标签:副本 入门 zk ISR 更新 KAFKA follower 失效
大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于 KAFKA 的学习和实战经验,希望对大家有所帮助,目录形式依旧为问答的方式,相当于是模拟面试。
一、前言
可能有些朋友发现之前空缺了第六节,是因为之前写了没来得及完善就一直搁置了,因此在这儿后续补上。
二、概述
我们了解 ISR 列表是不断伸缩的,在副本失效后及时踢出 ISR 列表,在副本赶上进度之后重新将副本加入到 ISR 列表中,后面我们就会按照这个思路来看下其中细节。
三、什么是失效副本?
功能失效:节点宕机,在该节点上的副本都属于功能失效副本。
同步失效:follower 副本所在的 broker 因为带宽或者负载等因素无法及时完成同步,导致被踢出 ISR。
四、ISR 伸缩控制参数了解吗?
在 0.9x 版本之前,有一个控制参数:replica.lag.max.messages 默认值为 4000,表示如果 follower 的消息个数落后 leader 个数 4000,那么就会被踢出 ISR 列表;
我们可以想一下这种直接指定条数的方式是否合理呢?显然是不合理的,原因入下:
高吞吐的场景:瞬间就几万条消息,可能 follower 就滞后个几秒钟就被判定为失效从而被踢出,可能导致 ISR 列表频繁的变动,以及元数据的频繁更新。
低吞吐的场景:可能一天就几条消息,那可能 follower 都滞后好几天了依旧存在于 ISR 中,那 ISR 不就失去意义了吗?
因此 0.9x 版本开始,移除了该参数,取而代之的参数是 replica.lag.time.max.ms 该参数默认值是 10000ms,也就是 10s。
也就是说如果 follower 在 10s 都没能追上 leader 的 LEO,就会被认定为失效,从而踢出 IS 列表。
五、ISR 是如何将失效副本剔除的?
我们知道了 ISR 是如何判定失效副本后,再来看下,到底是怎么把这个失效的副本踢出去的呢?
1、每个 broker 在启动的时候都会启动两个定时任务:
- isr-expiration:定时检查当前 broker 上的 eader 对应的副本失效信息,也就是看当前 Leader 的 ISR 列表中是否存在失效副本,默认执行周期为
replica.lag.time.max.ms / 2 = 5s。 - isr-change-propagation:定时检查内存 isrChangeSet 中是否有新的变更数据,固定执行周期为 2.5s
2、判断副本失效:
isr-expiration 任务会根据当前时间 now,减去某 follower 的 lastCaughtUpTimeMs,如果大于 replica.lag.time.max.ms 值,则说明失效。
而 lastCaughtUpTimeMs 这个值,在 follower 的 LEO 与 leader 的 LEO 相等时 (Leader 中维护了 follower 的 LEO 信息),被更新。
也就是说,只有当 follower 完全追上了 Leader 才更新,而不是每 Fetch 一次就更新。
关于为什么不是每次 Fetch 的时候就更新该值呢?
我们试想一下,如果 leader 的写入速率远大于 follower 的同步速率,可能 leader 已经写了 10w 条数据了,follower 由于网络 / 负载为原因还在慢悠悠的同步,但是因为 Fetch 请求是正常发送的,就每次都更新 lastCaughtUpTimeMs 值,从而认为该 follower 是有效的,那这不就导致 leader 和 follower 之间在这种场景下存在巨大的数据差异了嘛?从而影响数据的可靠性。
3、这个 ISR 变化的信息如何传递呢?
- 由 leader 所在的 broker 的
isr-expiration定时任务,去检查失效副本和更新 zk 的 /state 节点数据,同时写入isrChangeSet。 isr-change-propagation去检查 isrChangeSet 是否有新增数据,如果有,则往 zk 中的/isr_change_notification节点下创建子节点。- 而 Controller 对这个节点有一个 Watcher,如果发现新增了子节点,那么 Controller 就会重新从 zk 中获取到最新的元数据,然后通知所有 Broker 更新元数据。
从上述过程中,我们还可以知道,实际上这个变更的数据会在内存中停留一段时间,假如这个时候我们对应的 broker 宕机了,那么不就是改了 zk 却没有让其他 broker 更新元数据吗?
