标签:Scale 服务 请求 实例 t1 耗时 Tail 详解 分位
简介
用户体验与软件的流畅程度是呈正相关的,所以对于软件服务提供方来说,保持服务耗时在用户能接受的范围内就是一件必要的事情。但是在大型分布式系统上保持一个稳定的耗时又是一个很大的挑战,这篇文章解析的是google发布的一篇论文《The Tail At Scale》,里面讲述的是google内部的一些长尾耗时优化相关的经验,以及我个人的一些思考。
服务耗时为什么会产生抖动
在目前大规模的分布式系统中,服务与服务之间的调用关系可以呈现为下图的形式,服务A,B都有多个实例,服务A实例通过服务发现模块找到下游服务B上的实例,通过调度算法决定调用服务B上的具体实例的接口(关于服务发现的实现阿里有相关的开源项目Nacos,文档:https://www.yuque.com/nacos/ebook)。这个时候服务A实例调用服务B实例的耗时= 网络往返的时间+服务B实例执行请求的耗时。这里影响耗时的因素分为以下两个大类:
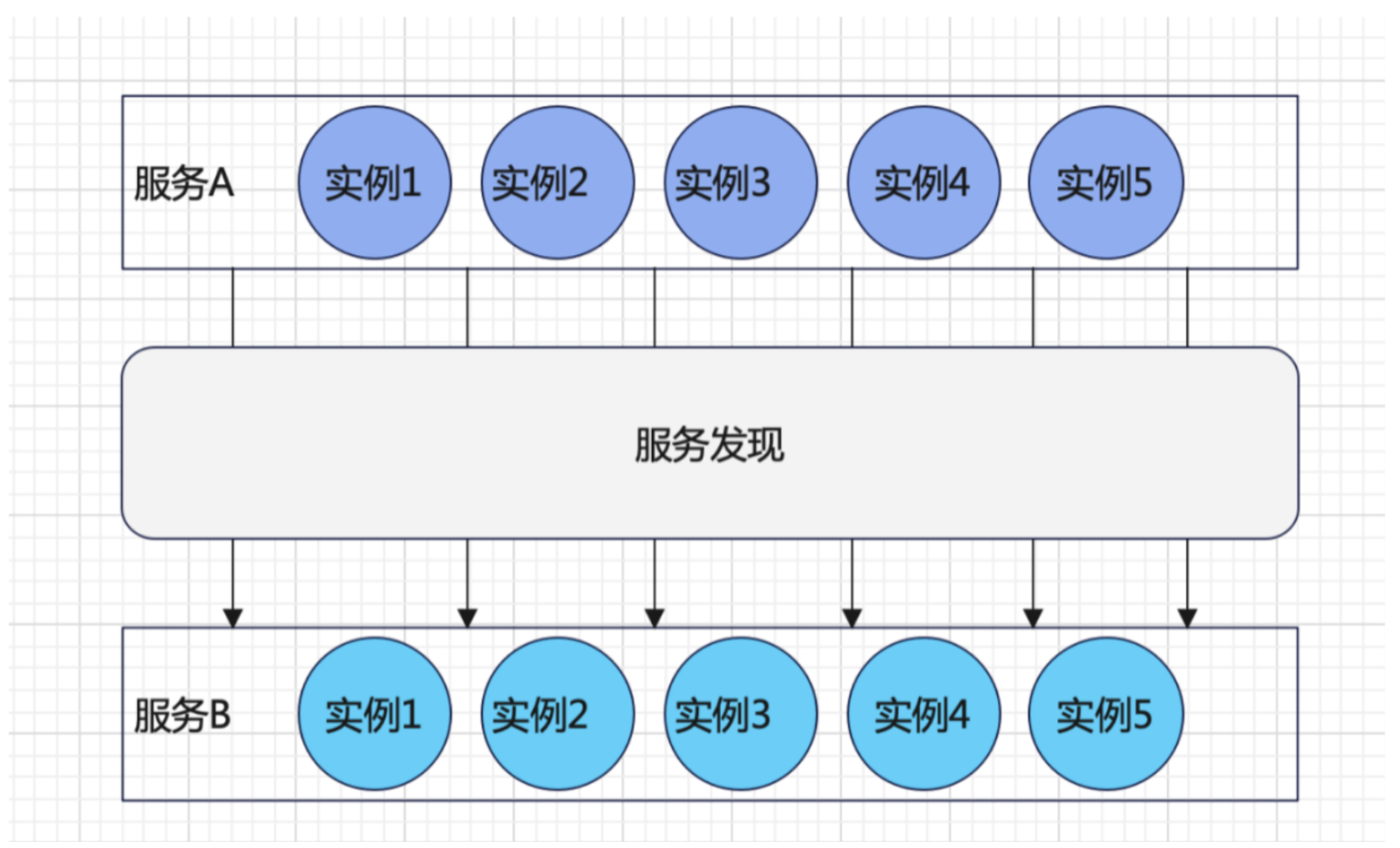
网络因素的影响
-
传输链路上的耗时差异。服务与服务之间的调用,不论是webSocket,Rpc调用还是Http,到了运输层无非是两种选择,TCP和UDP,在发送网络包的过程中,发送方和接收方会保持这个网络连接,而无法感知下面网络层,数据链路层发生的事情,数据包经过的链路是由网络层的寻路算法决定,当前这个数据包和下一个数据包走的链路可能完全不一样。可能有的链路比较拥堵,有的链路比较快。所以这里可能会对请求与请求之间的耗时差异造成影响。
-
数据排队。在网络数据到达机器网卡的时候,Linux会执行一个中断,切换到中断程序来标志这个数据已经到来,然后继续执行中断之前正在执行的程序,在后续进程调度中会切换到等待该数据到来的线程时会读取这个数据包,然后走后续的业务逻辑。那么从标志数据到来到获取数据这两者之间就会存在很多不预知的因素,比如CPU调度守护进程,触发了GC的STW。遇到这些情况都会拖慢这个请求的处理。
