the same hostname as startUrl.
Return all URLs obtained by your web crawler in any order.
Your crawler should:
- Start from the page:
startUrl - Call
HtmlParser.getUrls(url)to get all URLs from a webpage of a given URL. - Do not crawl the same link twice.
- Explore only the links that are under the same hostname as
startUrl.

As shown in the example URL above, the hostname is example.org. For simplicity's sake, you may assume all URLs use HTTP protocol without any port specified. For example, the URLs http://leetcode.com/problems and http://leetcode.com/contest are under the same hostname, while URLs http://example.org/test and http://example.com/abc are not under the same hostname.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
// This is a blocking call, that means it will do HTTP request and return when this request is finished.
public List<String> getUrls(String url);
}
Note that getUrls(String url) simulates performing an HTTP request. You can treat it as a blocking function call that waits for an HTTP request to finish. It is guaranteed that getUrls(String url) will return the URLs within 15ms. Single-threaded solutions will exceed the time limit so, can your multi-threaded web crawler do better?
Below are two examples explaining the functionality of the problem. For custom testing purposes, you'll have three variables urls, edges and startUrl. Notice that you will only have access to startUrl in your code, while urls and edges are not directly accessible to you in code.
Example 1:
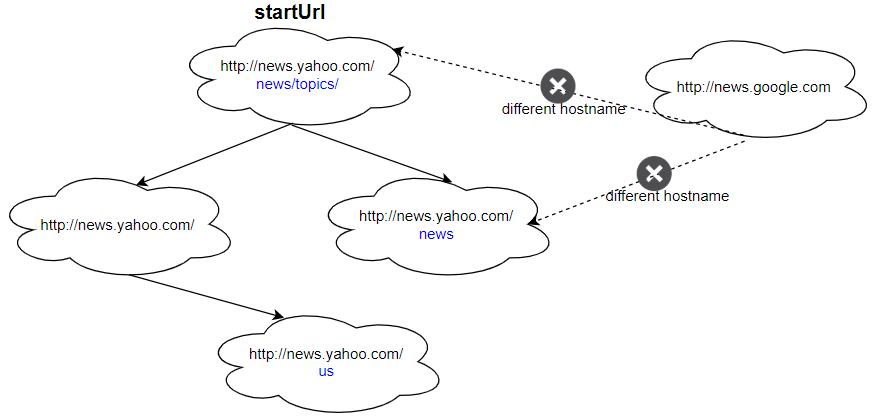
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com", "http://news.yahoo.com/us" ] edges = [[2,0],[2,1],[3,2],[3,1],[0,4]] startUrl = "http://news.yahoo.com/news/topics/" Output: [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.yahoo.com/us" ]
Example 2:
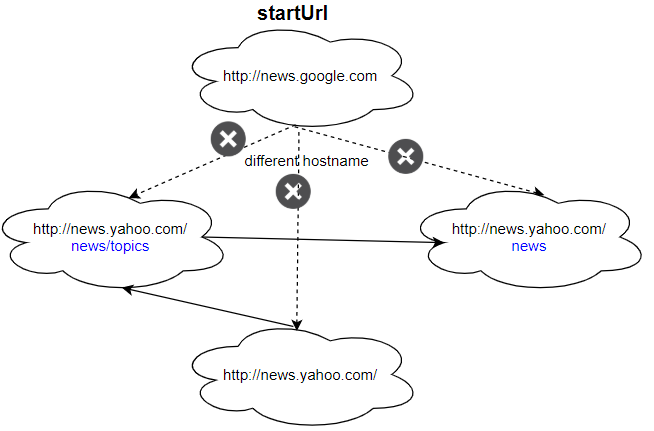
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com" ] edges = [[0,2],[2,1],[3,2],[3,1],[3,0]] startUrl = "http://news.google.com" Output: ["http://news.google.com"] Explanation: The startUrl links to all other pages that do not share the same hostname.
Constraints:
1 <= urls.length <= 10001 <= urls[i].length <= 300startUrlis one of theurls.- Hostname label must be from
1to63characters long, including the dots, may contain only the ASCII letters from'a'to'z', digits from'0'to'9'and the hyphen-minus character ('-'). - The hostname may not start or end with the hyphen-minus character ('-').
- See: https://en.wikipedia.org/wiki/Hostname#Restrictions_on_valid_hostnames
- You may assume there're no duplicates in the URL library.
Follow up:
- Assume we have 10,000 nodes and 1 billion URLs to crawl. We will deploy the same software onto each node. The software can know about all the nodes. We have to minimize communication between machines and make sure each node does equal amount of work. How would your web crawler design change?
- What if one node fails or does not work?
- How do you know when the crawler is done?
题解:
Could do it like BFS. Put url in a queue.
Use a main thread to update result and other threads to get urls in the current url using htmlParser and update the queue.
Then queue must be thread safe. Here we use LinkedBlockedQueue.
Have ExecutorService executor = Executors.newFixedThreadPool(4) to maintain future tasks.
If queue is not empty, we check if it is visited before, if not, then add it to result and continue crawl from it.
When queue is empty, there may be unfinished task. Try finish them.
Otherwise, when queue is empty and no more future task, we know crawl is finished. shutdown the executor.
Time Complexity: O(n + e). n is the number of urls. e is the edge connecting them.
Space: O(n).
AC Java:
1 /**
2 * // This is the HtmlParser's API interface.
3 * // You should not implement it, or speculate about its implementation
4 * interface HtmlParser {
5 * public List<String> getUrls(String url) {}
6 * }
7 */
8 class Solution {
9 public List<String> crawl(String startUrl, HtmlParser htmlParser) {
10 String hostName = getHost(startUrl);
11 Set<String> visited = new HashSet<>();
12 BlockingQueue<String> que = new LinkedBlockingQueue<>();
13 LinkedList<Future> tasks = new LinkedList<>();
14 que.add(startUrl);
15
16 // Create a thread pool of 4 threads
17 ExecutorService executor = Executors.newFixedThreadPool(4);
18
19 while(true){
20 String cur = que.poll();
21 if(cur != null){
22 if(getHost(cur).equals(hostName) && !visited.contains(cur)){
23 visited.add(cur);
24 tasks.add(executor.submit(() -> {
25 List<String> newUrls = htmlParser.getUrls(cur);
26 for(String newUrl : newUrls){
27 que.add(newUrl);
28 }
29 }));
30 }
31 }else{
32 if(!tasks.isEmpty()){
33 Future nextTask = tasks.poll();
34 try{
35 nextTask.get();
36 }catch(InterruptedException | ExecutionException e){
37 }
38 }else{
39 executor.shutdown();
40 break;
41 }
42 }
43 }
44
45 return new ArrayList<String>(visited);
46 }
47
48 private String getHost(String url){
49 return url.split("/")[2];
50 }
51 }
标签:Web,http,String,yahoo,1242,news,com,LeetCode,startUrl 来源: https://www.cnblogs.com/Dylan-Java-NYC/p/16492664.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。