1、ORACLE归档日志介绍
归档日志暴增是oracle比较常见的问题,遇到归档日志暴增,我们该如何排查:- 归档日志暴增一般都是应用或者人为引起的
- 理解归档日志存储的是什么
- 如何排查归档日志暴增原因
- 如何优化归档日志暴增
1.1 归档日志是什么
归档日志(Archive Log)是非活动的重做日志(redo)备份. 通过使用归档日志,可以保留所有重做历史记录,当数据库处于ARCHIVELOG模式并进行日志切换式,后台进程ARCH会将重做日志的内容保存到归档日志中. 当数据库出现介质失败时,使用数据文件备份,归档日志和重做日志可以完全恢复数据库。
1.2 归档日志存储的是什么
所有重做的历史记录,包括DML语句、数据改变等
1.3 归档日志暴增的原因
一般是DML操作大量的数据,导致归档日志暴增
1.4 排查归档日志暴增的方法
1.SQL语句 2.AWR 3.挖掘归档日志
2、归档日志暴增排查实战
2.1 制造归档日志暴增
create table scott.object as select * from dba_objects; -- 执行10次 -- insert insert into scott.object select * from scott.object; select count(1) from scott.object; -- 49384448 -- update update SCOTT.object set owner='aa'; -- delete delete from SCOTT.object; truncate table SCOTT.object;
2.2 查看归档日志切换
SELECT
THREAD# id,SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) DAY
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'00',1,0)) H00
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'01',1,0)) H01
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'02',1,0)) H02
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'03',1,0)) H03
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'04',1,0)) H04
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'05',1,0)) H05
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'06',1,0)) H06
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'07',1,0)) H07
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'08',1,0)) H08
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'09',1,0)) H09
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'10',1,0)) H10
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'11',1,0)) H11
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'12',1,0)) H12
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'13',1,0)) H13
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'14',1,0)) H14
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'15',1,0)) H15
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'16',1,0)) H16
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'17',1,0)) H17
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'18',1,0)) H18
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'19',1,0)) H19
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'20',1,0)) H20
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'21',1,0)) H21
