标签:responses batch send KAFKA 线程 error kafka response 客户端
大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于 KAFKA 的学习和实战经验,希望对大家有所帮助,目录形式依旧为问答的方式,相当于是模拟面试。
什么是生产者的?
生产者的概念其实非常简单,一句话概括就是:负责生产消息发送到 kafka 的服务端。
但是为什么要单独拎出来放在最前面呢?因为看似简单的一件事却有很多门道,例如:
如何与 Broker 建立连接呢?
如何做发送消息的负载均衡呢?
如何做到高性能呢?
如何确认发送的消息的成功与否呢?
...
kafka 的生产者客户端设计的非常巧妙,非常值得学习。
本文会按照生产消息的顺序一步步去梳理,希望大家看完后能对上面的问题有自己的答案。
我们需要先了解,kafka 的生产者客户端只有两个线程:业务线程 (主线程) 和 Sender 线程 (网络线程)
初始化
首先我们来看看,KafkaProducer 是如何初始化的。
源码太长了,我这里就不贴了,大家可以自行查阅,我这里就直接概括一下,分为三个部分:
1、设置公共的生产者参数,例如 [maxRequestSize][totalMemorySize][compressionType] 等
2、设置拦 - 截器、分区器、序列化器这三个关键组件
3、启动 Sender 线程
我们需要注意的一点是,KafkaProducer 在初始化的时候并不会与 Broker 建立连接,而是在第一次调用 Send 的时候才会去检查对应的分区元数据,如果不存在,则会向任一节点请求 metadata。
接着从 metadata 中拿到目标分区 Leader 所在的 Broker 的地址,最终建立连接开始通信。
主线程
主线程,也叫作业务线程。顾名思义,这个线程主要的职责就是处理我们要发送业务数据,拦 - 截、序列化、分区、打包等,最终按分区放入 RecordAccumulator 缓冲区中。
拦 - 截器
拦 - 截器非常好理解,无非就是拦 - 截一部分消息。
具体要拦 - 截哪些消息呢?这个就是根据你自己的业务来配置了,kafka 提供了对应的配置 [interceptor.classes]
你可以通过实现 [ProducerInterceptor] 接口来实现你想要的拦 - 截效果。
在生产者发送消息的流程中,它是最先生效的,对应的源码如下:
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
序列化器
同上,也是很好理解,就是将我们要发送的消息按照我们指定的序列化器进行序列化。
kafka 也提供了对应的配置:[key.serializer][value.serializer]
温馨提示,我们在配置的时候,最好不要直接写上面的这种字符串,而是通过以下方式。
这样可以避免拼写错误。ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG
分区器
顾名思义,这个组件是用来将数据进行分区的,我们一般来说都会采用默认的分区器,让我们来看下这个默认实现的代码
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
我来翻译一下:
- 如果指定了 Key 呢,那么就按照 Key 的 hash 值进行分区选择,并且无论这个分区是否存在有效副本都会进行选择。(一般用于要求数据顺序的场景,但是可能会导致 Topic 的分区数据不均衡)
- 如果没有指定 Key,那么就根据当前存活的分区进行轮询。
Batch 批处理
在业务消息被序列化好之后,kafka 会将消息进行按照分区进行打包成 Batch。
我们先思考一下,为什么要设计这么一个机制呢?
