标签:BERT 模型 HASOC 2021 攻击性 文本 仇恨
©原创作者 | 周鹏
体验与资源链接:
https://github.com/sherzod-hakimov/HASOC-2021---Hate-Speech-Detection
论文:
Combining Textual Features for the Detection of Hateful and Offensive Language
地址:
https://arxiv.org/abs/2112.04803
摘要
自从网络攻击成为一种攻击性行为以来,许多网络用户在日常社交活动中都会受到攻击性语言的攻击。
在这篇文章中,我们分析了如何结合不同的文本特征来检测Twitter上的仇恨或攻击性帖子。
我们提供了详细的实验评估,以了解神经网络架构中每个构建块的影响。所提出的架构是在English Subtask 1A上进行评估的:从TIB-VA团队下的HASOC-2021所发布的数据集中识别仇恨、攻击性和亵渎性内容。
我们比较了上下文词嵌入的不同变体,并结合了字符级嵌入和收集的仇恨词编码。
01 简介
一般来说,仇恨言论被定义为一种基于特定特征,如宗教、种族、出身、性取向、性别、外表、残疾或疾病、用于表达对目标群体或个人的仇恨的语言。
在本文中,我们分析了结合多种文本特征来检测在推特文本中表达的仇恨性、冒犯性或亵渎性语言的影响。
我们评估了在英语和印度雅利安语(HASOC)挑战数据集的仇恨言语和攻击性内容识别上使用我们的方法(https://hasocfire.github.io)。
我们将解决方案提交到English Subtask 1A上:从HASOC- 2021挑战系列的帖子中识别仇恨、冒犯和亵渎内容。这项任务包括对一条给定的推文文本进行分类,无论其内容是否是可恨的、冒犯性的还是亵渎性的语言。
我们提出了一种基于神经网络体系结构的多种文本特征的组合,并评估了不同的配置。我们的实验评估是对所有三个数据集进行的:HASOC-2019,HASOC-2020,HASOC-2021。
02 模型体系结构
模型架构是建立在三个文本特性之上的,这些特性结合在一起来预测一个给定的文本是否包含仇恨的、冒犯性的或亵渎的语言。
神经网络架构如图1所示。输入标记被输入到 BERT、字符和仇恨词编码器中,以提取与特征相关的向量表示。
一旦每个特征表示被提取出来,输出就被输入到单独的组件中,以获得一维向量表示。这些向量被连接并输入到三个不同的块中,以获得二进制类的概率。每个块由一个线性层、批标准化和一个ReLU激活函数组成。
下面描述的源代码和资源将与社区公开共享(
https//github.com/sherzod-hakimov/HASOC-2021---Hate-Speech-Detection)。
接下来,我们将详细描述文本编码器。
BERT编码器:我们使用一个预先训练过的BERT模型来获得每个输入标记的上下文768维单词向量。
字符编码器:每个输入标记都根据英语字符的单热编码转换为向量表示。我们只使用字母(a-z)来获得一个字符级别的向量序列。
仇恨词汇编码器:我们通过结合Gomez等人提供的字典收集了一个仇恨词汇列表。与额外的在线词典(https:
//www.noswearing.com/dictionary&https://hatebase.org/)。
