标签:file2 shell 第二列 cat 转帖 print awk 第一列 分组
数据需求统计常用shell命令---AWK分组求和,分组统计次数
https://blog.51cto.com/6226001001/1659824
1、将时间转换为时间戳
select unix_timestamp('2009-10-26 10-06-07')
如果参数为空,则处理为当前时间
2、将时间戳转换为时间
select from_unixtime(1256540102)
有些应用生成的时间戳是比这个多出三位,是毫秒表示,如果要转换,需要先将最后三位去掉(标准的10位数字,如果是13位的话可以以除以1000的方式),否则返回NULL
1.将IP地址转化为数字
select inet_aton('210.30.0.103');
2.将数字转化为IP地址
select inet_ntoa(3525181543);
随机取用户
cat file1 | awk '{ print rand(),$1 }' |sort -k1 |awk '{ print $2 }' |head -4000
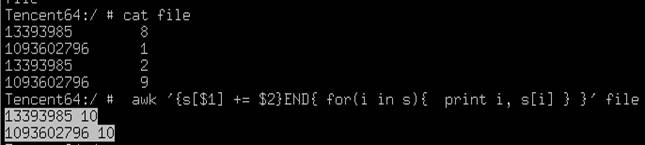
分组求和
awk '{s[$1] += $2}END{ for(i in s){ print i, s[i] } }' file1 > file2
以第一列 为变量名 第一列为变量,将相同第一列的第二列数据进行累加 打印出和
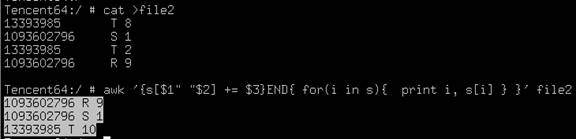
awk '{s[$1" "$2] += $3}END{ for(i in s){ print i, s[i] } }' file1 > file2
以第一列和第二列为变量名, 将相同第一列、第二列的第三列数据进行累加 打印出和
awk '{s[$1] += $2; a[$1] += $3 }END{ for(i in s){ print i,s[i],a[i] } }' haha.txt
如果第一列相同,则根据第一列来分组,分别打印第二列和第三列的和

匹配
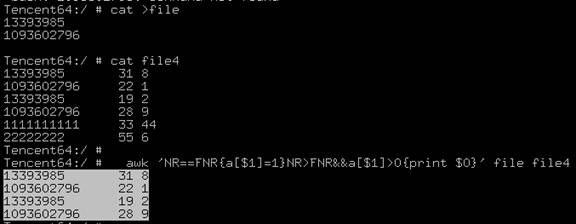
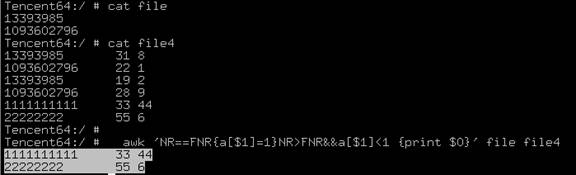
1、匹配交集项
awk 'NR==FNR{a[$1]=1}NR>FNR&&a[$1]>0{print $0}' file1(字段:QQ) file2(字段:QQ 点券值 ) > file3
如果file1、file2中,2个文件的第一列值相同,输出第2个文件的所有列
注意:数据量如果达到4Gb以上或者行数达到一亿级别,建议将file2进行split分割,否则就算是32G的内存的机器都会被吃掉;
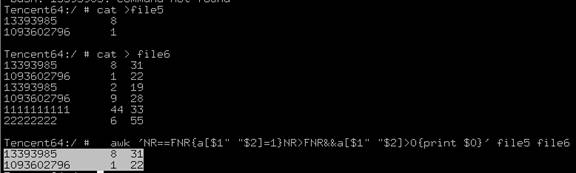
awk 'NR==FNR{a[$1" "$2]=1}NR>FNR&&a[$1" "$2]>0{print $0}' file1 file2> file3
如果file1、file2中,2个文件的第一列第二列值相同,输出第2个文件的所有列
2、匹配非交集项
awk 'NR==FNR{a[$1]=1}NR>FNR&&a[$1]<1 {print $0}' file1 file2 > file3
针对2个文件的第一列做比较,输出:在file2中去除file1中第一列出现过的行
第二种方法:
cat file1 file2|sort |uniq -d > jiaoji.txt
cat file2 jiaoji.txt |sort |uniq -u > file3
取最大值、最小值
1、针对(2列的文件)
awk '{max[$1]=max[$1]>$2?max[$1]:$2}END{for(i in max)print i,max[i]}' file
第一列不变,取第二列分组最大值
awk '{if(!min[$1])min[$1]=20121231235959;min[$1]=min[$1]<$2?min[$1]:$2}END{for(i in min)print i,min[i]}' file
第一列不变,取第二列分组最小值
2、针对单列的文件
awk 'BEGIN {max = 0} {if ($1>max) max=$1 fi} END {print "Max=", max}' file2
awk 'BEGIN {min = 1999999} {if ($1<min) min=$1 fi} END {print "Min=", min}' file2
求和、求平均值、求标准偏差
求和
cat data|awk '{sum+=$1} END {print "Sum = ", sum}'
求平均
cat data|awk '{sum+=$1} END {print "Average = ", sum/NR}'
求标准偏差
cat $FILE | awk -v ave=$ave '{sum+=($1-ave)^2}END{print sqrt(sum/(NR-1))}'
整合行和列
1、列换成行
如果第一列相同,将所有的第二列 第三列 都放到一行里面
awk '{qq[$1]=qq[$1](" "$2" "$3)}END{for(i in qq)print i,qq[i]}'