批处理是一个经典的用时延换取吞吐的设计。如果下游系统的处理 1 条消息和 100 条消息的速度基本相同,并且我很快就能积累到 100 条消息,那我何不积累到 100 条消息再一起发送到下游系统呢?这样可以把 100 次网络请求直接缩减成 1 次,节约了巨大的网络开销,吞吐量也得以提升,唯一的影响就是需要等待一段时间,处理时延增大了。
kafka 的生产者就是采用了这个设计,设计了两个参数:
- linger. ms:等待组包的时间,默认是 0,也就是不等待,因此我们想打到上诉的提升吞吐的效果,把这个值调大是一个不错的选择,如果消息时延不敏感的话。10ms 和 15ms 都是 ok 的。
- batch.size:组包的最大大小,默认是 16Kb。也就是最多一个 Batch 只能有这么大,但是如果上面的那个参数是 0,那么这个参数也是没有意义的。
另外,这个参数还涉及到后续缓冲区的内存复用,这个参数代表着 RecordAccumulator 缓冲区中的内存复用粒度,如果你单条消息超过了这个设置的大小,那么会导致缓冲区中的内存复用失效,从而导致 GC 负担增加,整体吞吐量下降。所以如果你得业务消息比较大的话,可以考虑设置这个参数。
RecordAccumulator 缓冲区
接下来就是我们的主角缓冲区,这个缓冲区是干嘛的呢?
也是非常直观,就是相当于是一个内存队列,把刚才封装好的 Batch 暂存一会儿,等待后续的 Sender 线程来消费。
我们可以把这个缓冲区简单的理解为一个 Map,事实上它也确实是一个 Map,但是由于 Java 的 KafkaProduer 是线程安全的,由此呢选用的是 [CopyOnWriteMap]:ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batchesthis.batches = new CopyOnWriteMap<>();
从上面的代码我们可以知道,实际上 Batch 是按照 TopicPartition 进行分类保存的。
同时呢,[CopyOnWriteMap] 显然是一个快照实现形式的 Map,最大的特点就是线程安全,写的时候需要同步操作,但是读的时候可以非同步,因此适合读多写少的场景。想想我们在发送数据的时候,是不是很少改变已选定的分区呢?大多数的场景都是业务线程追加写 batches,然后 Sender 线程从 batchs 队列中读,很少改动这个 Map 本身,由此完美的适合当前的场景。看到这里都得感叹一下一个优秀的中间件是无数的技术积累与应用。
另外,RecordAccumulator 缓冲区的大小是可以设置的,参数:buffer.memory
这个默认值是 32M,通常来说是够用的。而且内部做了内存池,可以复用内存,减少内存回收对 GC 的负担。
当然,如果说你的业务线程很猛,但是 Sender 线程不给力,是可能把这个缓冲区写满的,此时你的业务线程会被阻塞默认 60s,如果 60s 内还不能成功,就会向上抛出异常。
控制这个等待时间的参数:max.block.ms
最后,我们来用一张图概括一下我们的主线程做了哪些事情?
Sender 线程
当消息写到 RecordAccumulator 缓冲区之后,主线程的事情就已经完成了,接下来是我们 Sender 线程的时间。
Sender 线程的主要职责呢,分为三部分:
- 从 RecordAccumulator 缓冲区拉取 Batch,按照 Broker 进行分类封装成 Request。
- 将 Request 通过 socketChannel 发送给指定的 Broker。
- 得到这请求的具体结果 (成功 / 失败 / 超时) 后,将结果通过回调的方式告诉用户。
从上可知,我们 Sender 线程的职责是非常重的,因此我们通常不建议用户在自己设置的回调函数中执行太重的操作,例如更新 db,远程调用等等。
因为稍有不慎会导致 Sender 线程卡顿无法高效的发送数据,甚至造成数据发送超时。
请求转换
我们先看下数据是怎么拉取出来的:
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
看,非常直观。但是有的同学可能会问,为什么需要再转换一次才封装成请求呢?
