标签:map 二面 分块 携程 队列 面经 reduce master 管理器
携程面试
一面(20220513):
- 自我介绍
- 项目介绍
- 项目遇到的困难
- yarn机制
- 三个主要的组件:
- ResourceManager:整个系统只有一个,用于负责资源的调度
- 包含两个主要组件:
- 定时调用器(Scheduler):给任务分配资源
- 应用管理器(ApplicationManager):监控、跟踪程序状态
- 包含两个主要组件:
- ApplicationMaster
- NodeManager:负责容器的资源管理
- ResourceManager:整个系统只有一个,用于负责资源的调度
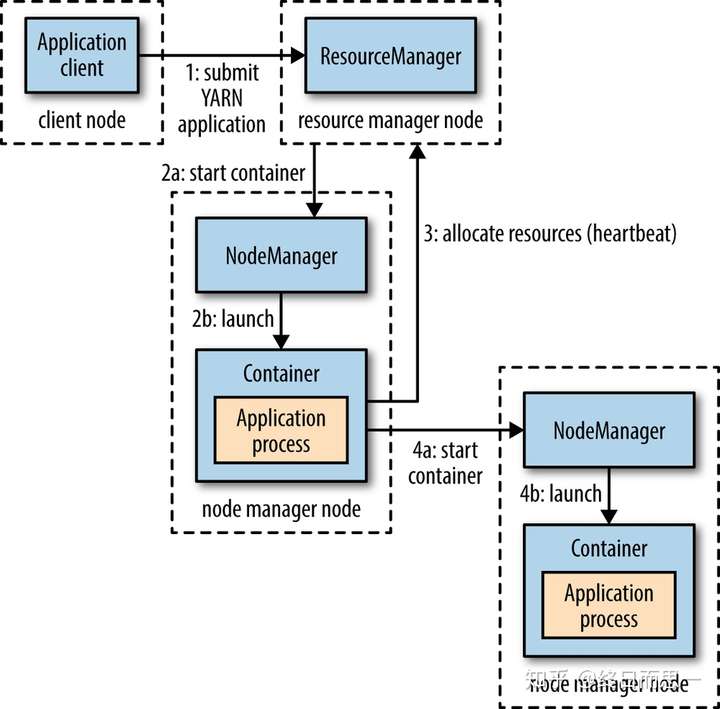
- 用户提交资源申请(YARN程序)--->资源管理器找到一个节点管理器,启动容器,运行application master进程--->资源管理器分配资源(如果能在本地完成任务,则直接完成然后返回;如果不能完成,则需要向资源管理器请求更多的节点管理器然后运行容器执行任务)--->申请到新的节点管理器,启动容器运行应用程序

- 任务调度器问题:
- FIFO:没啥说的,先进先出,先来的执行完了后面才能执行
- 容量调度器(大小任务分开):
- 分配多个队列,每个队列固定容量(需要配置),内部使用FIFO调度,队列执行并行执行
- 公平调度器(可抢占资源——需要设置条件,比如何时能抢占,或者抢占等待时间):
- 分配多个队列,每个队列可以指定资源大小,不指定则均匀分配,队列内则是均匀分配资源(共享内存)
- 可以配置队列运行程序数量,(超出数量的则会等待前面任务完成再申请资源)
- 三个主要的组件:
- 项目数据库设计
- 关于评论数据库优化的问题
- mysql递归问题
- mysql8有一个with recursive语法可以实现递归
- mysql8以下可以使用子查询或者创建函数
- k8s
- 设计模式
二面(20220517)
- 自我介绍(自己提到的在看mapreduce的论文)
- hadoop底层原理
- 答的最底层是hdfs,然后上面有yarn管理资源分配调度在上面是mapreduce和hbase之类的应用层
- mapreduce流程
- 照着论文的流程答了一遍
- 先是数据分块
- 然后分配master结点
- 将分块传送给map函数,map函数进行处理
- 这里打断提了个问题,问hadoop默认分块大小,我答的64MB,因该是128MB,64是GFS的分块大小(论文里),hadoop系统上显示的块大小为128MB
- 然后接着这个问题问了一个分块大小和什么有关,答的和节点数有关,map任务数量应该远大于所有工作结点数量,这样才能保证效率
- map函数全部处理完会写入本地文件,然后给master发信号,master接到信号后给reduce发信号通知reduce来读取数据进行第二步reduce操作
- reduce将map结果文件全部读取到本地,在本地进行排序,然后输送给reduce函数
- reduce处理完毕之后追加结果到结果文件
- reduce结束,给master发信号,等所有任务结束,master返回用户代码
- 照着论文的流程答了一遍
- 问爬虫项目细节
- 问用没用框架,如何实现的
- 大致说了一下流程,特别问了一下验证码如何处理的(答的手动处理,因为没有时间,没有使用人工智能算法)
- 是否还知道其他大数据生态
- 说了离线相关的,实时的只知道名字,不知道细节
- 问了下hive的原理和作用,以及什么时候使用
- 未来规划
- 学习方式
- 是否懂spark flink
等结果出来在更新
这段时间要去补个项目了,不然没相关项目只知道基础面试官都没啥问的
标签:map,二面,分块,携程,队列,面经,reduce,master,管理器 来源: https://www.cnblogs.com/lavender-pansy/p/16282004.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。