2、合并文件
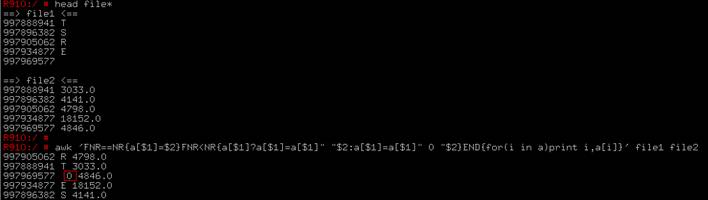
2个文件,每个2列,将他们按照第一列相同的数,来合并成一个三列的文件,同时,将每个文件中针对第一列对应第二列中没有的数补0
awk 'FNR==NR{a[$1]=$2}FNR<NR{a[$1]?a[$1]=a[$1]" "$2:a[$1]=a[$1]" 0 "$2}END{for(i in a)print i,a[i]}' file1 file2 > file3
注意点:文件2 一定要比文件1 的行数小
3、2个文件,每个3列,将他们按照第一列、第二列相同的数,来合并成一个4列的文件,同时,将每个文件中针对第一列、第二列对应第3列中没有的数补0
awk 'FNR==NR{a[$1" "$2]=$3}FNR<NR{a[$1" "$2]?a[$1" "$2]=a[$1" "$2]" "$3:a[$1" "$2]=a[$1" "$2]" 0 "$3}END{for(i in a)print i,a[i]}' file
4、将列换成行,遇到空行,另起下一行
awk 'begin {RS=""} {print $1,$2,$3} file1
5、某列数字范围筛选
cat canshu |while read a b
do
awk '{ if ($2>'"$a"' && $2<='"$b"' ) print $1}' result.txt > "$a"_"$b"_result.log
done
注意点:awk使用函数时,使用'"$a"'(先单引号,后双引号)
集合类

1、集合交
cat fileA fileB |sort |uniq –d > result.log
2、集合差
cat fileA fileB |sort |uniq -d > jiaoji.txt
cat fileA jiaoji.txt |sort |uniq -u > result.log
3、集合全集去重
cat fileA fileB |sort -u > result.log
3、集合全集不去重
cat fileA fileB |sort > result.log
标签:file2,shell,第二列,cat,转帖,print,awk,第一列,分组 来源: https://www.cnblogs.com/jinanxiaolaohu/p/12852233.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。