我们再考虑一下,刚才在 RecordAccumulator 中,我们的 Batch 是按照 partition 进行分类存放的。我们的 partition 可能有几十上百个,但是我们的 Broker 也就只有几个,那我们是不是可以再进行一次聚合?将这些不同的 partition,但是他们 leader 所在相同节点的数据聚合起来封装成一个 Request,再进行发送,是不是又减少了网络请求的次数?就很妙。
但是需要注意的是,Sender 从 accumulator 中取数据的时候,不是一次性把 batchs 队列取完,而是只取队头的那个 Batch,其余的 Batch 继续在 accumulator 中等待,如果等待的时间达到了 request.timeout.ms 那么就会超时被清除,然后通知上层用户。
出现超时的原因,大概率都是用户设置的回调耗时太长,导致 Sender 线程无法高效的工作。当然也存在其他异常情况,例如 GC、网络、带宽等等,具体问题具体分析。
InFlightRequests
当数据被按照 Broker 进行分装成 Reuquest 后,就需要进行发送了。但是在发送的时候呢,kafka 把即将发送出去的请求放入 InFlightRequests 这么个队列中。
这个队列的作用就是用来记录当前给哪些 Broker 发送了多少请求了,等待 Broker 响应之后再根据对应的请求 id 去清除掉 InFlightRequests 中的数据。对应的源码:
Send send = request.toSend(nodeId, header);
InFlightRequest inFlightRequest = new InFlightRequest(
header,
clientRequest.createdTimeMs(),
clientRequest.destination(),
clientRequest.callback(),
clientRequest.expectResponse(),
isInternalRequest,
request,
send,
now);
this.inFlightRequests.add(inFlightRequest);
selector.send(inFlightRequest.send);
我们再来看下这个 InFlightRequests 是个什么结构:
final class InFlightRequests {
private final Map<String, Deque<NetworkClient.InFlightRequest>> requests = new HashMap<>();
很简单,就是个 HashMap,key 是 brokerId,value 是向这个 Broker 发送的请求队列。
这里为什么是非线程安全的 HashMap 呢?因为 Sender 线程是单线程哒~不会有线程安全问题。
这个 Map 也是有限制的,什么限制呢?一个 Broker 只能接收 N 个请求发出去了还没收到响应。
翻译一下就是,这个 Map 的 value 的那个队列限制长度默认是 5,如果超过这个限制会直接向上层抛异常,kafka 控制该长度的参数是:max.in.flight.requests.per.connection 在发送请求前,kafka 会检查这个节点的状态,以及这个 InFlightRequests 中的队列情况,源码如下:
private boolean canSendRequest(String node) {
return connectionStates.isReady(node) && selector.isChannelReady(node) && inFlightRequests.canSendMore(node);
}
public boolean canSendMore(String node) {
Deque<NetworkClient.InFlightRequest> queue = requests.get(node);
return queue == null || queue.isEmpty() ||
(queue.peekFirst().send.completed() && queue.size() < this.maxInFlightRequestsPerConnection);
}
这里再提一下,请求如果在 InFlightRequests 呆的时间超过了前面提到的超时时间,一样会报超时的信息,具体原因和排查思路同上。
kafka 生产者报超时的地方就两处:RecordAccumulator 缓冲区和 InFlightRequests
Selector
这里的 Selector 顾名思义就是 Nio 里面的多路复用器。不过 kafka 自己基于 java 原生的 Selector 封装了一层,但是名字没改,我们就默认叫 kafkaSelector 吧,避免混淆。
其实这个 kafkaSelector 的职责很明显,就是将 Reuqest 发送出去,但是这里需要注意的是,这里不是同步发送,而是就给对应封装的 channel 设置了 send,然后设置关注 OP_WRITE 事件就返回了。 代码入下:
public void setSend(Send send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
后续的发送动作,是这一行关键代码:client.poll(pollTimeout, now);
kafka 自己去写的一套网络底座,而这个网络底座的核心类就是这个 NetworkClient
整个核心的 poll 函数的代码如下,涵盖了生产端 / Broker 端 / 消费端的网络通信逻辑:
@Override
public List<ClientResponse> poll(long timeout, long now) {
if (!abortedSends.isEmpty()) {
// If there are aborted sends because of unsupported version exceptions or disconnects,
// handle them immediately without waiting for Selector#poll.
