标签:bagging LightGBM 综述 lgb 模型 拟合 model

根据以往的经验梯度提升树(gradient boosted tree)可谓横扫Kaggle,不使用GBT感觉都没法再Kaggle混了。决策树相对深度学习来说可谓优点多多:好理解,易解释,对非平衡数据友好,训练起来快等等。在本文中我们主要来了解下LightGBM这个框架并用Kaggle的实战数据来操练下。数据集在这:credit card fraud detection.
LightGBM
LightGBM 是一个用于梯度提升机的开源框架. LightGBM 不仅可以训练 Gradient Boosted Decision Tree (GBDT), 它同样支持 random forests, Dropouts meet Multiple Additive Regression Trees (DART), 和 Gradient Based One-Side Sampling (Goss).
这个框架轻便快捷,设计初衷为用于分布式训练。它支持大规模数据并可再GPU上训练。在很多情况下LightGBM比XGBoost更准更快,当然这个没那么绝对,依情况而定,不能绝对说谁就比谁要好。
Gradient Boosting
当我们提到集成学习时,肯定首先映入脑海的是bagging(装袋法)和boosting(提升法). bagging法包含许多独立模型的训练,最终通过某种形式的整合(平均,投票等)给出预测。装袋集成法的杰出代表是Random Forest.
相反,Boosting通过有序地训练模型,其中每个模型从先前模型的误差中学习。从弱模型开始,迭代地训练模型,每个模型添加到先前模型的预测以产生强大的总体预测。
在梯度提升决策树中,通过在相对于先前模型的叶节点的损失函数的误差残差计算的平均梯度的方向上应用梯度下降来找到序列模型。
关于梯度提升的 excellent explanation 可以看过来。 下面简要摘抄介绍:
Considering decision trees, we proceed as follows. We start with an initial fit, F0, of our data: a constant value that minimizes our loss function L0:

in the case of optimizing the mean square error, we can take the mean of the target values:

With our initial guess of F0, we can now calculate the gradient, or pseudo residuals, of L with respect to F0:

We now fit a decision tree h1(x), to the residuals. Using a regression tree, this will yield the average gradient for each of the leaf nodes.
Now we can apply gradient descent to minimize the loss for each leaf by stepping in the direction of the average gradient for the leaf nodes as contained in our decision tree h1(x). The step size is determined by a multiplier γ1 which can be optimized by performing a line search. The step size is further shrinked using a learning rate λ1, thus yielding a new boosted fit of the data:
![]()
算法
总而言之,算法流程如下. M:一系列boosting轮数, L:可微损失函数

