图6.1
下面介绍分词、n-gram表示法和向量化的更多细节。
6.1.1 分词
将给定的一个句子分为字符或词的过程称为分词。诸如spaCy等一些库,它们为分词提供了复杂的解决方案。让我们使用简单的Python函数(如split和list)将文本转换为token。
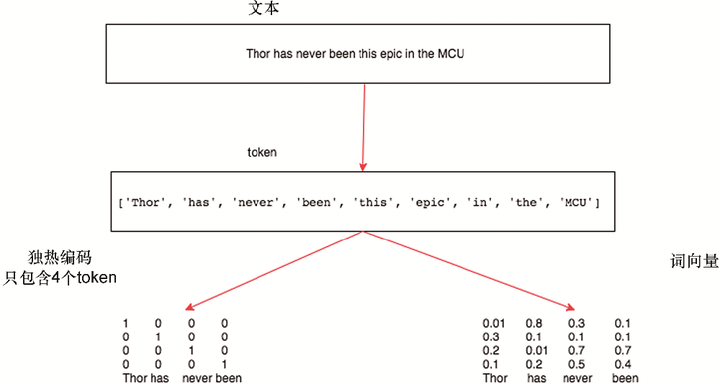
为了演示分词如何作用于字符和词,让我们看一段关于电影Thor:Ragnarok的小评论。我们将对这段文本进行分词处理:
The action scenes were top notch in this movie. Thor has never been this epic in the MCU. He does some pretty epic sh*t in this movie and he is definitely not under-powered anymore. Thor in unleashed in this, I love that.
1.将文本转换为字符
Python的list函数接受一个字符串并将其转换为单个字符的列表。这样做就将文本转换为了字符。下面是使用的代码和结果:
以下是结果:
结果展示了简单的Python函数如何将文本转换为token。
2.将文本转换为词
我们将使用Python字符串对象函数中的split函数将文本分解为词。split函数接受一个参数,并根据该参数将文本拆分为token。在我们的示例中将使用空格作为分隔符。以下代码段演示了如何使用Python的split函数将文本转换为词:
在前面的代码中,我们没有使用任何的分隔符,默认情况下,split函数使用空格来分隔。
3.n-gram表示法
我们已经看到文本是如何表示为字符和词的。有时一起查看两个、三个或更多的单词非常有用。n-gram是从给定文本中提取的一组词。在n-gram中,n表示可以一起使用的词的数量。看一下bigram(当n = 2时)的例子,我们使用Python的nltk包为thor_review生成一个bigram,以下代码块显示了bigram的结果以及用于生成它的代码:
ngrams函数接受一个词序列作为第一个参数,并将组中词的个数作为第二个参数。以下代码块显示了trigram表示的结果以及用于实现它的代码:
在上述代码中唯一改变的只有函数的第二个参数n的值。
许多有监督的机器学习模型,例如朴素贝叶斯(Naive Bayes),都是使用n-gram来改善它的特征空间。n-gram同样也可用于拼写校正和文本摘要的任务。
n-gram表示法的一个问题在于它失去了文本的顺序性。通常它是和浅层机器学习模型一起使用的。这种技术很少用于深度学习,因为RNN和Conv1D等架构会自动学习这些表示法。
6.1.2 向量化
将生成的token映射到数字向量有两种流行的方法,称为独热编码和词向量(word embedding,也称之为词嵌入)。让我们通过编写一个简单的Python程序来理解如何将token转换为这些向量表示。我们还将讨论每种方法的各种优缺点。
1.独热编码
在独热编码中,每个token都由长度为N的向量表示,其中N是词表的大小。词表是文档中唯一词的总数。让我们用一个简单的句子来观察每个token是如何表示为独热编码的向量的。下面是句子及其相关的token表示:
An apple a day keeps doctor away said the doctor.
上面句子的独热编码可以用表格形式进行表示,如下所示。
图6.1
下面介绍分词、n-gram表示法和向量化的更多细节。
6.1.1 分词
将给定的一个句子分为字符或词的过程称为分词。诸如spaCy等一些库,它们为分词提供了复杂的解决方案。让我们使用简单的Python函数(如split和list)将文本转换为token。
为了演示分词如何作用于字符和词,让我们看一段关于电影Thor:Ragnarok的小评论。我们将对这段文本进行分词处理:
The action scenes were top notch in this movie. Thor has never been this epic in the MCU. He does some pretty epic sh*t in this movie and he is definitely not under-powered anymore. Thor in unleashed in this, I love that.