我们手动过滤掉了不表达仇恨概念的术语,并获得了1493个仇恨术语的列表。该列表包含了各种具有不同词汇变化的术语,以增加在推文中检测这些术语的覆盖率 ,例如,bitc*、border jumper、nig**或chin*。该编码器输出一个1493维向量,这是一个输入中的仇恨术语的多热编码。
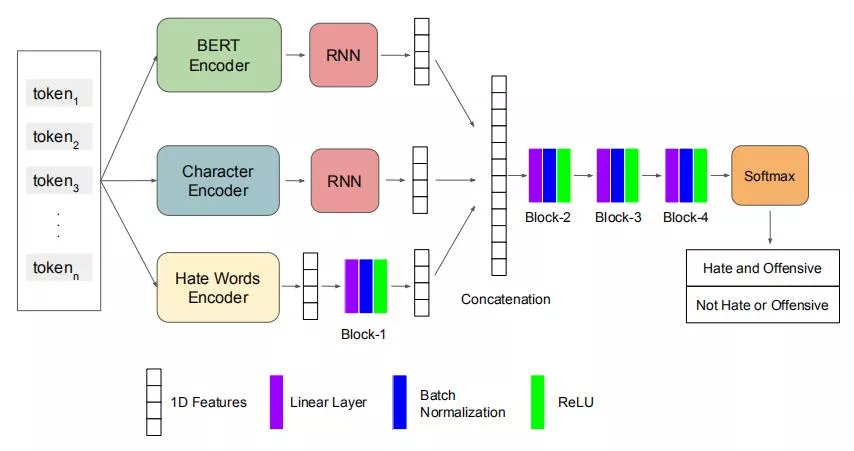
图1 模型架构结合了字符、仇恨词和输出给定文本是否存在仇恨和冒犯性概率的BERT嵌入
03 实验设置、挑战数据集以及模型架构的评估
3.1数据集
我们的模型架构是为HASOC-2021 English Subtask 1A构建的:从中识别仇恨、冒犯性和亵渎性的内容。
在表1中,我们提供了HASOC-2019、HASOC-2020和HASOC-2021版本的数据点数。这个数据集包括tweet文本作为输入数据和两个目标标签:仇恨和攻击性(HOF)和不仇恨和不攻击性(NOT)。2019年和2021年版本的训练样本数量在这两个类型中的分布并不相同。
为了克服类不平衡的问题,我们将过采样的方法应用于训练分割。我们随机为少数类选择了一定数量的数据点(HOF for 2019, NOT for 2021),并复制它们以与大多数类的数据点数量相等。

表1 为所有版本的HASOC数据集English Subtask 1A的训练和测试分割的数据点的分布。
HOF: Hate and Offensive(仇恨和攻击性), NOT: Not Hate or Offensive(非仇恨和攻击性)
3.2 数据预处理
来自推特上的工作文本有几个挑战。在许多情况下,标记以各种不同的形式来录入,以节省空间 ,大写,与数字混合等。
我们应用以下文本预处理步骤来规范化tweet文本:1)删除话题标 签、url、用户标签,转发标签使用Ekphrasis,2)删除标点,3)将标记转换为小写。
3.3 模型参数
我们将提供关于图1所示的模型体系结构中构建块的所有参数的详细信息。
BERT编码器:我们实验了两种不同版本的BERT模型。第一个变体是bert-base,这是Devlin等人提供的默认模型。第二种变体是由Caselli等人提供的HateBERT。是一个bert基础模型,对从Reddit中提取的仇恨评论语料库进行了预训练。这两个变量为给定的输入标记输出768维向量序列。
递归神经网络(RNN)层:我们对不同类型的RNN层进行了实验:长短期记忆(LSTM)、门控递归单元(GRU)和双向门控递归单元(Bi-GRU)。我们还实验了不同的层尺寸,即 100、200、300。
线性层:模型架构包括四个块,它们由三个连续的层组成:线性层、批处理规范化和激活函数(ReLU)。1、2、3、4块的线性层尺寸分别为512、512、256、128。训练过程:模型架构的每个配置都使用Adam优化器进行训练,学习率为0.001,批处理大小为64,最多可进行20次迭代。我们使用90:10的训练和验证分割来找到最优的超参数。
实现:模型架构是用Python使用Tensorflow Keras library实现的。源代码公开享(
https://github.com/sherzod-hakimov/HASOC-2021---Hate-Speech-Detection)。
3.4 结果
我们测试了上述的对所有三个数据集的不同模型配置。结果见表2。数据集English Subtask 1A的官方评价指标是宏f1分数( Macro F1-score)。