需要注意的是上面的说明中它忽略了在损失函数中引入正则化项。 XGBoost文档中在综述梯度提升时,在推导目标函数中着重阐明了正则化项.
LightGBM的API
LightGBM需要我们将数据置于LightGBM的Dataset对象中:
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_val = lgb.Dataset(X_val, y_val, reference=lgb_train, free_raw_data=False)
参数free_raw_data控制在构造内部数据集之后是否释放输入数据。
LightGBM的核心参数定义:
core_params = {
'boosting_type': 'gbdt', # rf, dart, goss
'objective': 'binary', # regression, multiclass, binary
'learning_rate': 0.05,
'num_leaves': 31,
'nthread': 4,
'metric': 'auc' # binary_logloss, mse, mae
}
接着我们就能调用training API来训练模型了,依据需要指定boosting轮数和提前停止轮数:
evals_result = {}
gbm = lgb.train(core_params, # parameter dict to use
training_set,
init_model=init_gbm, # enables continuous training.
num_boost_round=boost_rounds, # number of boosting rounds.
early_stopping_rounds=early_stopping_rounds,
valid_sets=validation_set,
evals_result=evals_result, # stores validation results.
verbose_eval=False) # print evaluations during training.
当我们的模型评估指标在验证数据不再有改善时,训练将会提前结束。
更详细的Python API看这里: here.
绘图
LightGBM有一个内置的绘图API,可用于快速绘制验证结果和树相关图。
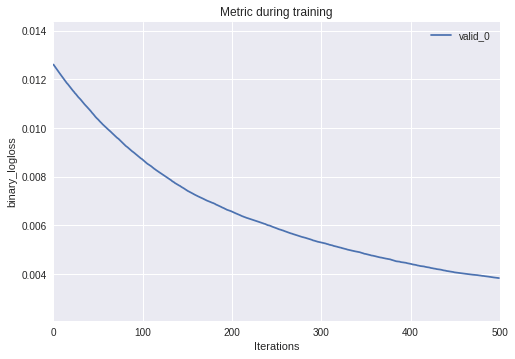
给出来自于训练得到eval_result字典 ,我们能很容易的画出验证指标随迭代次数的变化:
_ = lgb.plot_metric(evals)
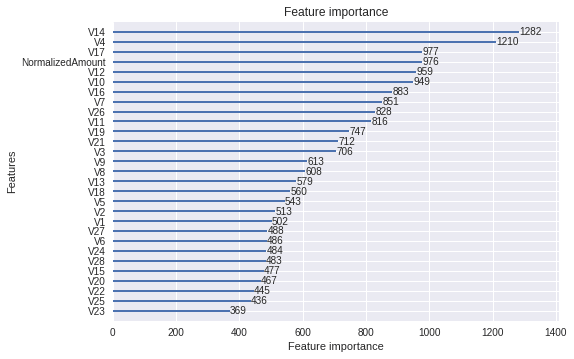
还有个更实用的用于树的可解释性的特点是给出了特征的相对重要性.
_ = lgb.plot_importance(model)
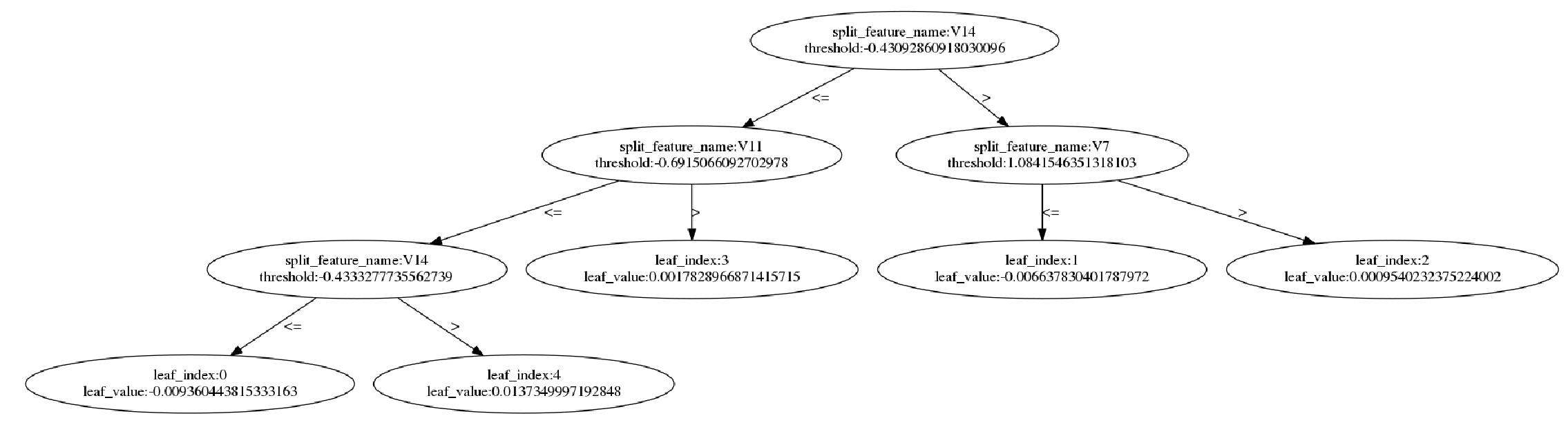
也可以查看单独的每棵树:
_ = lgb.plot_tree(model, figsize=(20, 20))
保存模型
将模型保存为文本文件或者JSON等其他格式:
gbm.save_model('cc_fraud_model.txt')
loaded_model = lgb.Booster(model_file='cc_fraud_model.txt')
# Output to JSON
model_json = gbm.dump_model()
LightGBM的参数
下面对一些用于训练GBDT模型的高级参数予以简洁的说明,解释一下它们对算法的影响。
advanced_params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.01,
'num_leaves': 41, # more increases accuracy, but may lead to overfitting.
'max_depth': 5, # shallower trees reduce overfitting.
'min_split_gain': 0, # minimal loss gain to perform a split.
'min_child_samples': 21, # specifies the minimum samples per leaf node.
'min_child_weight': 5, # minimal sum hessian in one leaf.
'lambda_l1': 0.5, # L1 regularization.
'lambda_l2': 0.5, # L2 regularization.
