标签:入门 WordCount hadoop MapReduce job import apache org log4j
摘要:MapReduce的IDEA配置及WordCount案例
目录
Maven项目配置
创建一个空的Maven项目
pom.xml
打开根目录下的pom.xml文件,参考配置:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.2.2</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
log4j.properties
在项目的src/main/java/resources下新建log4j.properties,参考配置
# 参考配置1
log4j.rootLogger = info,console
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern = %d{ABSOLUTE} %5p %c:%L - %m%n
# glibc lib version diff
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
# 参考配置2
log4j.rootLogger = debug,stdout
### 输出信息到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
编写应用程序
/**
* 导入包
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* WordCount应用程序
*/
public class WordCountApp {
/**
* Mapper
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
LongWritable one = new LongWritable(1);
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
// 按照指定分隔符进行拆分
String[] words = line.split(" ");
for(String word: words){
// 通过上下文把map的处理结果输出
context.write(new Text(word), one);
}
}
}
/**
* Reduce归并
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException{
long sum = 0;
for(LongWritable value: values){
// 求key出现的次数
sum += value.get();
}
// 最终统计结果输出
context.write(key, new LongWritable(sum));
}
}
/**
* 定义Driver:封装了MapReduce作业的所有信息
*/
public static void main(String[] args) throws Exception{
// windows版本设置HADOOP_HOME环境变量后,若不重启电脑,需要填加该语句
//System.setProperty("hadoop.home.dir", "C:/Development/hadoop");
System.setProperty("hadoop.home.dir", "/usr/local/hadoop");
// 设置操作用户,默认root
System.setProperty("HADOOP_USER_NAME", "root");
//创建Configuration
Configuration configuration = new Configuration();
// 设置fs.defaultFS参数,默认本地读取
configuration.set("fs.defaultFS", "hdfs://master:9000");
// 若参数数量不为2,报错退出,第一个参数读取是输入目录(HDFS),第二个参数是输出目录
if (args.length != 2) {
System.err.println("Usage: MyDriver <in> <out>");
System.exit(2);
}
// 如果输出目录存在,则删除
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(configuration);
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
//创建Job
Job job = Job.getInstance(configuration, "wordcount");
//设置job的处理类
job.setJarByClass(WordCountApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
//设置Map阶段的输出类型: k2 和V2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//分区,排序,规约,分组步骤采用默认方式
//设置reduce相关参数
job.setReducerClass(MyReducer.class);
//设置Reduce阶段的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
IDEA配置
编辑运行环境
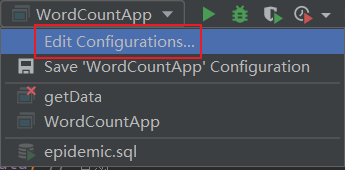
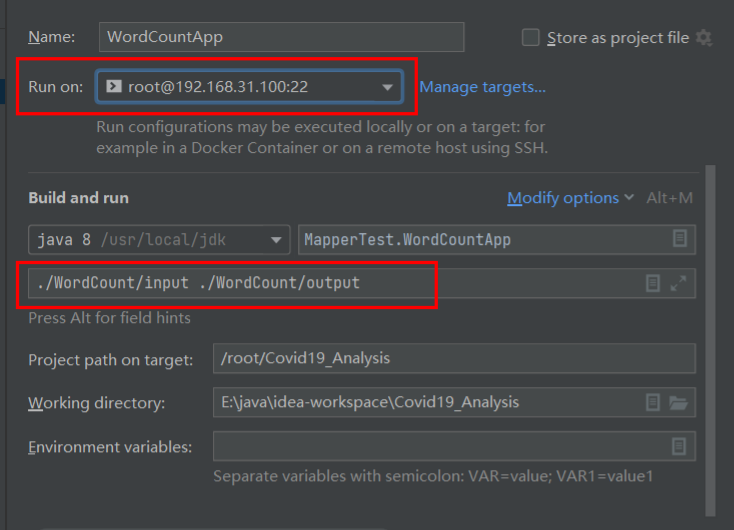
使用远程环境,设置ssh连接,添加input和output目录
Debug
运行hadoop MapReduce程序常见错误及解决方法整理_海兰的博客-CSDN博客
标签:入门,WordCount,hadoop,MapReduce,job,import,apache,org,log4j 来源: https://www.cnblogs.com/dominickk/p/16361606.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。