服务实例本身对耗时的影响
-
全局共享资源。服务内部可能会对一些全局的资源进行竞争。当竞争激烈的时候可能会存在线程饥饿的状态,长时间无法获得锁会导致请求耗时明显增大。
-
CPU过载。现代CPU会有保护自己的措施,当CPU过热的时候就会有降低执行指令的速度,从而达到保护CPU的作用。
-
GC。STW会停止所有正在工作的线程。
组件的耗时抖动对集群的影响
组件级别的耗时抖动对大规模分布式服务的耗时影响是很大的,论文中将服务响应耗时大于1s视为不可用的响应,得到了下面这幅图:

图中横轴表示一个请求链路上服务器的个数,纵轴表示的是服务响应不可用的概率,蓝线表示一台机器上百分之一的请求耗时大于1s,红线表示一台机器上千分之一的请求耗时大于1s,绿线表示万分之一请求耗时将大于1s。图中的X点表示的是在每台机器百分之一请求耗时将大于1s的情况下,一个请求要经过100台机器,将会有百分之63的请求耗时大于1s,也就是服务不可用状态将达到63%。这个是比较好理解的,如果一台机器上耗时大于1s的概率为1%,那么链路长度为100的的链路上请求耗时大于1s的概率为1 - 99% ^ 100 = 63%。
下图google内部服务真实的统计数据如下图所示,横向表示50%分位耗时,95%分位耗时,99%分位耗时,纵向表示请求链路中其中一个下游完成的时间,其中95%下游执行完毕的时间,100%下游执行完毕的时间。可以得出的结论:
-
纵向看,不论是请求链路中一个下游的完成的时间还是95%,100%下游完成的时间,两两之间差别都很大,95%的下游完成时间与100%下游完成时间相差一倍多点。
-
不论是1个下游,95%下游,还是100%下游,50分位耗时,95分位耗时,99分位耗时,相差也很大,95%分位耗时和99%分位耗时相差近一倍。