# LightGBM can subsample the data for training (improves speed):
'feature_fraction': 0.5, # randomly select a fraction of the features.
'bagging_fraction': 0.5, # randomly bag or subsample training data.
'bagging_freq': 0, # perform bagging every Kth iteration, disabled if 0.
'scale_pos_weight': 99, # add a weight to the positive class examples.
# this can account for highly skewed data.
'subsample_for_bin': 200000, # sample size to determine histogram bins.
'max_bin': 1000, # maximum number of bins to bucket feature values in.
'nthread': 4, # best set to number of actual cores.
}
树参数
LightGBM和XGBoost都是基于leaf-wise来构建树.
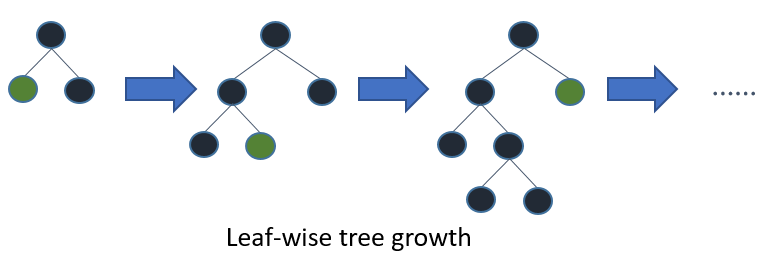
以leaf-wise方式构建树会更快收敛,但如果参数未调优则可能导致过拟合。控制树生成的重要参数有:
num_leaves: 叶子节点数. 叶节点数目多能更精确,叶更容易过拟合.min_child_samples: 用于一个叶子节点的最小样本数(数据集). 每个叶子的较大样本量将减少过拟合(但可能导致欠拟合).max_depth: 树深度. 浅一点的树能较少过拟合.
非平衡数据调参
对于非平衡数据最简单粗暴的方式是给正例样本加上权重.
scale_pos_weight: 权重基于正例和负例样本的数量来计算,公式为:sample_pos_weight = number of negative samples / number of positive samples.
抑制过拟合调参
前面的参数说明也提到过这一点,以下参数可以用于控制过拟合:
max_bin: 特征值被填充的最大bin区间数。较小的max_bin减少过拟合.min_child_weight: 叶子的最小hessian和。与min_child_samples结合使用,较大的值可减少过拟合。bagging_fractionandbagging_freq: 训练数据的装袋(子采样)法。需要同时设置两个值以便使用bagging。频率控制bagging使用频率(迭代)的频率。较小的faction和freq可减少过拟合。feature_fraction:控制用于训练模型时的特征子采样(而不是像bagging那样对训练数据进行子采样)。较小值减少过拟合。lambda_l1andlambda_l2: 控制L1 和 L2 正则化.
提升精确度调参
通过调整以下参数可能提升精确度:
max_bin: 增大提升精确度.learning_rate: 小的学习率增加迭代次数可能提升精确度,牺牲了时间.num_leaves: 增加叶子数,提高精确度的同时带来了过拟合风险.
对XGBoost和LightGBM参数的详细概述,它们对算法各个方面的影响以及它们之间的相互关系可以参见这篇文章[here].
参考资料:
- LightGBM project: https://github.com/Microsoft/LightGBM
- LightGBM paper: https://www.microsoft.com/en-us/research/wp-content/uploads/2017/11/lightgbm.pdf
- Documentation: https://lightgbm.readthedocs.io/en/latest/index.html
- Parameters: https://lightgbm.readthedocs.io/en/latest/Parameters.html
- Parameter explorer: https://sites.google.com/view/lauraepp/parameters
- LightGBM overview:https://www.avanwyk.com/an-overview-of-lightgbm/
标签:bagging,LightGBM,综述,lgb,模型,拟合,model 来源: https://blog.csdn.net/liulunyang/article/details/87989315
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。