标签:13 Self Attention Head 多头 com 向量
博客配套视频链接: https://space.bilibili.com/383551518?spm_id_from=333.1007.0.0 b 站直接看 配套 github 链接:https://github.com/nickchen121/Pre-training-language-model 配套博客链接:https://www.cnblogs.com/nickchen121/p/15105048.html上节课回顾
0:40
Attention

Self-Attention
Self-Attention 其实是 Attention 的一个具体做法
给定一个 X,通过自注意力模型,得到一个 Z,这个 Z 就是对 X 的新的表征(词向量),Z 这个词向量相比较 X 拥有了句法特征和语义特征

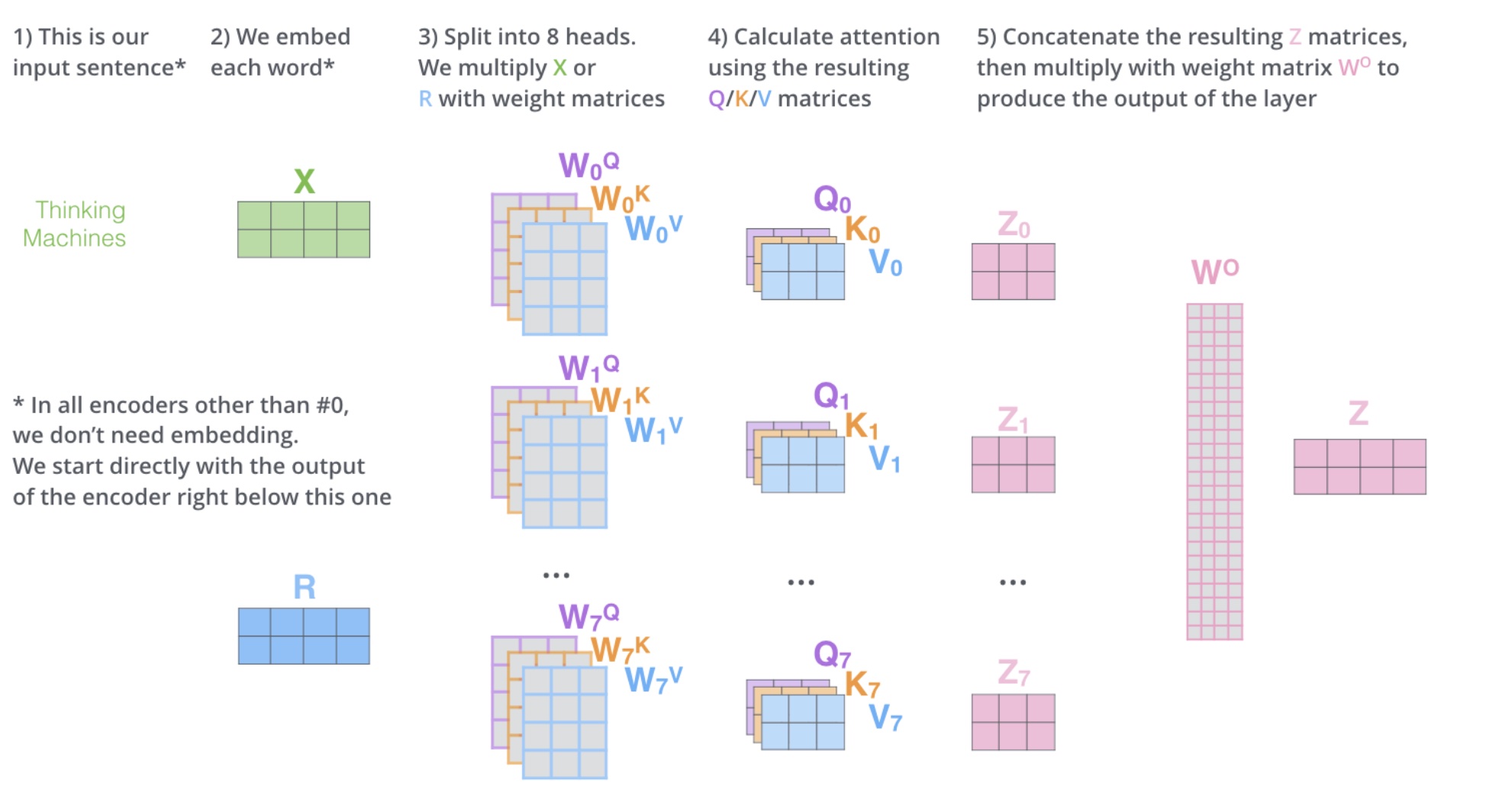
Multi-Head Self-Attention(多头自注意力)
Z 相比较 X 有了提升,通过 Multi-Head Self-Attention,得到的 \(Z{'}\) 相比较 Z 又有了进一步提升
多头自注意力,问题来了,多头是什么,多头的个数用 h 表示,一般\(h=8\),我们通常使用的是 8 头自注意力
什么是多头

如何多头 1

对于 X,我们不是说,直接拿 X 去得到 Z,而是把 X 分成了 8 块(8 头),得到 Z0-Z7
如何多头 2
然后把 Z0-Z7 拼接起来,再做一次线性变换(改变维度)得到 Z

有什么作用?
机器学习的本质是什么:y=\(\sigma\)(wx+b),在做一件什么事情,非线性变换(把一个看起来不合理的东西,通过某个手段(训练模型),让这个东西变得合理)
非线性变换的本质又是什么?改变空间上的位置坐标,任何一个点都可以在维度空间上找到,通过某个手段,让一个不合理的点(位置不合理),变得合理
这就是词向量的本质
one-hot 编码(0101010)
word2vec(11,222,33)
emlo(15,3,2)
attention(124,2,32)
multi-head attention(1231,23,3),把 X 切分成 8 块(8 个子空间),这样一个原先在一个位置上的 X,去了空间上 8 个位置,通过对 8 个点进行寻找,找到更合适的位置
词向量的大小是 512
假设你的任务,视频向量是 5120,80
对计算机的性能提出了要求
多头流程图
标签:13,Self,Attention,Head,多头,com,向量 来源: https://www.cnblogs.com/nickchen121/p/16470726.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。