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
return responses;
}
这个类分析起来实在太长了,我们就去看看到底是在哪儿发送出去的就好了:
/* if channel is ready write to any sockets that have space in their buffer and for which we have data */
if (channel.ready() && key.isWritable()) {
Send send = null;
try {
send = channel.write();
} catch (Exception e) {
sendFailed = true;
throw e;
}
if (send != null) {
this.completedSends.add(send);
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
private boolean send(Send send) throws IOException {
send.writeTo(transportLayer);
if (send.completed())
transportLayer.removeInterestOps(SelectionKey.OP_WRITE);
return send.completed();
}
public long writeTo(GatheringByteChannel channel) throws IOException {
long written = channel.write(buffers);
if (written < 0)
throw new EOFException("Wrote negative bytes to channel. This shouldn't happen.");
remaining -= written;
pending = TransportLayers.hasPendingWrites(channel);
return written;
}
其实,最终还是调用的 Java 底层的 Nio 去进行的数据发送,不过把这个 Channel 设置了非阻塞。
这里其实还涉及数据要是一次性没发完怎么处理,其实也很简单,就是这次事件没写完,我就记录一个 remaining,等待下一次 OP_WRITE 事件,直到这 Request 写完为止。
回调
在数据发送出去之后,我们就只能等待响应。
这个等待的结果有以下的情况:
- 等待超时,请求被清理后告知上层业务。
- 等到响应,返回成功,清除 RecordAccumulator 中的 Batchs 和 InFlightRequests 中的 Request,执行回调。
- 等到响应,返回可重试异常 (网络异常 / 部分节点不可用等),如果设置了重试次数,在达到重试次数前不向上层反馈,并在重试间隔 (默认 100ms) 后进行重试,重试的请求中的 Batchs 会重新进入 RecordAccumulator 缓冲区,但是它会插队,会直接到队列头部,让下一次 Sender 就去发送它们。
- 等到响应,返回不可重试异常 (消息太大了),清除 RecordAccumulator 中的 Batchs 和 InFlightRequests 中的 Request,直接报异常,让上层感知。
对应的源码入下:
private void handleCompletedReceives(List<ClientResponse> responses, long now) {
for (NetworkReceive receive : this.selector.completedReceives()) {
String source = receive.source();
InFlightRequest req = inFlightRequests.completeNext(source);
Struct responseStruct = parseStructMaybeUpdateThrottleTimeMetrics(receive.payload(), req.header,
throttleTimeSensor, now);
if (log.isTraceEnabled()) {
log.trace("Completed receive from node {} for {} with correlation id {}, received {}", req.destination,
req.header.apiKey(), req.header.correlationId(), responseStruct);
}
AbstractResponse body = AbstractResponse.parseResponse(req.header.apiKey(), responseStruct);
if (req.isInternalRequest && body instanceof MetadataResponse)
metadataUpdater.handleCompletedMetadataResponse(req.header, now, (MetadataResponse) body);
else if (req.isInternalRequest && body instanceof ApiVersionsResponse)
handleApiVersionsResponse(responses, req, now, (ApiVersionsResponse) body);
else
responses.add(req.completed(body, now));
}
}
其实就是: responses.add(req.completed(body, now)); 这一行把对应的回调设置给了 responses。 然后最后,遍历这些 responses,逐一执行原先保存在 req 中对应的回调函数:
private void completeResponses(List<ClientResponse> responses) {
for (ClientResponse response : responses) {
try {
response.onComplete();
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
public void onComplete() {
if (callback != null)
callback.onComplete(this);
}
不过还需要注意的一点是,在执行业务回调之前,会先执行 kafka 设置的 internelHandler 回调。 在这个回调中会进行上诉的收到请求后的各种情况。
private void handleProduceResponse(ClientResponse response, Map<TopicPartition, ProducerBatch> batches, long now) {
RequestHeader requestHeader = response.requestHeader();
int correlationId = requestHeader.correlationId();
if (response.wasDisconnected()) {
log.trace("Cancelled request with header {} due to node {} being disconnected",
requestHeader, response.destination());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NETWORK_EXCEPTION), correlationId, now);
} else if (response.versionMismatch() != null) {
log.warn("Cancelled request {} due to a version mismatch with node {}",
response, response.destination(), response.versionMismatch());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.UNSUPPORTED_VERSION), correlationId, now);
} else {
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
