标签:提取 关键词 TFIDF IDF 词频 TF 文档 document first
系列文章
✓ 词向量
✗Adam,sgd
✗ 梯度消失和梯度爆炸
✗初始化的方法
✗ 过拟合&欠拟合
✗ 评价&损失函数的说明
✗ 深度学习模型及常用任务说明
✗ RNN的时间复杂度
✗ neo4j图数据库
分词、词向量
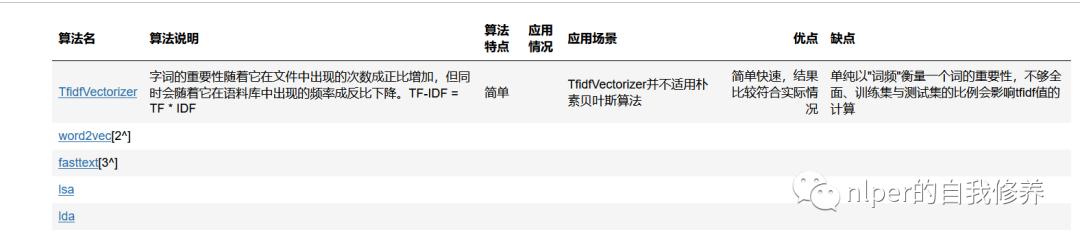
TfidfVectorizer
基本介绍
-
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
-
比如:为了获得一篇文档的关键词,我们可以如下进行
-
对给定文档,我们进行"词频"(Term Frequency,缩写为TF)
-
给每个词计算一个权重,这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
算法明细
-
基本步骤
-
1、计算词频。考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。 词频:TF = 文章中某词出现的频数 词频标准化:

-
2、计算逆文档频率。如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。 逆文档频率:
 其中,语料库(corpus),是用来模拟语言的使用环境。
其中,语料库(corpus),是用来模拟语言的使用环境。 -
3、计算TF-IDF。可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比 $TF-IDF = TF * IDF$
-
算法优缺点
-
优点:
-
TF-IDF算法的优点是简单快速,结果比较符合实际情况。
-
-
缺点
-
单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
-
这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。
-
对于文档中出现次数较少的重要人名、地名信息提取效果不佳
-
应用场景
-
应用场景简介
-
1)搜索引擎;
-
2)关键词提取;
-
3)文本相似性;
-
4)文本摘要
-
可执行实例
# python:3.8
# sklearn:0.23.1
# 1、CountVectorizer 的作用是将文本文档转换为计数的稀疏矩阵
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
# 查看每个单词的位置
print(vectorizer.get_feature_names())
#['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
# 查看结果
print(X.toarray())
# [[0 1 1 1 0 0 1 0 1]
# [0 2 0 1 0 1 1 0 1]
# [1 0 0 1 1 0 1 1 1]
# [0 1 1 1 0 0 1 0 1]]
# 2、TfidfTransformer:使用计算 tf-idf
from sklearn.feature_extraction.text import TfidfTransformer
transform = TfidfTransformer()
Y = transform.fit_transform(X)
print(Y.toarray()) # 输出tfidf的值
# [[0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]
# [0. 0.6876236 0. 0.28108867 0. 0.53864762 0.28108867 0. 0.28108867]
# [0.51184851 0. 0. 0.26710379 0.51184851 0. 0.26710379 0.51184851 0.26710379]
# [0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]]
# 3、TfidfVectorizer:TfidfVectorizer 相当于 CountVectorizer 和 TfidfTransformer 的结合使用
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer() #构建一个计算词频(TF)
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
# ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
print(X.shape)
# (4, 9)
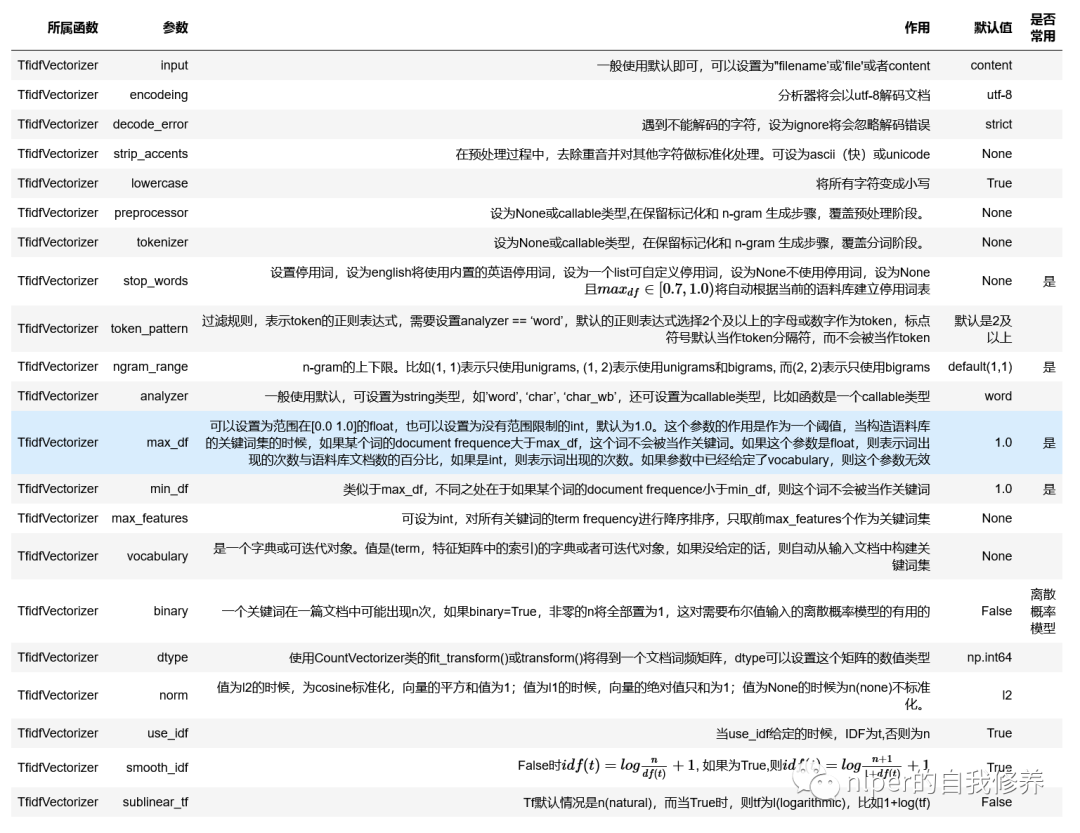
参数项说明
-
CountVectorizer

-
TfidfTransformer

-
从函数上来看,咱也可以发现有TfidfVectorizer=CountVectorizer + TfidfTransformer哈
-
TfidfVectorizer
标签:提取,关键词,TFIDF,IDF,词频,TF,文档,document,first 来源: https://www.cnblogs.com/nlper2wx/p/15200892.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。