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'22',1,0)) H22
, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'23',1,0)) H23
FROM
v$log_history a
GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5),THREAD#
ORDER BY id,SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5)
/
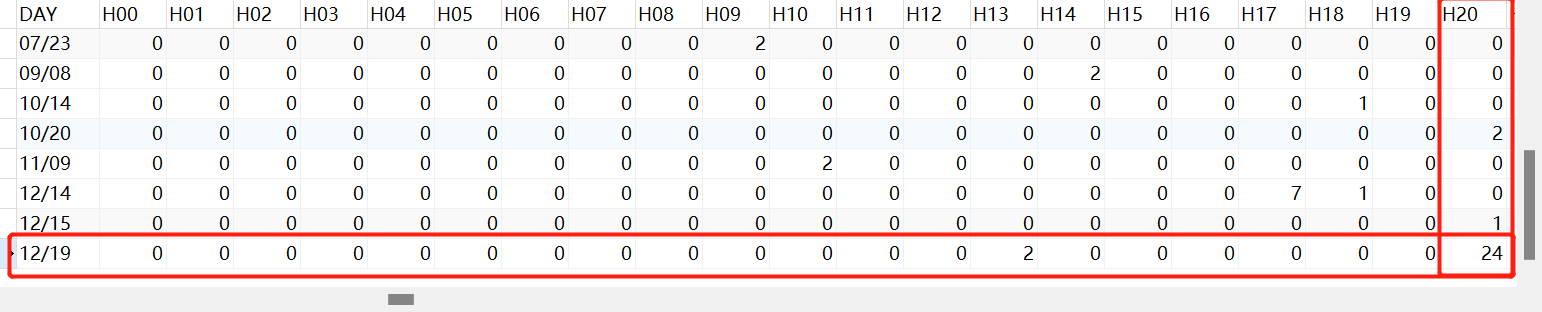
代表12月19号,H20(20-21时),共切换24个归档日志,如果每一个500M,那么总共约500M*24,对比其余时间,可以说该时间产生异常的归档日志,目标排查改时间段
2.3 SQL语句判断
with aa as
(SELECT IID,
USERNAME,
to_char(BEGIN_TIME,'mm/dd hh24:mi') begin_time,
SQL_ID,
decode(COMMAND_TYPE,3,'SELECT',2,'INSERT',6,'UPDATE',7,'DELETE',189,'MERGE INTO','OTH') "SQL_TYPE",
executions "EXEC_NUM",
rows_processed "Change_NUM"
FROM (SELECT s.INSTANCE_NUMBER IID,
PARSING_SCHEMA_NAME USERNAME,COMMAND_TYPE,
cast(BEGIN_INTERVAL_TIME as date) BEGIN_TIME,
s.SQL_ID,
executions_DELTA executions,
rows_processed_DELTA rows_processed,
(IOWAIT_DELTA) /
1000000 io_time,
100*ratio_to_report(rows_processed_DELTA) over(partition by s.INSTANCE_NUMBER, BEGIN_INTERVAL_TIME) RATIO,
sum(rows_processed_DELTA) over(partition by s.INSTANCE_NUMBER, BEGIN_INTERVAL_TIME) totetime,
elapsed_time_DELTA / 1000000 ETIME,
CPU_TIME_DELTA / 1000000 CPU_TIME,
(CLWAIT_DELTA+APWAIT_DELTA+CCWAIT_DELTA+PLSEXEC_TIME_DELTA+JAVEXEC_TIME_DELTA)/1000000 OTIME,
row_number() over(partition by s.INSTANCE_NUMBER,BEGIN_INTERVAL_TIME order by rows_processed_DELTA desc) TOP_D
FROM dba_hist_sqlstat s, dba_hist_snapshot sn,dba_hist_sqltext s2
where s.snap_id = sn.snap_id
and s.INSTANCE_NUMBER = sn.INSTANCE_NUMBER
and rows_processed_DELTA is not null
and s.sql_id = s2.sql_id and COMMAND_TYPE in (2,6,7,189)
and sn.BEGIN_INTERVAL_TIME > sysdate - nvl(180,1)/1440 and PARSING_SCHEMA_NAME<>'SYS')
WHERE TOP_D <= nvl(20,1)
)
select aa.*,s.sql_fulltext "FULL_SQL" from aa left join v$sql s on aa.sql_id=s.sql_id ORDER BY IID, BEGIN_TIME desc,"Change_NUM" desc
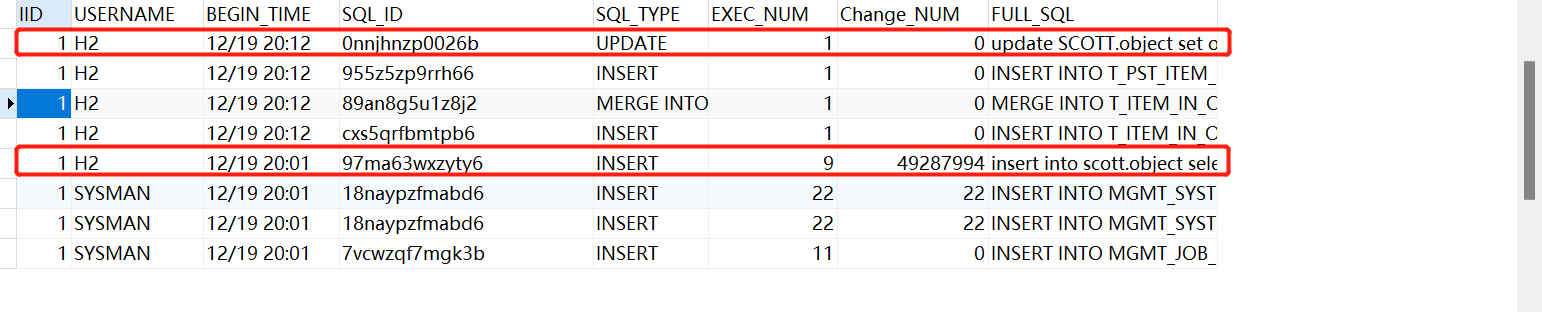
查看2小时的数据该变量,可以看出Change_NUM数据该变量和执行次数EXEC_NUM和SQL语句,update回滚了,所以没有该变量。 此时可以判断大量插入数据导致归档日志暴增,此时并不能判断update。此语句不一定有数据,只能做参考。
2.4 AWR
创建AWR报告创建AWR报告 @?/rdbms/admin/awrrpt.sql
SQL> @?/rdbms/admin/awrrpt.sql
Current Instance
~~~~~~~~~~~~~~~~
DB Id DB Name Inst Num Instance
----------- ------------ -------- ------------
3830097027 ..... 1 .....