其实不是,因为这种情况下,broker 宕机会触发 controller 在 zk 下的 brokers/ids 下对应的节点被删除,因此 Controller 也会让其他的 broker 更新元数据,所以无论如何都会更新。
最后我们来总结一下整个 ISR 剔除的过程:
每个 leader 在启动的时候都会启动两个定时检查任务,每隔一段时间检查是否存在失效副本。
如果某个 follower 的 lastCaughtUpTimeMs > 10s 那么就会被判定为失效副本
如果定时任务扫描到存在失效副本时,就会往 zk 的 /state 节点下更新最新的 ISR 列表数据,同时将变更数据写入到内存中的 isrChangeSet 中。
然后另外一个传播任务会定时检查 isrChangeSet 是否存在需要变更的任务,如果感知到就往 zk 的 /isr_change_notification 节点下创建子节点。
最终由 Controller 感知到节点的变化,然后从 zk 中获取最新的元数据,然后通知所有的 Broker 更新元数据,完成整个 ISR 列表的数据更新。
六、追赶上的副本是如何重新加入 ISR 中的?
在看完第五小节之后,第六小节就会显得非常简单,无非是需要知道什么时候一个副本会重新判定为同步副本呢? 那就是:当前失效 follower 的 LEO 等于 leaderHW 的时候,即被判断可以重新加入 ISR。
那么随之而来的一个问题就是在哪儿去判断 followerLEO == leaderHW 的呢?
这里和上面的剔除 ISR 成员不一样,并不是由定时任务去检测的,而是在处理完 Fetch 请求的时候,如果判断 Fetch 请求是 follower 发过来的的(replicaId >= 0),那么就会去看下当前这个 follower 的 LEO 是多少(其实就是 Fetch 请求带过来的),是不是赶上了当前的 leaderHW,如果是的那么就执行扩张 ISR 操作。