对于上图这种情况,99分位耗时远比95分位高,假设现在是一个服务弹性伸缩的场景,我们以服务的99或者99.9分位作为服务健康状态的判断标准之一,99分位过高,但是95分位表现是正常的,这样会给我们造成误判,认为服务状态并不健康,从而扩容我们的服务集群,虽然这对降低99分位是有帮助的(因为扩容的机器分摊了一部分流量),但是这样做的性价比并不高,因为大多数的请求处理情况是正常的。所以优化耗时抖动是必要的,下面介绍几种优化耗时抖动的策略。
减少服务组件的耗时抖动
-
服务等级分类和请求优先队列。一个服务会提供一个或者多个接口,可以定义接口的优先级,让优先级高的接口优先请求,优先级低或者对耗时不敏感的接口请求靠后执行。
-
减少线头阻塞。在网络交换机里面,分位输入端口,交换单元,输出端口,如果一个输入端口之中的数据要输出到多个输出端口,就需要排队,通过减少线头阻塞,可以降低网络传输的耗时。
-
管理后台任务和请求并行化。对一些后台任务进行有效的管控,比如日志压缩,GC,可以在服务状态良好的时候进行。并且一些对下游的请求如果两者之间没有互相依赖,是可以并行执行的。
请求维度耗时抖动优化
对于请求级别的优化,论文中提出了两种优化方案,分别是对冲请求和并行请求。
1.对冲请求
既然99分位耗时比95分位耗时大一倍,那么如果在请求等待响应时间已经大于95分位耗时的时候可以重发一个相同的请求,采用两个请求中首先返回的结果。在google的相关实践中,对冲请求带来的效果是很明显的。
2.对冲请求分析
从上面的分析看,因为涉及请求之间的同步和请求流量的复制对下游压力的增长,并行请求的成本是比较高的。对于一个服务来说,想快速的优化耗时抖动,对冲请求是个不错的选择,改造成本低,优化效果明显。在google内部的实践中,是以95分位作为重发请求的时间点,由于每个服务的情况可能都不一样,可能有的服务是93,94分位。那么对于这个重发请求的时间点,我们要怎么考虑呢,能不能建立一个比较普适的结论呢。下面是笔者的一些思考。
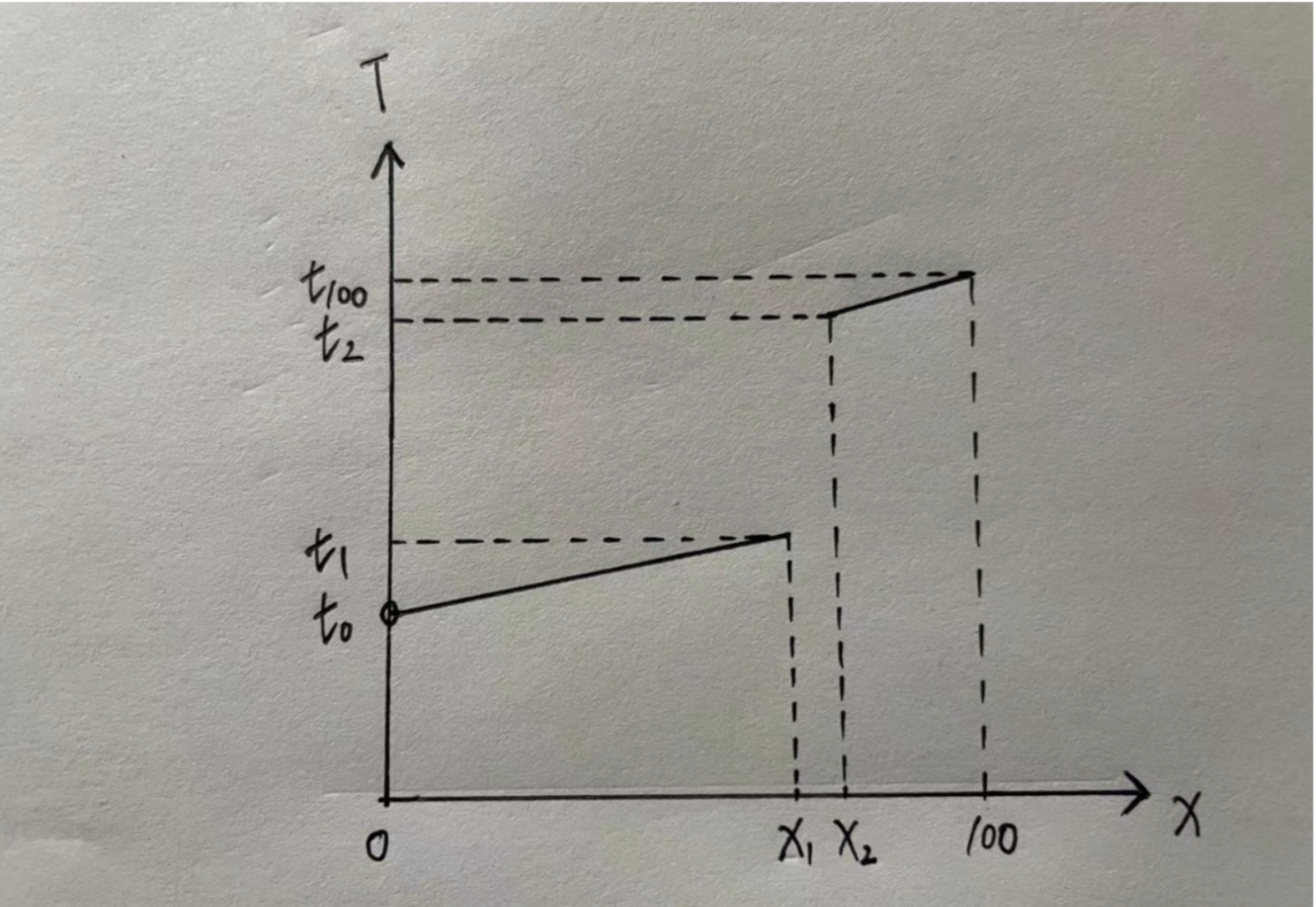