Specify the Report Type
~~~~~~~~~~~~~~~~~~~~~~~
Would you like an HTML report, or a plain text report?
Enter 'html' for an HTML report, or 'text' for plain text
Defaults to 'html'
Enter value for report_type: html
Type Specified: html
Instances in this Workload Repository schema
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
DB Id Inst Num DB Name Instance Host
------------ -------- ------------ ------------ ------------
* 3830097027 1 ..... ..... dbserver01
Using 3830097027 for database Id
Using 1 for instance number
Specify the number of days of snapshots to choose from
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Entering the number of days (n) will result in the most recent
(n) days of snapshots being listed. Pressing <return> without
specifying a number lists all completed snapshots.
Enter value for num_days: 1
Listing the last day's Completed Snapshots
Snap
Instance DB Name Snap Id Snap Started Level
------------ ------------ --------- ------------------ -----
..... ..... 36 19 Dec 2021 14:03 1
37 19 Dec 2021 15:00 1
38 19 Dec 2021 16:00 1
39 19 Dec 2021 17:00 1
40 19 Dec 2021 18:00 1
41 19 Dec 2021 20:12 1
42 19 Dec 2021 21:03 1
Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Enter value for begin_snap: 41
Begin Snapshot Id specified: 41
Enter value for end_snap: 42
End Snapshot Id specified: 42
Specify the Report Name
~~~~~~~~~~~~~~~~~~~~~~~
The default report file name is awrrpt_1_41_42.html. To use this name,
press <return> to continue, otherwise enter an alternative.
Enter value for report_name: /tmp/awrrpt_1_41_42.html
解析AWR报告
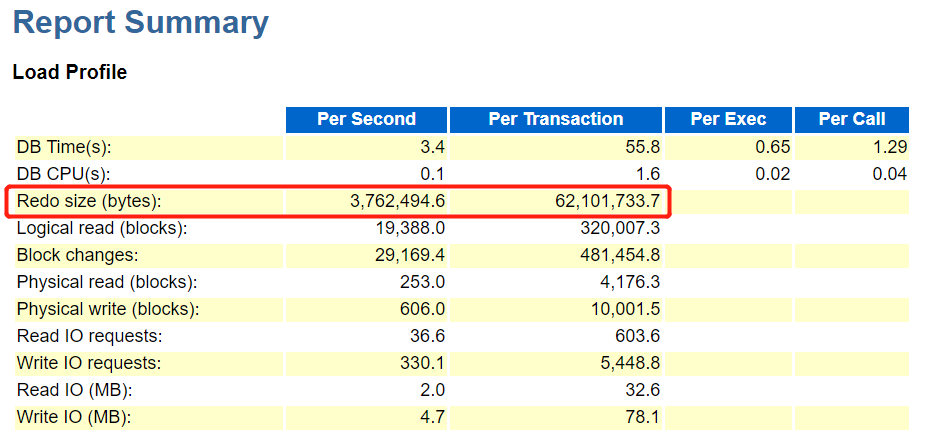
可以看出大量redo,该时间段总该变量3762494/1024/1024=3674,每秒约产生3.5M
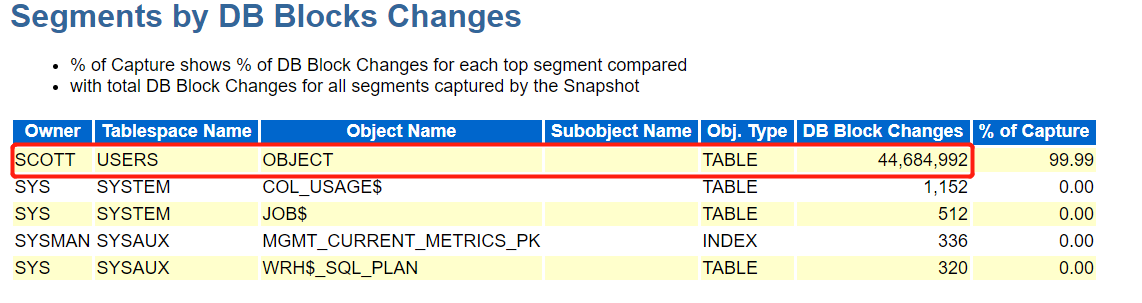
产生块最多的是scott用户,object对象,改变量是44684992,占比99%,说明是该对象产生的
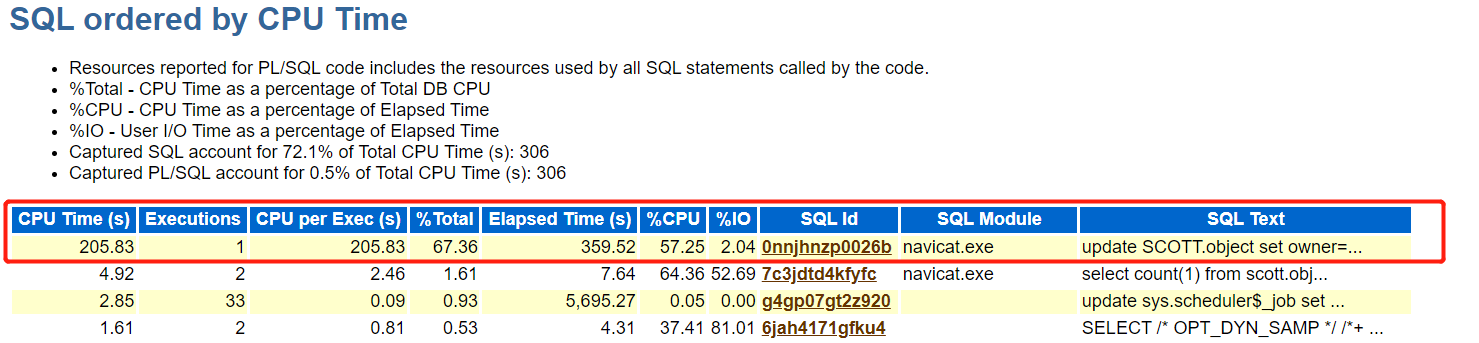
根据对象可以在AWR报告中查看是否有怀疑的SQL,发现update语句。
其实根据SQL语句和AWR报告可以排查出大部分归档日志暴增的问题,如果无法排查可以继续进行挖掘归档日志。
2.5 挖掘归档日志
-rw-r-----. 1 oracle oinstall 794697216 Dec 19 20:37 1_66_1077902149.dbf -rw-r-----. 1 oracle oinstall 794697216 Dec 19 20:37 1_67_1077902149.dbf -rw-r-----. 1 oracle oinstall 794697216 Dec 19 21:03 1_68_1077902149.dbf -rw-r-----. 1 oracle oinstall 733794304 Dec 19 21:03 1_69_1077902149.dbf -rw-r-----. 1 oracle oinstall 756531200 Dec 19 21:03 1_70_1077902149.dbf -rw-r-----. 1 oracle oinstall 761492480 Dec 19 21:14 1_71_1077902149.dbf -rw-r-----. 1 oracle oinstall 794697216 Dec 19 21:14 1_72_1077902149.dbf -rw-r-----. 1 oracle oinstall 265107968 Dec 19 21:14 1_73_1077902149.dbf