TopicPartition tp = entry.getKey();
ProduceResponse.PartitionResponse partResp = entry.getValue();
ProducerBatch batch = batches.get(tp);
completeBatch(batch, partResp, correlationId, now);
}
this.sensors.recordLatency(response.destination(), response.requestLatencyMs());
} else {
// this is the acks = 0 case, just complete all requests
for (ProducerBatch batch : batches.values()) {
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NONE), correlationId, now);
}
}
}
}
private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response, long correlationId,
long now) {
Errors error = response.error;
if (error == Errors.MESSAGE_TOO_LARGE && batch.recordCount > 1 &&
(batch.magic() >= RecordBatch.MAGIC_VALUE_V2 || batch.isCompressed())) {
// If the batch is too large, we split the batch and send the split batches again. We do not decrement
// the retry attempts in this case.
log.warn("Got error produce response in correlation id {} on topic-partition {}, splitting and retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts(),
error);
if (transactionManager != null)
transactionManager.removeInFlightBatch(batch);
this.accumulator.splitAndReenqueue(batch);
this.accumulator.deallocate(batch);
this.sensors.recordBatchSplit();
} else if (error != Errors.NONE) {
if (canRetry(batch, response)) {
log.warn("Got error produce response with correlation id {} on topic-partition {}, retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts() - 1,
error);
if (transactionManager == null) {
reenqueueBatch(batch, now);
} else if (transactionManager.hasProducerIdAndEpoch(batch.producerId(), batch.producerEpoch())) {
// If idempotence is enabled only retry the request if the current producer id is the same as
// the producer id of the batch.
log.debug("Retrying batch to topic-partition {}. ProducerId: {}; Sequence number : {}",
batch.topicPartition, batch.producerId(), batch.baseSequence());
reenqueueBatch(batch, now);
} else {
failBatch(batch, response, new OutOfOrderSequenceException("Attempted to retry sending a " +
"batch but the producer id changed from " + batch.producerId() + " to " +
transactionManager.producerIdAndEpoch().producerId + " in the mean time. This batch will be dropped."), false);
}
} else if (error == Errors.DUPLICATE_SEQUENCE_NUMBER) {
// If we have received a duplicate sequence error, it means that the sequence number has advanced beyond
// the sequence of the current batch, and we haven't retained batch metadata on the broker to return
// the correct offset and timestamp.
//
// The only thing we can do is to return success to the user and not return a valid offset and timestamp.
completeBatch(batch, response);
} else {
final RuntimeException exception;
if (error == Errors.TOPIC_AUTHORIZATION_FAILED)
exception = new TopicAuthorizationException(batch.topicPartition.topic());
else if (error == Errors.CLUSTER_AUTHORIZATION_FAILED)
exception = new ClusterAuthorizationException("The producer is not authorized to do idempotent sends");
else
exception = error.exception();
// tell the user the result of their request. We only adjust sequence numbers if the batch didn't exhaust
// its retries -- if it did, we don't know whether the sequence number was accepted or not, and
// thus it is not safe to reassign the sequence.
failBatch(batch, response, exception, batch.attempts() < this.retries);
}
if (error.exception() instanceof InvalidMetadataException) {
if (error.exception() instanceof UnknownTopicOrPartitionException)
log.warn("Received unknown topic or partition error in produce request on partition {}. The " +
"topic/partition may not exist or the user may not have Describe access to it", batch.topicPartition);
metadata.requestUpdate();
}
} else {
completeBatch(batch, response);
}
// Unmute the completed partition.