扩张 ISR 操作流程就和上面流程一样了,先写 zk 下的 /state 数据,然后写 isrChangeSet,最后由 Controller 感知到数据变化,更新集群元数据。
我们所需要记住的主要差别点在于,ISR 列表的扩张是在 Fetch 请求的时候去判断和执行的。
七、整个伸缩过程总结
最后,我们用图示来加深一点印象。
1、失效副本(图源:《深入理解 kafka》):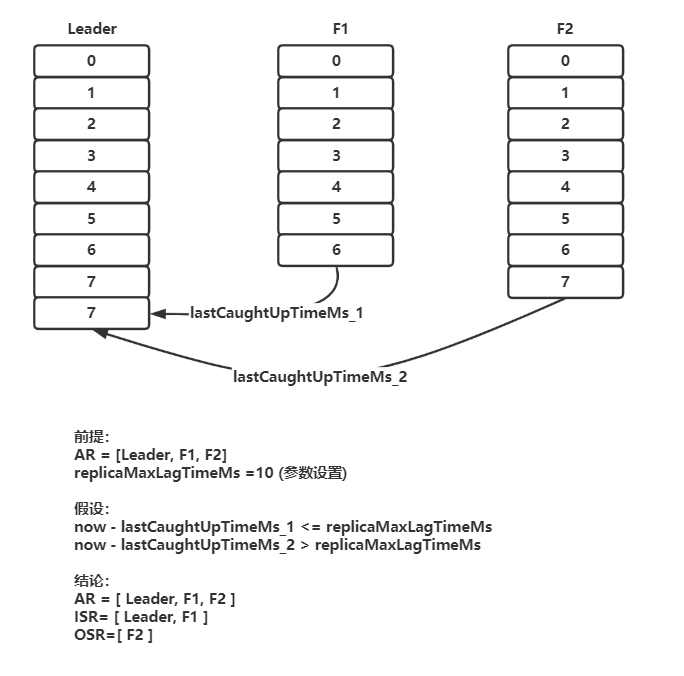
2、踢出 ISR 列表: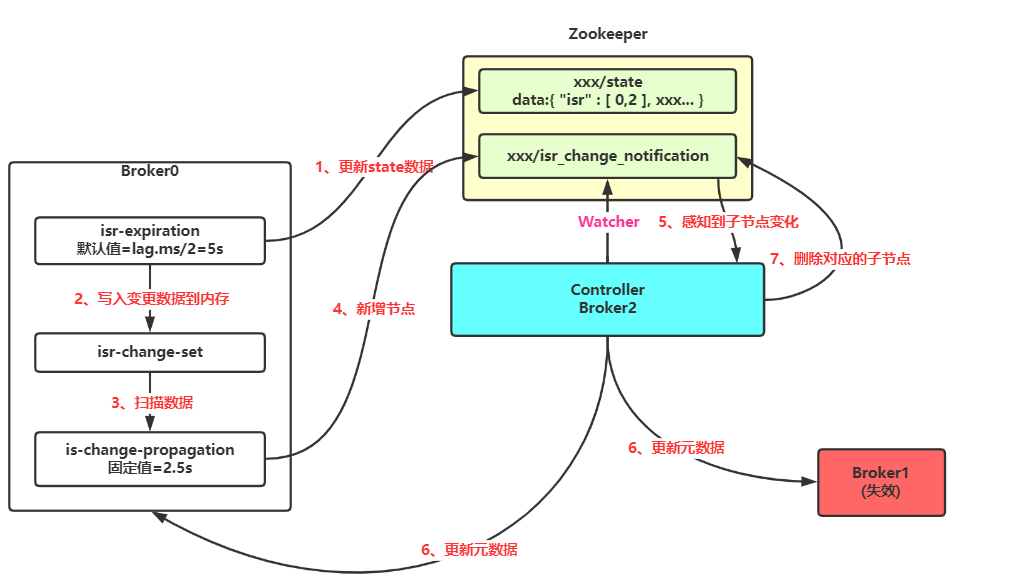
3、重回 ISR 列表: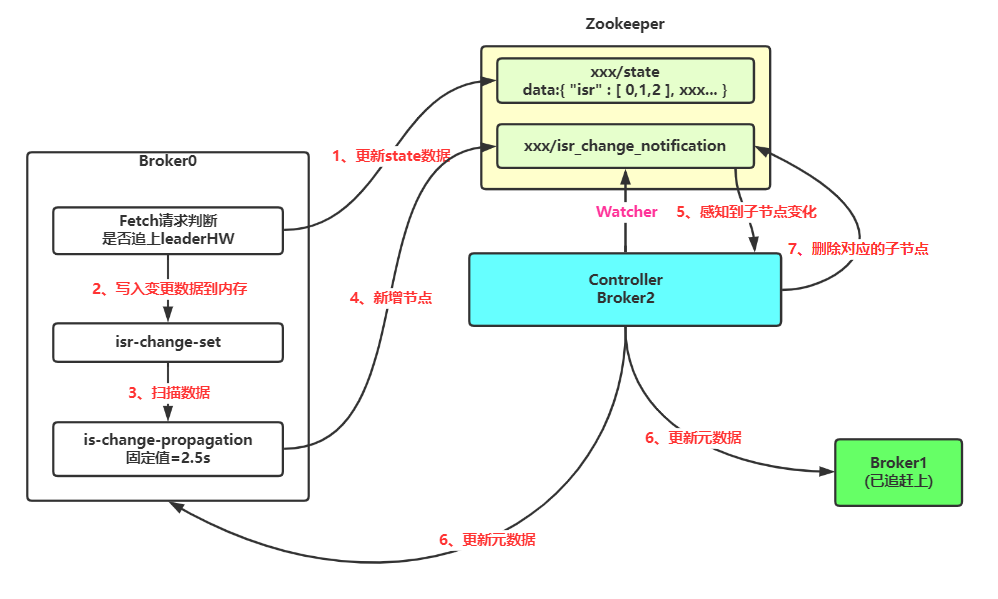
八、性能优化
我们由上可知,ISR 的伸缩是需要涉及到 zk 和 Controller 以及各个 Broker 的元数据更新的,因此如果太过频繁会造成性能问题。
所以 kafka 在在判断 ISR 伸缩之前,还会判断两个条件,以此来降低频率:
- 上次 ISR 集合发生变化距离现在已经超过 5s。
- 上一次写入 zk 的时候,距离现在已经超过 60s。
如果一个副本刚追上 Leader 加入到 ISR,但是因为短时间内没有追上 LEO,5s 之后又被检查到是失效副本,不是又要被踢出去,要更新元数据,这样就太频繁了。 因此就有了上面两个限制,就起码给了多 60s 的让新加入的 follower 去追上 Leader 的 LEO。
最后,后续有时间我们结合这一小节具体分析一下源码,让细节更加完善 ^_^
标签:副本,入门,zk,ISR,更新,KAFKA,follower,失效 来源: https://www.cnblogs.com/keepal/p/16341759.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。