决策树算法是一种通用的机器学习算法,既可以执行分类也可以执行回归任务,同时也是一种可以拟合复杂数据集的功能强大的算法;
一、可视化决策树模型
通过以下代码,我们使用iris数据集构建一个决策树模型,我们使用数据的后两个维度并设置决策树的最大深度为2,最后通过export出iris_tree.dot文件;
DecisionTreeClassifier初始化中的random_state可以确保每次执行结果的不变性;
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
iris = load_iris()
x = iris.data[:,2:]
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=12)
tree_clf.fit(x, y)
r = export_graphviz(tree_clf,
out_file='iris_tree.dot',
feature_names= iris.feature_names[2:],
class_names= iris.target_names,
rounded=True,
filled=True
)
然后通过命令行使用Graphviz软件包中的dot命令行工具将生成的iris_tree.dot文件转换为图片文件
dot -Tpng iris_tree.dot -o iris_tree1.png
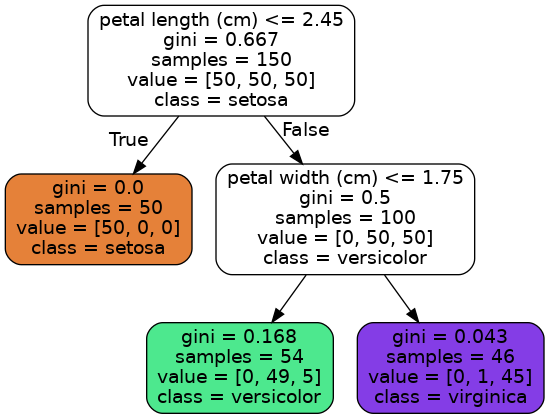
我们可以看到基于iris数据集生成的决策树结构如下图所示
二、决策树节点结构分析
通过生成的决策树结构图片,可以看到非叶子节点都会有一个判断条件,通过这个判断条件来决定转移到的子节点;
每个节点的samples记录了该节点训练使用的样本数量;例如根节点输入的训练样本有150个,最终符合判断条件的50个样本流入了左侧的叶子节点,不符合根节点判断条件的100个样本流入右侧的节点;
每个节点的value记录了该节点参与训练的样本中每个类别的数量,例如其实输入的150个样本中每个分类都是50个;
每个节点的class记录了该节点样本所属的类别;
每个节点的gini记录了该节点的基尼不纯度,其计算公式如下,其中pi,k代表第i个节点中每个分类所占的比例;
\[G_{i} = 1 - \sum_{k=1}^{n} p_{i,k}^{2} \]例如最后左下层的节点的基尼不纯度为
\[G = 1 -(0/54)^{2} - (49/54)^{2} - (5/54)^{2} = 0.168 \]处理使用基尼不纯度进行测量之外,也可以使用信息熵来度量节点样本的有序性,由于两者比较类似不进行详细介绍;
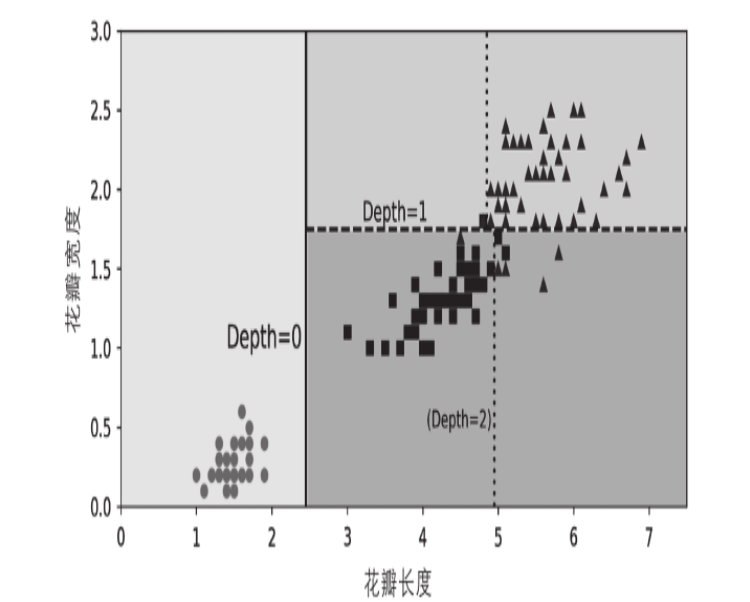
我们可以通过两个属性petal length、petal width的二维平面更加清晰看到决策树的决策边界;在petal length = 2.75地方,将整个二维平面分成左右两个区域,左侧区域已经是纯粹的class = setosa,右侧区域通过petal width = 1.75分成上下两部分;由于我们设置max_depth=2,则决策树到此为止;
三、决策树预测过程
通过生成的决策树的结构图,当我们接收到一朵新的iris花朵要进行预测的时候,只需要按照树的结构从上到下依次进行判断即可;对于我们先前生成的决策树,首先会从决策树的根节点开始,查看新记录的petal lenght是否小于等于2.45,如果小于则转移到左侧的节点,从而可以确认花朵的类型为setosa;如果petal length的长度大于2.45,则移动到右侧节点,接着判断petal width是否小于等于1.75,如果小于则转移到当前节点的左子节点,此时新记录的类型为versicolor,否则新记录的类型是virginica类型;
通过二中对决策树节点结构的分析,虽然每个叶子节点只对应某一个分类,但是最终的value却可能有不同的分类,即叶子节点不可能都是纯的;所以决策树除了直接输出输入样本对应的分类之外,也可以估算输入样本属于特定分类的概率;