-- 最好sys或相关权限的用户,也可以使用toad工具 -- 第一次 @?/rdbms/admin/dbmslm.sql @?/rdbms/admin/dbmslmd.sql -- 开始执行 execute dbms_logmnr.add_logfile(logfilename=>'../../1_66_1077902149.dbf',options=>dbms_logmnr.new); execute dbms_logmnr.add_logfile(logfilename=>'../../1_67_1077902149.dbf',options=>dbms_logmnr.new); execute dbms_logmnr.add_logfile(logfilename=>'../../1_68_1077902149.dbf',options=>dbms_logmnr.new); execute dbms_logmnr.add_logfile(logfilename=>'../../1_69_1077902149.dbf',options=>dbms_logmnr.new); execute dbms_logmnr.add_logfile(logfilename=>'../../1_70_1077902149.dbf',options=>dbms_logmnr.new); execute dbms_logmnr.start_logmnr(options=>dbms_logmnr.dict_from_online_catalog); -- 依次类推小批量解析归档日志 -- 保存记录 create table scott.logmnr_contents as select * from v$logmnr_contents; -- 分批执行...循环执行上面记录 alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'; -- 最后释放pga execute dbms_logmnr.end_logmnr;
select sql_redo from scott.logmnr_contents where table_name='OBJECT'; select count(*) from scott.logmnr_contents where table_name='OBJECT';
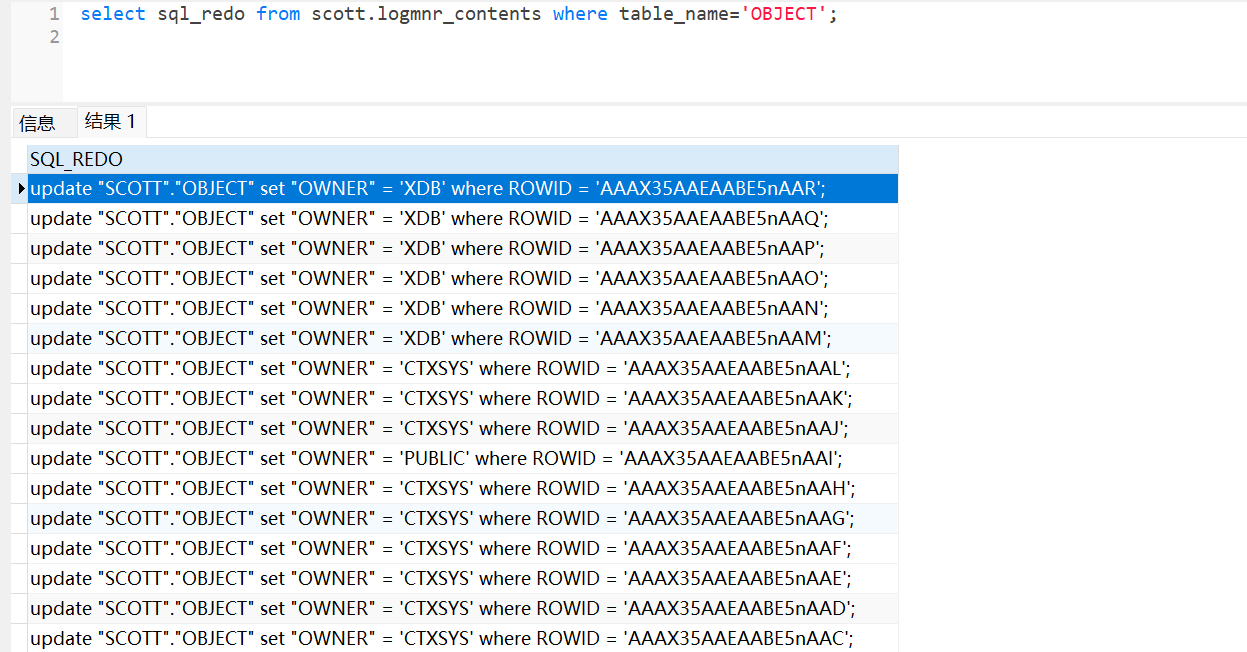
可以从归档日志中查看大量的update语句,此时基本可以排查出归档日志暴增原因
2.6 归档日志暴增优化
1.delete是否可以改造成truncate分区表(ps: truncate需谨慎,无法恢复相关数据) 2.dml可以适量使用临时表 3.避免大事务 4.避免大量for循环dml
标签:MM,归档,MI,SS,time,Oracle,日志 来源: https://www.cnblogs.com/lei-z/p/16467177.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。