if (guaranteeMessageOrder)
this.accumulator.unmutePartition(batch.topicPartition);
}
最后再提一句,如果实在 InflightRequests 中超时的请求,也会被处理成 responses,在 NetworkClient 的 handleTimedOutRequests(responses, updatedNow); 函数中。
整个 Sender 线程,用图来表示一下: 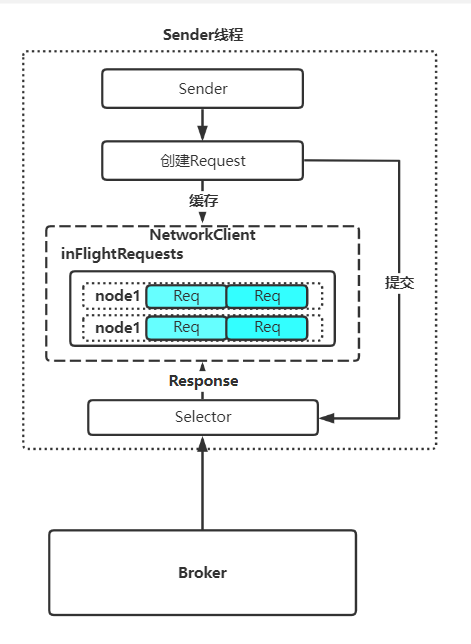
总览
最后的话,咱们用一张流程图来概括一下 kafkaProducer 的整体流程: 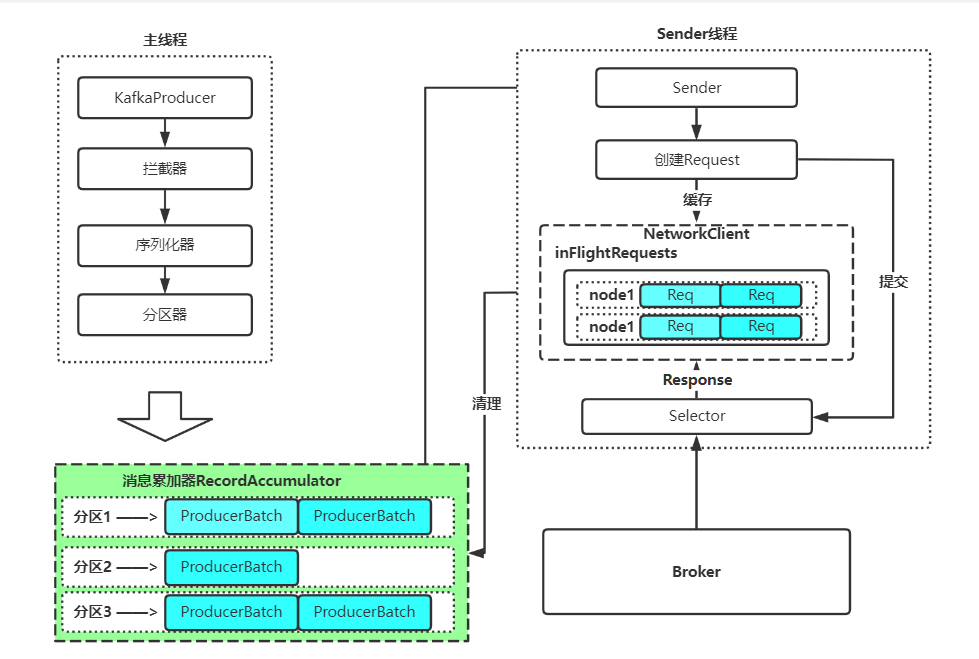
本来想做入门篇的,但是一不小心快写成源码解析了。
我想很多同学都看不到这里,哈哈哈哈哈。
标签:responses,batch,send,KAFKA,线程,error,kafka,response,客户端 来源: https://www.cnblogs.com/keepal/p/16341769.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。