我们以服务的百分位耗时建立数学模型,横轴为百分位,纵轴为对应耗时。由这个模型我们可以得到一些结论,这是一个单调递增的模型(这个结论很容易得到,百分位耗时可以理解为将100个请求的耗时从小到大排序,第99个请求的耗时就是99分位耗时)。其次,这个模型的定义域是(0, 100].
3.并行请求。
正如不要把鸡蛋放一个篮子里,如果同时向下游服务的两个或更多实例发送相同的请求,当其中一个请求已经返回了,就通知另外一个请求停止执行,以减少资源的投入。并行请求里面的数学逻辑是这样的,如果服务A内每个实例有1%的流量会出现耗时抖动,那么如果同时发送请求到两个实例上,取最先返回的结果,耗时的不抖动的概率是1- 1% * 1% = 99.99%,同时发的请求越多,优化越明显,这里涉及到一个成本与收益之间的平衡抉择问题。关于并行请求笔者有以下几个方案的考虑:
-
请求之间互相通知的实现。这个可以在服务调用框架上实现,让一个请求同时请求到下游的不同实例。在云原生时代,服务网格Service Mesh和SideCar可以劫持容器的网络行为,在这上面实现也是可以的。
-
并行发送请求对分布式链路追踪的影响。为了方便我们对服务链路进行跟踪,会有分布式的链路追踪进行日志的记录与分析。如果我们并行发送请求,那么在链路追踪中将会出现两份一样的下游服务调用链路,这会让我们难以分析问题。
-
两个并行请求结果可能不一样。举个例子,比如两个并行请求调用机器学习模块产出不一样的结果,这是完全有可能的,一些依赖机器学习做决策的请求,可能会由于两个请求的模型结果不一样而导致最终的结果不一致。
模型假设
-
服务的请求质量相近。意思是每个请求的正常执行时间应该是差不多的。如果一个请求的耗时很长,是因为他本来执行时间就应该这么长,这样的情况是没有优化必要的。
-
假设耗时抖动是一定存在的。因为我们讨论的就是这个问题,不存在就话这片文章就该到此结束了(笑。hhh)。
-
假设请求连路上没台机器都会以一定的概率出现抖动现象。那么对于耗时的模型来说,就是存在X1与X2,满足X2 = X1 + 1或者X2=X1 + n,使得t2 >> t1.