我们输入样本[5,1],通过决策树的二维决策边界平面图,可以看到样本落右下角的区域,通过生成的决策树结构的图片可以看到,其位于depth=1的左下角的节点,其value=[0, 49, 5]、samples=54,所以可以得到预测分类的概率为49/54=0.97,与以下计算输出是相同的;
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
iris = load_iris()
x = iris.data[:,2:]
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=12)
tree_clf.fit(x, y)
r = export_graphviz(tree_clf,
out_file='iris_tree.dot',
feature_names= iris.feature_names[2:],
class_names= iris.target_names,
rounded=True,
filled=True
)
print(tree_clf.predict_proba([[5, 1]]))
print(tree_clf.predict([[5, 1]]))
# [[0. 0.90740741 0.09259259]]
# [1]
四、决策树决策特征和条件的选择
Scikit-Learn使用CART(分类和回归树,Classfication and Regression Tree)算法训练决策树,此算法基于基尼不纯度来衡量决策系统的纯度;决策树从本质上来说,就是要通过不同决策节点的分拣,尽最大的可能减少系统的不纯程度,或者说尽快的最大程度的增加决策时通的纯度;
对于某个特征k及其阈值tk,基于其分裂的两个子节点,分别计算基尼不纯度并进行线性加和,并最小化这个相对子节点的基尼不纯度;
\[G^{'}(k,t_{k}) = \frac{m_{left}}{m} G_{left} + \frac{m_{right}}{m} G_{right} \]一旦CART算法成功地将训练集分为两部分,它就会使用相同的逻辑将子集进行分割,然后再分割子集,以此类推。一旦达到最大深度(由超参数max_depth定义),或者找不到可减少不纯度的分割,它将停止递归。其他一些超参数(稍后描述)可以控制其他一些停止条件(min_samples_split、min_samples_leaf、min_weight_fraction_leaf和max_leaf_nodes)。
五、决策树计算复杂度
对新样本进行预测需要从根节点开始遍历决策树,由于每个节点仅仅需要检测节点对应的一个特征值,只跟决策时的层数有关,而与样本的维度数量没有关系,故时间复杂度为,其中m为训练样本的数量
\[O(log_{2}(m)) \]训练算法需要比较每个节点上所有样本上的所有特征(如果设置了max_features,则更少)。比较每个节点上所有样本的所有特征会导致训练复杂度为O(n×m log2(m))。对于小训练集(少于几千个实例),Scikit-Learn可以通过对数据进行预排序(设置presort=True)来加快训练速度,但是这样做会大大降低大训练集的训练速度。
六、避免决策树过拟合
决策树基本上对训练数据没有任何的预先假设(比如线性模型就正好相反,它显然假设数据是线性的)。如果不加以限制,树的结构将跟随训练集变化,严密拟合,并且很可能过拟合;为避免过拟合,需要在训练过程中降低决策树的自由度;DecisionTreeClassifier类除了max_depth参数外,同样可以通过min_samples_split(分裂前节点必须有的最小样本数)、min_samples_leaf(叶节点必须有的最小样本数量)、min_weight_fraction_leaf(与min_samples_leaf一样,但表现为加权实例总数的占比)、max_leaf_nodes(最大叶节点数量),以及max_features(分裂每个节点评估的最大特征数量)来限制决策树的形状;
标签:iris,max,样本,tree,算法,节点,决策树 来源: https://www.cnblogs.com/wufengtinghai/p/15974423.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。