1.将文本转换为字符
Python的list函数接受一个字符串并将其转换为单个字符的列表。这样做就将文本转换为了字符。下面是使用的代码和结果:
以下是结果:
结果展示了简单的Python函数如何将文本转换为token。
2.将文本转换为词
我们将使用Python字符串对象函数中的split函数将文本分解为词。split函数接受一个参数,并根据该参数将文本拆分为token。在我们的示例中将使用空格作为分隔符。以下代码段演示了如何使用Python的split函数将文本转换为词:
在前面的代码中,我们没有使用任何的分隔符,默认情况下,split函数使用空格来分隔。
3.n-gram表示法
我们已经看到文本是如何表示为字符和词的。有时一起查看两个、三个或更多的单词非常有用。n-gram是从给定文本中提取的一组词。在n-gram中,n表示可以一起使用的词的数量。看一下bigram(当n = 2时)的例子,我们使用Python的nltk包为thor_review生成一个bigram,以下代码块显示了bigram的结果以及用于生成它的代码:
ngrams函数接受一个词序列作为第一个参数,并将组中词的个数作为第二个参数。以下代码块显示了trigram表示的结果以及用于实现它的代码:
在上述代码中唯一改变的只有函数的第二个参数n的值。
许多有监督的机器学习模型,例如朴素贝叶斯(Naive Bayes),都是使用n-gram来改善它的特征空间。n-gram同样也可用于拼写校正和文本摘要的任务。
n-gram表示法的一个问题在于它失去了文本的顺序性。通常它是和浅层机器学习模型一起使用的。这种技术很少用于深度学习,因为RNN和Conv1D等架构会自动学习这些表示法。
6.1.2 向量化
将生成的token映射到数字向量有两种流行的方法,称为独热编码和词向量(word embedding,也称之为词嵌入)。让我们通过编写一个简单的Python程序来理解如何将token转换为这些向量表示。我们还将讨论每种方法的各种优缺点。
1.独热编码
在独热编码中,每个token都由长度为N的向量表示,其中N是词表的大小。词表是文档中唯一词的总数。让我们用一个简单的句子来观察每个token是如何表示为独热编码的向量的。下面是句子及其相关的token表示:
An apple a day keeps doctor away said the doctor.
上面句子的独热编码可以用表格形式进行表示,如下所示。
| An | 100000000 |
| apple | 010000000 |
| a | 001000000 |
| day | 000100000 |
| keeps | 000010000 |
| doctor | 000001000 |
| away | 000000100 |
| said | 000000010 |
| the | 000000001 |
 图6.2
图6.2显示了如何调整密集向量,以使其在语义上相似的单词具有较小的距离。由于Superman、Thor和Batman等电影都是基于漫画的动作电影,所以这些电影的向量更为接近,而电影Titanic的向量离动作电影较远,离电影Notebook更近,因为它们都是浪漫型电影。
在数据太少时学习词向量可能是行不通的,在这种情况下,可以使用由其他机器学习算法训练好的词向量。由另一个任务生成的向量称为预训练词向量。下面将学习如何构建自己的词向量以及使用预训练词向量。
图6.2
图6.2显示了如何调整密集向量,以使其在语义上相似的单词具有较小的距离。由于Superman、Thor和Batman等电影都是基于漫画的动作电影,所以这些电影的向量更为接近,而电影Titanic的向量离动作电影较远,离电影Notebook更近,因为它们都是浪漫型电影。
在数据太少时学习词向量可能是行不通的,在这种情况下,可以使用由其他机器学习算法训练好的词向量。由另一个任务生成的向量称为预训练词向量。下面将学习如何构建自己的词向量以及使用预训练词向量。

标签:函数,独热,学习,token,深度,序列,文本,向量 来源: https://www.cnblogs.com/szhlss/p/16480877.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。