-
为了方便讨论,将(0, X1]和[X2, 100]两段函数拟合为一次函数。y=k1x+b1 x∈(0, x1], y=k2x+b2 x∈[x2,100]
-
在请求的耗时已经达到了t1时,重发一个对冲请求。
-
重发的请求对服务的整体状况不会有影响。也就是说,重发的请求耗时分布也会等概率的分布在上图的[0,100]去区间中。
模型结论
-
服务请求耗时的尾部也就是[x2, 100]这一段耗时将会变成:y=min{t1+ x1/100*(k1Z1+b1), k2Z2+b2},其中Z1∈(0,x1], Z2∈[x2, 100]
-
t1+ x1/100*(k1Z1+b1) 的值域为[t1+t0, t1 + t1],因为x1/100趋近于1,k1Z1+b1值域为[t0,t1],那么这时候尾部耗时就取决于[t1+t0, 2 * t1]与[t2, t100]这两段的大小对比。
-
那么这时候这个模型就可以进行收益分析,如果如果t1+t0 > t100,我们可以认为没有优化,因为当[t1 + t0, 2 * t1]这段的最小值大于[t2, t100]的最大值的时候,说明前者的分布完全在后者的上面,没有优化可言。反之,如果2 * t1 < t2,那么就是完全有优化的。如果两段有重叠,那么优化部分就是重叠部分。
实操考量
-
对冲请求比较适合读的场景。如果是写相关的操作,很难取消两个写操作的影响。
-
x1的选取。如果x1太小,比如50,那么意味着要重新发送50%的流量,下游的压力变为了原来的1.5倍,这样成本太高了。
-
在实现的时候t1的值如何获取。关于t1,可以使用高峰期的值,服务高峰期的流量远大于平峰期,在平峰期的时候重发的部分流量对下游影响并不大。其次如果想要实时的变化这个重发请求的时机,可以把值写在配置平台上。如果想要弄成自适应决策发送对冲请求时机的形式,可以建立实时的反馈机制,统计一个时间窗口的耗时分布,决策出下一个时间窗口的重发对冲请求时机。
集群维度耗时抖动优化
-
微分区。服务中的多个实例可以组成一个小型的分区,当分区中一个实例出现耗时抖动,可以往该实例中其他实例转移流量。比如实例A所在分区中有20个实例,当A出现耗时抖动,将流量转移到其他19个实例上。对于其他19个实例来说增加了大概5%的流量负载,却有效保证了分区内的耗时维持在一个较低的水位。
-
分区状态探测与预测。在上面优化的前提下,可以探测每个分区的服务耗时情况以及预测出耗时抖动,及时的做流量的转移。
-
实例监测与流量摘除。如果一个服务实力状态异常,可以把实例的流量摘掉,分摊到分区中别的实例上面去,这样做可以提高集群的整体健康状态。
对于大型信息检索系统的优化
对于大型的信息检索系统来说,衡量服务质量的标准是,足够快的返回较好的结果,而不是比较慢的返回最好的结果。基于这个原则,google内部有以下两种优化措施。
-
快速返回足够好的结果。在服务接口内部可以分为不同子模块的计算,给不同的子模块限定执行的时间,如果接口整体耗时已接近上限,可以舍弃一些模块的计算,比如google搜索服务,当信息检索和排序计算好了,耗时已接近上限,那么这个时候可以放弃广告推荐的相关计算,从而达到足够好且足够快的返回。
-
请求探测。在发送大规模的请求之前可以发送少部分请求探测服务的状态。如果探测的请求耗时很高,可以判定服务具有一定的危险性,可以及时做出排查。
总结
耗时抖动一定会存在且与我们的服务长期共存,我们能做的就是尽量的优化一些不可控的因素带来的影响。以上是google的长尾耗时相关的优化经验分享。从业务组件级别,请求级别,大规模集群级别,以及google的信息检索服务,各方各面讲述了他们的耗时优化相关经验与措施,还有我个人的一些思考与感悟。
个人推广
笔者之前在lsm-tree和leveldb上面有一定的开源贡献,后续会持续更新相关的东西给大家。下面是笔者新开的公众号。希望大家多多关注,也希望笔者能持续给大家带来高质量的分享。谢谢大家!

标签:Scale,服务,请求,实例,t1,耗时,Tail,详解,分位 来源: https://www.cnblogs.com/elliotchenzichang/p/16283118.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。