此外,我们还包括了准确性和加权f1分数,因为在数据集的测试分割中,每个类的数据点的数量不平衡的(见表1)。我们包含了具有相应特性的性能最好的模型。
基于初始实验,与其他模型配置相比,选择层大小为100的门控循环单元(GRU)在个数据集上产生了最高的性能。因此,下表中列出的所有模型配置都使用大小为100的GRU 层。
结果表明,bert基嵌入比HateBERT嵌入具有更大的影响。
另一个重要的观察结果是,基于仇恨术语(HW)的多热编码的特征对所有数据集都获得了较高的准确性和加权f1分数。具体来说,包含该特性的每个模型配置都会在HASOC-2020数据集上产生最佳的结果。
我们的方法结合了bert基础、字符嵌入和仇恨术语的多热编码,在HASOC-2021数据集的English Subtask 1A上获得了宏f1分数0.77。
我们提交了与TIB-VA团队相同的模型来参加官方的挑战。我们的模型排名在第33位,Macro-f1得分为0.76。
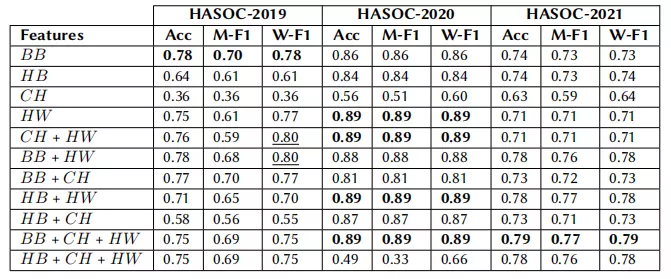
表2 对三个数据集的English Subtask 1A上的各种模型配置的评价结果。
评估指标包括准确性(Acc)、MacroF1 分数(M-F1)和加权F1分数(W-F1)。每个数据集的最佳性能模型配置都以粗体突出显示。BB:从 预先训练的BERT-base模型中提取的单词嵌入,HB:从预先训练的HateBERT模型中提取的单词嵌入,CH:字符水平嵌入,HW:仇恨单词的多热编码。
我们在图2中给出了具有不同的BERT模型变量的两种模型的混淆矩阵:BERT-base(BB)和 HateBERT(HB)。
这两个模型都使用字符级嵌入(CH)和多热编码的仇恨词(HW)进行训练。
我们可以观察到,使用bert-base嵌入的模型(图2a)做出了更正确的预测(614vs。与其他模型变体相比,在检测仇恨内容(HOF)方面(图2b)。
类似的模式也存在于目标类为NOT的情况下,并且该模型预测了HOF,其中具有BB特性的模型所犯的错误更少(151vs.188)比其他模型更大。
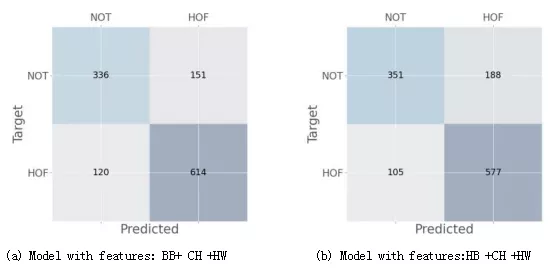
图2:在HASOC2021-English Subtask 1A上评估的两个模型的混淆矩阵
04 总结
在本文中,我们分析了结合多种文本特征来检测仇恨、冒犯和亵渎语言的模型架构。
我们的实验结果表明,简单地使用收集到的1493个仇恨术语的多热编码可以获得显著的性能。 BERT嵌入、字符嵌入和基于仇恨术语的特征的组合在English Subtask 1A、HASOC2021数据集上取得了最好的性能。
评估的另一个观察结果是,相比于默认的预训练模型变体(bere-base),文本上训练的BERT模型的变体并没有改进结果。
阅读原文链接:https://hasocfire.github.io
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
标签:BERT,模型,HASOC,2021,攻击性,文本,仇恨 来源: https://www.cnblogs.com/NLPlunwenjiedu/p/15860247.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。